简述
在/hadoop-2.7.2/share/hadoop/mapreduce里面是官方提供的一些示例.
进入到/hadoop-2.7.2/share/hadoop/mapreduce目录下面
新建个hello 文件随便往里面写点东西,然后用回车换行多写几行东西,用来方便测试
执行命令
准备测试数据
[root@zjj102 demo]# vim helloskldjlkasjdzhjjzjjsada
准备执行wordcount程序
# 在HDFS上面创建wc目录[root@zjj102 demo]# hadoop fs -mkdir /wc# 上传hello文件到HDFS上面的wc目录下面[root@zjj102 demo]# hadoop fs -put hello /wc[root@zjj102 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordcount /wc /wcoutput
执行命令解读 命令: hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordcount /wc /wcoutput
wordcount 是一个类名,也是demo名字
/wc 意思是 HDFS的 /wc目录下面的文件,你可以创建个文件,里面随便写一些内容,然后上传到HDFS上的/wc目录下面.
/wcoutput 意思是当程序运算的结果输出到 /wcoutput 文件下
上面命令意思是 执行这个jar,指定程序是wordcount ,统计 Hadoop指定的存储程序里面的 /wc 目录 , 结果输出到/wcoutput 目录下.
上面执行原理是 你需要有个程序打成jar包,然后用命令去执行这个jar包,然后传递你要执行的主类名(wordcount就是主类名) , 然后hadoop自动解析你传递的类名,然后你传递一个输入的参数,和输出的参数.
查看执行结果
发现控制台多了个wcoutput目录 ,下面_SUCCESS里面没用内容,只是告诉程序员程序执行成功了,而执行结果在下面的的文件里面
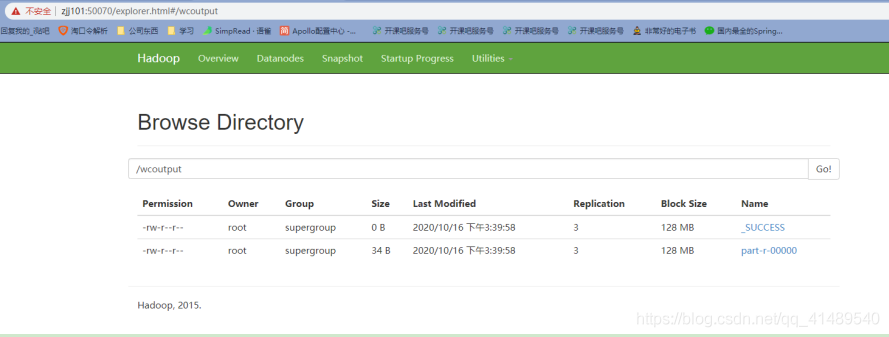
控制台查看这个文件内容就能查看到结果了.
shell:
[root@zjj102 mapreduce]# hadoop fs -cat /wcoutput/part-r-00000sada 1skldjlkasjd 1zhjj 1zjj 1

若有收获,就点个赞吧
0 人点赞
