架构图
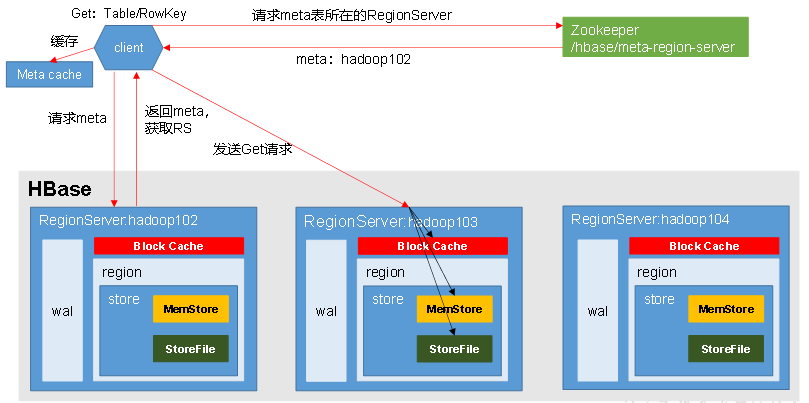
读流程
1)Client先访问zookeeper,获取hbase:meta这个系统表位于哪个Region Server,因为访问表需要RegionServer
2)访问对应的Region Server,获取hbase:meta系统表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
3)与目标Region Server进行通讯;
4)分别在Block Cache(读缓存),MemStore和Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete).
读取的数据存储在列族(storeFile)中!列族在HDFS上就是一个目录,这个目录下存储了很多文件(storefile)
数据如果是刚写入到store中,还没有刷写到磁盘,当前数据就存储在memstore中,
有可能这个列的历史版本的数据已经刷写到磁盘存在storefile中,
在扫描时,需要既扫memstore,又扫磁盘上的storefile,扫描出当前列的所有版本的数据,从这些
数据中挑选出时间戳最大的返回!
如果扫描历史版本的数据,是扫storefile,那么会发送磁盘IO,效率低,因此可以把扫描到的数据
所在的块(block)缓存到内存中,在内存中保存缓存块的区域,称为blockcache.
在以后的查询中,如果查询的数据在blockcache中有,那么就不需要再扫描storefile了!如果没有,
再扫描storefile,讲数据所在的block缓存到blockcache!
Blockcache在RegionServer中的读缓存,blockcache默认大小为当前RegionServer所在堆缓存的40%,有LRU的回收策略!
block不是HDFS上中的block,是HFile中的block(64k)!
5)将查询到的数据块(Block,HFile数据存储单元,默认大小为64KB)缓存到Block Cache。
6)将合并后的最终结果返回给客户端。 返回给客户端的数据一般都是时间戳最新的数据.(先把指定Key下的所有的行的数据都查询出的来再从中找最新的时间戳的一条返回回去)
get读流程
get t1,r1 :
扫描r1所在region的所有列族的memstore,从中找r1行的所有列的每个版本的最近数据
扫描r1所在region的所有列族的storefile,从中找r1行的所有列的每个版本的历史数据
将最近的数据和历史数据,汇总,挑选每个列最新的数据(时间戳最大的数据)
将刚刚扫描storefile数据所在的block,缓存到blockcache中
scan流程
scan t1 ,{STARTROW=>r1,STOPROW=>r4}: 扫描r1到r3行
扫描r1所在region的所有列族的memstore,从中找r1-r3行的所有列的每个版本的最近数据
扫描r1所在region的所有列族的storefile,从中找r2-r3行的所有列的每个版本的历史数据
从blockcache中扫描r1行所有的数据
将刚刚扫描storefile数据所在的block,缓存到blockcache中
put 流程
put t1,r1,cf1:name,jack: 当对数据作了修改时,此时blockcache中缓存就失效了!

若有收获,就点个赞吧
0 人点赞
