基本
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U
说明:
zeroValue是初始值
seqOp是分区内计算规则
combOp是分区间计算规则
zeroValue 分区内聚合和分区间聚合的时候各会使用一次.
aggregate函数将每个分区里面的元素通过分区内的逻辑和初始值进行聚合,然后用分区间逻辑和初始值进行操作.
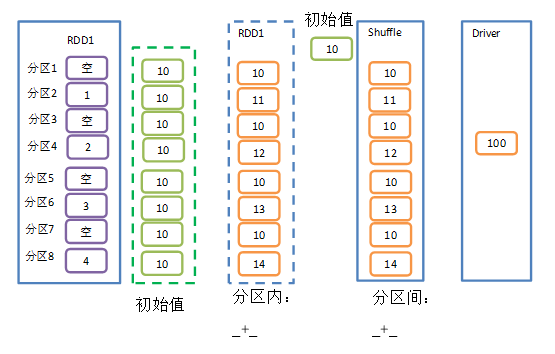
val rdd: RDD[Int] = sparkContext.makeRDD(List(1,2,3,4),8)val res: Int = rdd.aggregate(0)(_+_,_+_)//10println(res) //输出: 10
假设设置8个分区,上面只有4个数据,那么八个分区就有用四个分区没有值,然后对rdd元素进行聚合,初始值是0,那么用0和分区内数据依次进行累加.那么四个分区就是1,2,3,4 ,分区间还累加,初始值还是0.那么累加之后结果还是1,2,3,4,结果就是10了.
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),8)
val res: Int = rdd.aggregate(1)(_+_,_+_)
println(res) //输出: 19
为什么这里得19,因为分区内运算:8个分区,每个分区初始值为1, 1,2,3,4 这四个值会均匀分布到8个分区,那么结果可能就是每个分区的值是2,3,4,5,1,1,1,1 这八个分区内运算后的值是18了.
然后分区间运算初始值是1, 18+1 就是19
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),8)
val res: Int = rdd.aggregate(2)(_+_,_+_)
println(res) //输出: 28
这里为什么得28,因为分区内运算是八个分区,初始值为2,元数据1,2,3,4分布到8个分区,那么八个分区的值就是3,4,5,6,2,2,2,2, ,这八个分区内运算后的值是26 ,然后分区间运算初始值是2 , 26+2结果就是28了.
aggregate和aggregateByKey区别
aggregate可以针对单个值, aggregateByKey 是针对键值对来使用的,aggregateByKey 在分区间计算的话初始值是不参与计算的,但是aggregate的初始值是参与分区间计算的.

若有收获,就点个赞吧
0 人点赞
