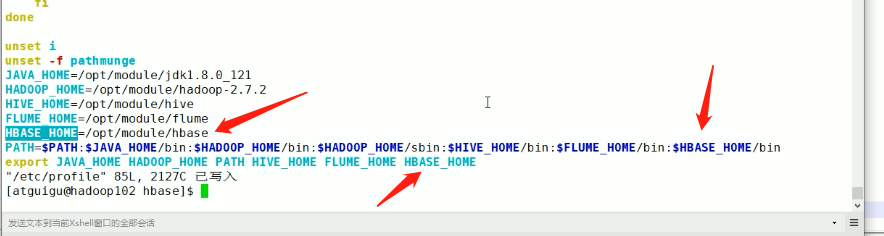
给bin目录配置到环境变量里面
不然的话每次使用HBase命令都得去HBase的bin目录下面去操作.
注意事项
1.在hbase shell中不要敲 ;,如果敲了;,需要敲两个 单引号结束!
- 在hbase shell中如果需要使用上下方向键查找历史命令,需要查看xshell的设置配置图!
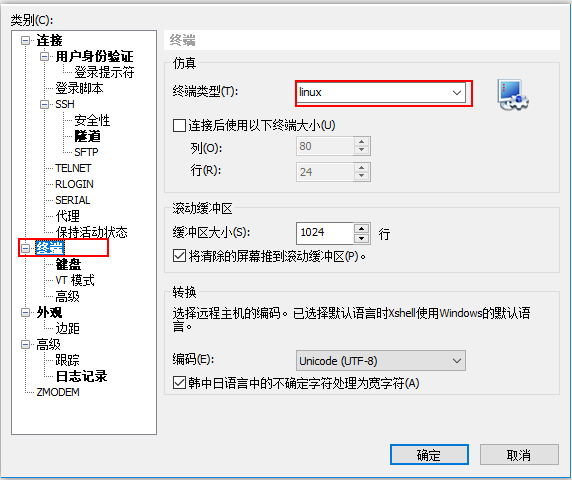
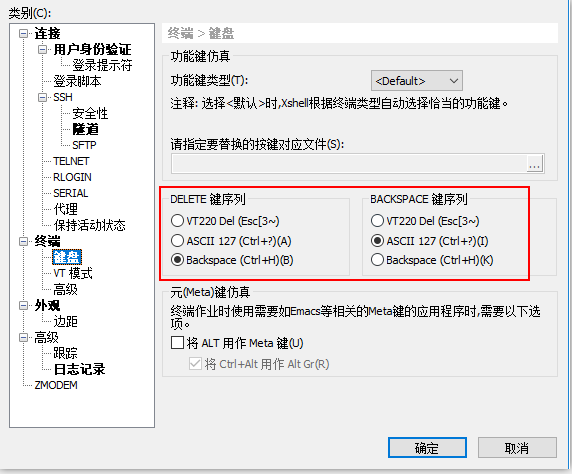
设置完了需要关闭当前终端重新连接.
- 查看帮助
help: 查看所有命令的帮助
help ‘命令’: 查看某个命令的帮助
help ‘组名’ : 查看某组命令的帮助
hbase shell使用ruby编写,不支持中文!
其它命令
进入shell界面和退出
使用hbase shell可以进入一个shell命令行界面
在bin目录下面
sh hbase shell
exit 命令就是退出功能.
查看集群状态
使用status可以查看集群状态,默认为summary,可以选择‘simple’和‘detailed’来查看详情。
hbase(main):011:0> status1 active master, 0 backup masters, 3 servers, 0 dead, 0.6667 average load
查看版本
hbase(main):002:0> version1.3.1, r930b9a55528fe45d8edce7af42fef2d35e77677a, Thu Apr 6 19:36:54 PDT 2017
查看操作用户及组信息
hbase(main):003:0> whoamiatguigu (auth:SIMPLE)groups: atguigu
查看表操作信息
hbase(main):004:0> table_helpHelp for table-reference commands.
查看帮助信息
hbase(main):005:0> helpHBase Shell, version 1.3.1, r930b9a55528fe45d8edce7af42fef2d35e77677a, Thu Apr 6 19:36:54 PDT 2017Type 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command.Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group.
查看具体命令的帮助
hbase(main):006:0> help 'get'Get row or cell contents; pass table name, row, and optionallya dictionary of column(s), timestamp, timerange and versions. Examples:
hbase> get ‘ns1:t1’, ‘r1’
注意引号是必须的!
