为什么估计(Estimate)
在概率,统计学中,要观测的数据往往是很大的,(比如统计全国身高情况)我们几乎不可能去统计如此之多的值。这时候,就需要用到估计了。我们先抽取样本,然后通过统计样本的情况,去估计总体。下面是数学中常用到的术语:
- 总体(Populantion)。通常它均值(mean)用 μ 表示。方差用
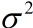 表示
表示 - 样本(Sample)。通常它的均值用
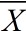 表示,方差用
表示,方差用 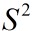 表示。(另外提一句,求
表示。(另外提一句,求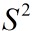 时,通常用n-1为底。这样是想让结果跟接近总体的方差,又称为无偏估计)
时,通常用n-1为底。这样是想让结果跟接近总体的方差,又称为无偏估计)
矩估计法(Moment Estimation)
原点矩
原点矩这个术语是数学家定义出来的,用于计算方便。所以在”使用”这个level上,我们先不要纠结它怎么来的,为什么叫原点矩。
来自wiki的定义:原点矩是一类随机变量的矩.随机变量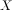 的n阶原点矩
的n阶原点矩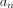 定义为
定义为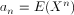
根据定义,我们可知:
一阶原点矩为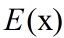
二阶原点矩为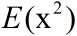
这两个是我们比较常用的,应为我们要估计的参数个数一般不多于二(多于2就不好算了)矩估计的原理
①样本与总体的原点矩是近似的。可以通过让它们相等来计算
②对于连续型随机变量:期望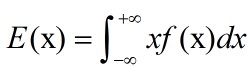 ; 方差
; 方差 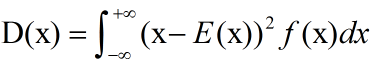
③对于给予的样本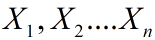 :期望
:期望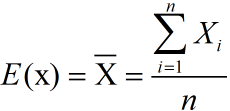 ; 方差
; 方差 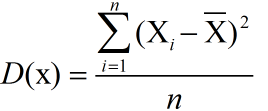 ,切记这里的
,切记这里的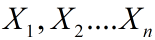 都是已知的
都是已知的
④对于各种随机变量x都有: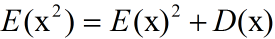
计算步骤
- 根据题目给出的概率密度函数,计算总体的原点矩(如果只有一个参数只要计算一阶原点矩,如果有两个参数要计算一阶和二阶)。由于有参数这里得到的都是带有参数的式子。如果题目给的是某一个常见的分布,就直接列出相应的原点矩E(x)
- 根据题目给出的样本。按照计算样本的原点矩(计算方法在上文都有给出)
- 让总体的原点矩与样本的原点矩相等,解出参数。所得结果即为参数的矩估计值
例题
i. 已知 是样本,求 是样本,求 矩估计 矩估计解:   总体一阶 <— 样本一阶   (总体的二阶) (总体的二阶)样本的二阶:   (二阶中心矩) (二阶中心矩)  |
|---|
ii. 已知 ,求λ的矩估计 ,求λ的矩估计解:  一阶 (常用一阶) 一阶 (常用一阶) 二阶 二阶当出现两个未知参数时,利用两种求  的方法(二元二次方程) 的方法(二元二次方程) |
|---|
**
iii. X服从 均匀分布, 均匀分布, ,求 ,求 矩估计 矩估计解:  , ,  , ,   (二阶矩用 (二阶矩用 来近似)= 来近似)=  解方程 |
|---|
最大似然估计(Maximum Likelihood Estimation, MLE)
基础概念:概率密度函数
概率密度函数是描绘 随机变量 的函数。我们先讲讲随机变量。随机变量的“变量”这个词用得有点让人误解。跟一般我们理解的变量不同,它代表了某种映射关系(将随机过程映射到数字),所以我们一般用大写的X,Y,Z来表示。我们最好把随机变量当作函数来看。
简单的讲,概率密度函数表示的就是随机变量X在某点的概率(所有点的概率和为1)。对于连续型的随机变量,其图像通常为一个连续的曲线,离散型的随机变量的图像一般是一个一个点组成。
似然函数(Likelihood Function)
来自wiki的定义:似然函数是一种关于统计模型中的参数的函数,表示模型参数中的似然性。“似然性”与“或然性”或“概率”意思相近,都是指某种事件发生的可能性,但是在统计学中,“似然性”和“或然性”或“概率”又有明确的区分。概率用于在已知一些参数的情况下,预测接下来的观测所得到的结果,而似然性则是用于在已知某些观测所得到的结果时,对有关事物的性质的参数进行估计。这里类似于“贝叶斯方法”的思路。
在估计中,我们已经取得一些样本数据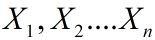 (它们是独立,同分布)。它们发生的概率即为为
(它们是独立,同分布)。它们发生的概率即为为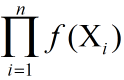 ,由于f(x)中有参数未知,所以我们得到的是一个关于参数的函数。我们把这个函数就当作似然函数。直观的讲,这些样本数据
,由于f(x)中有参数未知,所以我们得到的是一个关于参数的函数。我们把这个函数就当作似然函数。直观的讲,这些样本数据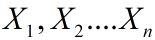 已经出现了,所以他们同时发生的概率(即似然函数)取最大值的时候最符合对事实的估计。
已经出现了,所以他们同时发生的概率(即似然函数)取最大值的时候最符合对事实的估计。
通过使似然函数取最大值,就可以估算参数。
计算步骤
- 根据对应概率密度函数计算出似然函数L(x)=
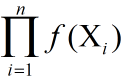
- 对似然函数L(x)取对数以方便求解。(由于对数函数是单调增函数,所以对似然函数取log后,与L(x)有相同的最大值点。)
- 根据参数,对第二步所得的函数求导。如果有多个参数,则分别求偏导。
- 令导数等于0(此时L(x)取到最大值).求出参数。此时所得结果即为参数的最大似然估计值。
与矩法估计比较,最大似然估计的精确度较高,信息损失较少,但计算量较大。


若有收获,就点个赞吧
0 人点赞
