需求
实时监控Springboot项目日志内容,将内容写入到HDFS
前置条件
需要有 Hadoop HDFS Flume Zookeeper
分析
tail -f 命令可以实时监控文件,将监控到的信息封装成event存到channel里面,然后再用sink写到hdfs上.
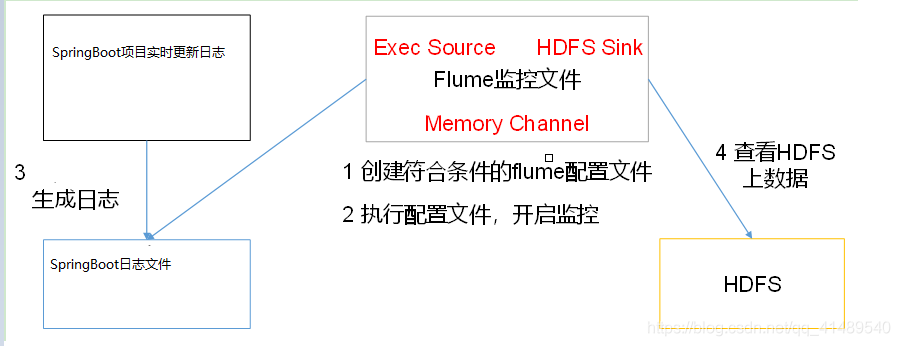
组件选择
因为数据源需要运行一个Linux命令,所有需要使用EXECSource
EXECSource
介绍: execsource会在agent启动时,运行一个linux命令,运行linux命令的进程要求是一个可以持续产生数据的进程,将标准输出的数据封装为event. 标准输出的错谁信息是不会被记录的,除非你设置了参数logStdErr参数设置为true.
通常情况下,如果指定的命令进程退出了,那么source也会退出并且不会再封装任何的数据.
所以使用这个source一般推荐类似cat ,tail -f 这种命令,因为cat,tail-f 命令会产生一个数据流,而不是date这种只会返回一个数据,并且执行完就退出的命令.
HDFSSink
介绍: hdfssink将event写入到HDFS.目前只支持生成text 和sequenceFile两种类型的文件,这两种文件都可以使用压缩.
写入到HDFS的文件可以自动滚动(关闭当前正在写的文件,创建一个新文件)。可以基于时间、events的数量、数据大小(比如说每写128M就滚动一次)进行周期性的滚动.
支持基于时间和采集数据的机器进行分桶和分区操作.(分桶和分区是hive的东西了)
HDFS数据所上传的目录或文件名可以包含一个格式化的转义序列,这个路径或文件名会在上传event时,被自动替换,替换为完整的路径名.
编写agent配置文件
#a1是agent的名称,a1中定义了一个叫r1的source,如果有多个,使用空格间隔a1.sources = r1a1.sinks = k1a1.channels = c1#组名名.属性名=属性值a1.sources.r1.type=exec# 监控这个日志文件的数据,如果有新的数据就追加写a1.sources.r1.command=tail -f /root/soft/test.log#定义chanela1.channels.c1.type=memorya1.channels.c1.capacity=1000#定义sinka1.sinks.k1.type = hdfs# 上传到hdfs的路径,路径是完整的URL协议,%Y%m%d/%H/%M是转义序列,在上传到hdfs的时候这些转义序列会变成具体的值.如果有转义序列的话,那么就要求event的header中必须有timestamp=时间戳,如果没有需要将useLocalTimeStamp = truea1.sinks.k1.hdfs.path = hdfs://zjj101:9000/flume/%Y%m%d/%H/%M#上传文件的前缀a1.sinks.k1.hdfs.filePrefix = logs-# --------------------------------#以下三个和目录的滚动相关,目录一旦设置了时间转义序列,基于时间戳滚动#是否将时间戳向下舍(四舍五入),只能舍不能入a1.sinks.k1.hdfs.round = true#上面配置了时间戳舍弃,你是按几个小时舍弃还是几个分钟舍弃,还是多少秒舍弃?? 取决于roundValue 和roundUnit# 多少时间单位创建一个新的文件夹a1.sinks.k1.hdfs.roundValue = 1#重新定义时间单位,可以写 小时或者分钟(minute) 或者秒a1.sinks.k1.hdfs.roundUnit = minute# --------------------------------#是否使用本地时间戳a1.sinks.k1.hdfs.useLocalTimeStamp = true#积攒多少个Event才flush到HDFS一次# sink是去channel里面拿数据,然后写到DHFS上面,sink是拿一批写一次,一批拿多少个,由batchSize 这个值控制, 如果你想让Sink写数据写快一点的话,就给这个值改大一些.但是改大了就吃内存,具体的需要自己取舍.a1.sinks.k1.hdfs.batchSize = 100#以下三个和文件的滚动相关,以下三个参数是”或者的关系”的关系,只要满足下面三个配置的其中一种就开始滚动,以下三个参数如果值为0都代表禁用(不配置的话不代表禁用,因为它们都有自己的默认值)#60秒滚动生成一个新的文件a1.sinks.k1.hdfs.rollInterval = 10#设置每个文件到128M时滚动a1.sinks.k1.hdfs.rollSize = 134217700#每写多少个event滚动一次a1.sinks.k1.hdfs.rollCount = 0#连接组件 同一个source可以对接多个channel,一个sink只能从一个channel拿数据!a1.sources.r1.channels=c1a1.sinks.k1.channel=c1
运行
Flume启动
启动命令
注意 —name 写agent名字
—conf-file 写agent配置文件地址, 不要写错了
flume-ng agent --conf conf/ --name a1 --conf-file /root/soft/apache-flume-1.7.0/conf/job/demo2.conf
运行完了之后会在控制台打印一堆内容,这个不用管…只要没有error级别就行.