库的操作
创建数据库
create_namespace 'ns1'
查看所有的数据库
list_namespace
修改库
alter_namespace
查看指定的库下面的表
查看 ns1 库下面的所有的表
list_namespace_tables 'ns1'
删除指定数据库
drop_namespace 'ns1;
表的操作
list
hbase(main):008:0> listTABLE0 row(s) in 0.0410 seconds
list后可以使用*等通配符来进行表的过滤!
建表create
创建表时,需要指定表名和列族名,而且至少需要指定一个列族,没有列族的表是没有任何意义的。
创建表时,还可以指定表的属性,表的属性需要指定在列族上!
格式:
create ‘表名’, { NAME => ‘列族名1’, 属性名 => 属性值}, {NAME => ‘列族名2’, 属性名 => 属性值}, …
如果你只需要创建列族,而不需要定义列族属性,那么可以采用以下快捷写法:
create’表名’,’列族名1’ ,’列族名2’, …
create 'ns1:t1','cf1','cf2' -- 在ns1库里面创建一个t1的表,t1表里面有cf1和cf2两个列族create 't1','cf1','cf2' -- 这种情况是建在默认的库里面的.
查看表的详细信息describe
查看ns1库下面的 t1表
describe ‘ns1:t1’
里面有具体的表的列族的信息等等.
hbase(main):007:0> describe 'ns1:t1'Table ns1:t1 is ENABLEDns1:t1COLUMN FAMILIES DESCRIPTION{NAME => 'cf1', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}{NAME => 'cf2', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}2 row(s) in 0.2540 seconds
desc
hbase(main):003:0> describe 'person'hbase(main):004:0> desc 'person'
启用禁用表
判断是否是启用状态is_enabled
当前表只有是启用状态的时候我才能往表里面进行写操作.
比如说我想给这个表里面增加列族,在增加列族的时候我不希望客户端在这个时候往表里面写数据的,那么我就可以给表改为禁用状态.
hbase(main):011:0> is_enabled 'ns1:t1'true0 row(s) in 0.0160 seconds
启用表enable
enable 'ns1:t1'
判断是否是禁用状态is_disabled
hbase(main):012:0> is_disabled 'ns1:t1'false0 row(s) in 0.0260 seconds
禁用表disable
停用表后,可以防止在对表做一些维护时,客户端依然可以持续写入数据到表。一般在删除表前,必须停用表。
在对表中的列族进行修改时,也需要停用表。
disable
disable_all ‘正则表达式’ 可以使用正则来匹配表名。
查看表是否存在exists
查看 ns1库下的t1表是否存在.
hbase(main):008:0> exists 'ns1:t1'Table ns1:t1 does exist0 row(s) in 0.0330 seconds
查看表的count
hbase(main):056:0> count 'ns1:t1'0 row(s) in 0.0790 seconds=> 0
清空表truncate
hbase(main):057:0> truncate 'ns1:t1'Truncating 'ns1:t1' table (it may take a while):- Disabling table...- Truncating table...0 row(s) in 5.5050 seconds
查看表的region数量 get_split
hbase(main):058:0> get_splits 'ns1:t1'Total number of splits = 1=> []
查看这个表切分了几个region个数.每个表在一开始只有一个region,之后记录增多后,region会被自动拆分。
修改表alter
alter命令可以修改表的属性,通常是修改某个列族的属性(添加,修改列族)
alter ‘表名’, ‘delete’ => ‘列族名’
给t1表增加一个名字为f3的region
需要注意的是关键字是严格大小写的,比如说NAME,必须是大写.
hbase(main):059:0> alter 'ns1:t1',{NAME => 'f3'}Updating all regions with the new schema...0/1 regions updated.1/1 regions updated.Done.0 row(s) in 2.9870 secondshbase(main):060:0>
删除表drop
删除表前,需要先disable表,否则会报错。ERROR: Table xxx is enabled. Disable it first.
