由于Hbase依赖HDFS存储,HDFS只支持追加写。所以,当新增一个单元格的时候,HBase在HDFS上新增一条数据。当修改一个单元格的时候,HBase在HDFS又新增一条数据,只是版本号比之前那个大(或者自定义)。当删除一个单元格的时候,HBase还是新增一条数据!只是这条数据没有value,类型为DELETE,也称为墓碑标记(Tombstone)
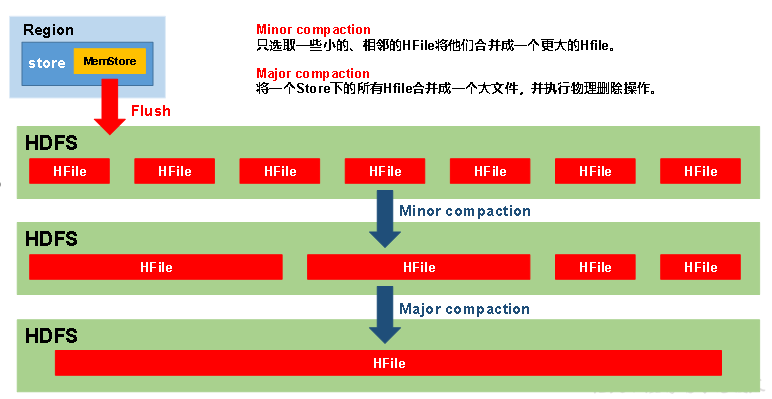
HBase每间隔一段时间都会进行一次合并(Compaction),合并的对象为HFile文件。合并分为两种
minor compaction和major compaction。
在HBase进行major compaction的时候,它会把多个HFile合并成1个HFile,在这个过程中,一旦检测到有被打上墓碑标记的记录,在合并的过程中就忽略这条记录。这样在新产生的HFile中,就没有这条记录了,自然也就相当于被真正地删除了
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFile Compaction。
再者说小文件都是存在HDFS上的,如果小文件过多的话会使得NameNode的服务能力下降.
Compaction分为两种,分别是Minor Compaction和Major Compaction。Minor Compaction会将临近的若干个较小的HFile合并成一个较大的HFile,但不会清理过期和删除的数据(有异议,)。Major Compaction会将一个Store下的所有的HFile合并成一个大HFile,并且会清理掉过期和删除的数据。
相关配置参数
--------------------------------Compact--------------------------------<!-- 一个region进行 major compaction合并的周期,在这个点的时候, 这个region下的所有hfile会进行合并,默认是7天,但是时间是不固定的,有0.5的摇摆范围.可能3.5天就触发,如果正执行高并发的操作,忽然HBase启动了major compaction操作.那么会影响系统性能(IO压力很大,写入非常慢). ,major compaction非常耗资源,建议生产关闭(设置为0),在应用空闲时间手动触发(比如说每天夜里一两点不是很忙了,那么可以写个定时脚本来触发一下) --><property><name>hbase.hregion.majorcompaction</name><value>604800000</value><description>The time (in miliseconds) between 'major' compactions ofallHStoreFiles in a region. Default: Set to 7 days. Major compactions tend tohappen exactly when you need them least so enable them such that theyrun atoff-peak for your deploy; or, since this setting is on a periodicity that isunlikely to match your loading, run the compactions via an externalinvocation out of a cron job or some such.</description></property><!-- 一个store里面允许存的hfile的个数,超过这个个数会被写到新的一个hfile里面 也即是每个region的每个列族对应的memstore在fulsh为hfile的时候,默认情况下当超过3个hfile的时候就会对这些文件进行合并重写为一个新文件,设置个数越大可以减少触发合并的时间,但是每次合并的时间就会越长 --><property><name>hbase.hstore.compactionThreshold</name><value>3</value><description>If more than this number of HStoreFiles in any one HStore(one HStoreFile is written per flush of memstore) then a compactionis run to rewrite all HStoreFiles files as one. Larger numbersput off compaction but when it runs, it takes longer to complete.</description></property><!-- 每个minor compaction操作的 允许的最大hfile文件上限 --><property><name>hbase.hstore.compaction.max</name><value>10</value><description>Max number of HStoreFiles to compact per 'minor'compaction.</description></property>--------------------------------Flush--------------------------------<!-- regionServer的全局memstore的大小,超过该大小会触发flush到磁盘的操作,默认是堆大小的40%,而且regionserver级别的flush会阻塞客户端读写 --><property><name>hbase.regionserver.global.memstore.size</name><value></value><description>Maximum size of all memstores in a region server beforenewupdates are blocked and flushes are forced. Defaults to 40% of heap (0.4).Updates are blocked and flushes are forced until size of allmemstoresin a region server hitshbase.regionserver.global.memstore.size.lower.limit.The default value in this configuration has been intentionally leftemtpy in order tohonor the old hbase.regionserver.global.memstore.upperLimit property ifpresent.</description></property><!--可以理解为一个安全的设置,有时候集群的“写负载”非常高,写入量一直超过flush的量,这时,我们就希望memstore不要超过一定的安全设置。在这种情况下,写操作就要被阻塞一直到memstore恢复到一个“可管理”的大小, 这个大小就是默认值是堆大小 * 0.4 * 0.95,也就是当regionserver级别的flush操作发送后,会阻塞客户端写,一直阻塞到整个regionserver级别的memstore的大小为 堆大小 * 0.4 *0.95为止 --><property><name>hbase.regionserver.global.memstore.size.lower.limit</name><value></value><description>Maximum size of all memstores in a region server beforeflushes are forced.Defaults to 95% of hbase.regionserver.global.memstore.size (0.95).A 100% value for this value causes the minimum possible flushing tooccur when updates areblocked due to memstore limiting.The default value in this configuration has been intentionally leftemtpy in order tohonor the old hbase.regionserver.global.memstore.lowerLimit property ifpresent.</description></property><!-- 内存中的文件在自动刷新之前能够存活的最长时间,默认是1h --><property><name>hbase.regionserver.optionalcacheflushinterval</name><value>3600000</value><description>Maximum amount of time an edit lives in memory before being automaticallyflushed.Default 1 hour. Set it to 0 to disable automatic flushing.</description></property><!-- 单个region里memstore的缓存大小,超过那么整个HRegion就会flush,默认128M --><property><name>hbase.hregion.memstore.flush.size</name><value>134217728</value><description>Memstore will be flushed to disk if size of the memstoreexceeds this number of bytes. Value is checked by a thread that runsevery hbase.server.thread.wakefrequency.</description></property>

若有收获,就点个赞吧
0 人点赞