执行SpringBoot项目
随便找个SpringBoot项目打成一个jar包.. 然后放到/root/soft目录下面
启动这个jar 包
在root/soft 目录下面
[root@zjj101 soft]# nohup java -jar demo.jar >test.log 2>&1 &
上面命令是后台启动demo.jar ,然后将日志文件输出到test.log中, 这个这个log正是flume监控的log日志.
观察Flume的日志信息
显示 创建了hdfs://zjj101:9000/flume/20201023/15/40/logs-.1603438823100.tmp文件
说明读取到log日志的内容了
20/10/23 15:40:23 INFO hdfs.BucketWriter: Creating hdfs://zjj101:9000/flume/20201023/15/40/logs-.1603438823100.tmp20/10/23 15:40:33 INFO hdfs.BucketWriter: Closing hdfs://zjj101:9000/flume/20201023/15/40/logs-.1603438823100.tmp20/10/23 15:40:33 INFO hdfs.BucketWriter: Renaming hdfs://zjj101:9000/flume/20201023/15/40/logs-.1603438823100.tmp to hdfs://zjj101:9000/flume/20201023/15/40/logs-.160343882310020/10/23 15:40:33 INFO hdfs.HDFSEventSink: Writer callback called.20/10/23 15:40:36 INFO hdfs.HDFSSequenceFile: writeFormat = Writable, UseRawLocalFileSystem = false20/10/23 15:40:36 INFO hdfs.BucketWriter: Creating hdfs://zjj101:9000/flume/20201023/15/40/logs-.1603438836611.tmp20/10/23 15:40:46 INFO hdfs.BucketWriter: Closing hdfs://zjj101:9000/flume/20201023/15/40/logs-.1603438836611.tmp20/10/23 15:40:46 INFO hdfs.BucketWriter: Renaming hdfs://zjj101:9000/flume/20201023/15/40/logs-.1603438836611.tmp to hdfs://zjj101:9000/flume/20201023/15/40/logs-.160343883661120/10/23 15:40:46 INFO hdfs.HDFSEventSink: Writer callback called.
观察hdfs的控制面板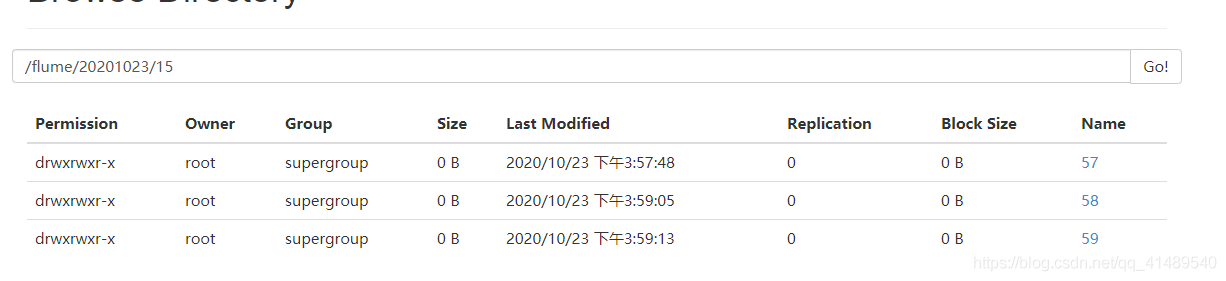
发现里面已经有东西上传到hdfs里面了

若有收获,就点个赞吧
0 人点赞