hbase(main):011:0> drop 'ns1:t1'
数据操作
插入数据put
put可以新增记录还可以为记录设置属性。
如果这条记录不存在话,就是insert操作,如果这条记录存在了就是update操作
put ‘表名’, ‘行键’, ‘列名’, ‘值’
put ‘表名’, ‘行键’, ‘列名’, ‘值’,时间戳
put ‘表名’, ‘行键’, ‘列名’, ‘值’, { ‘属性名’ => ‘属性值’}
put ‘表名’, ‘行键’, ‘列名’, ‘值’,时间戳, { ‘属性名’ =>’属性值’}
HBase(main):012:0> put 'ns1:t1','1001','cf1:name','Nick' -- ns1:t1是数据库和表名 1001是行名 cf1 是列族名 name是值 ,Nick是valueHBase(main):003:0> put 'ns1:t1','1001','cf1:sex','male'HBase(main):004:0> put 'ns1:t1','1001','cf1:age','18'HBase(main):005:0> put 'ns1:t1','1002','cf1:name','Janna'HBase(main):006:0> put 'ns1:t1','1002','cf1:sex','female'HBase(main):007:0> put 'ns1:t1','1002','cf1:age','20'
查询多行scan
scan命令可以按照rowkey的字典顺序来遍历指定的表的数据。
scan ‘表名’:默认当前表的所有列族。 列子 scan ‘ns1:t1’
scan ‘表名’,{COLUMNS=> [‘列族:列名’],…} : 遍历表的指定列 ,列子: scan ‘ns1:t1’,{COLUMNS=> [‘cf1:name’]}
scan ‘表名’, { STARTROW => ‘起始行键’, ENDROW => ‘结束行键’ }:指定rowkey范围。如果不指定,则会从表的开头一直显示到表的结尾。区间为左闭右开。
scan ‘表名’, { LIMIT => 行数量}: 指定返回的行的数量
scan ‘表名’, {VERSIONS => 版本数}:返回cell的多个版本
scan ‘表名’, { TIMERANGE => [最小时间戳, 最大时间戳]}:指定时间戳范围
注意:此区间是一个左闭右开的区间,因此返回的结果包含最小时间戳的记录,但是不包含最大时间戳记录
scan ‘表名’, { RAW => true, VERSIONS => 版本数} 列子: scan ‘ns1:t1’, { RAW => true, VERSIONS => 10}
显示原始单元格记录,在Hbase中,被删掉的记录在HBase被删除掉的记录并不会立即从磁盘上清除,而是先被打上墓碑标记,然后等待下次major compaction的时候再被删除掉。注意RAW参数必须和VERSIONS一起使用,但是不能和COLUMNS参数一起使用。
scan ‘表名’, { FILTER => “过滤器”} and|or { FILTER => “过滤器”}: 使用过滤器扫描
HBase(main):008:0> scan 'student'HBase(main):009:0> scan 'student',{STARTROW => '1001', STOPROW => '1001'}HBase(main):010:0> scan 'student',{STARTROW => '1001'}
查询一行 get
get支持scan所支持的大部分属性,如COLUMNS,TIMERANGE,VERSIONS,FILTER
get命令其实就是特殊的scan命令
hbase(main):067:0> get 'ns1:t1','1001' -- 查看 ns1库下的t1表的 1001 这行记录的值COLUMN CELLcf1:age timestamp=1605064629301, value=18cf1:name timestamp=1605064611164, value=Nickcf1:sex timestamp=1605064625041, value=male1 row(s) in 0.1460 seconds
查看指定的key的值
查看 ns1库下的t1表的 1001行的 cf1:name 的value值
hbase(main):068:0> get 'ns1:t1','1001','cf1:name'COLUMN CELLcf1:name timestamp=1605064611164, value=Nick1 row(s) in 0.0210 seconds
删除delete
delete ‘ns1:t1’ ,’1001’,’cf1:name’
删除某rowkey的全部数据:
HBase(main):016:0> deleteall 'ns1:t1','1001'
删除某rowkey的某一列数据:
hbase(main):001:0> delete 'ns1:t1' ,'1001','cf1:name'0 row(s) in 0.5590 seconds
删除操作底层原理是追加一条同样的记录,这条记录后面被标记 type=DeleteColumn,因为HDFS是不能修改的,只能是往里面追加数据, 你删除的时候是在HDFS里面追加一条记录.这条记录的时间戳是最新的,在查询的时候会把时间戳最新的记录查询出来,一看最新的这条记录是删除状态.那么就不显示了.
查看所有的状态的值:scan ‘ns1:t1’, { RAW => true, VERSIONS => 10}
下面 type=DeleteColumn 就是已经删除的标记..
hbase(main):002:0> scan 'ns1:t1', { RAW => true, VERSIONS => 10}ROW COLUMN+CELL1001 column=cf1:age, timestamp=1605064629301, value=181001 column=cf1:name, timestamp=1605072235409, type=DeleteColumn1001 column=cf1:name, timestamp=1605064930474, value=Nick21001 column=cf1:sex, timestamp=1605064625041, value=maler1 column=cf1:name, timestamp=1605064486595, value=Nick2 row(s) in 0.0480 seconds

若有收获,就点个赞吧
0 人点赞
