什么是spark-shell
Spark-shell 是 Spark 给我们提供的交互式命令窗口(类似于 Scala 的 REPL)
准备数据
新建个demo文件夹
在demo文件夹里面新建两个txt文件
里面的数据都是用空格分隔的, 不是用tab分隔的
[root@zjj101 soft]# cat demo1.txtzjj AAABBB AAAjj ZJJ[root@zjj101 soft]# cat demo2.txtZZZ zzzxxx yyyZjjzjj[root@zjj101 soft]#
执行sparkShell
在spark根目录下执行bin/spark-shell 命令
[root@zjj101 spark-2.1.1-bin-hadoop2.7]# bin/spark-shell
控制台输出结果
[root@zjj101 spark-2.1.1-bin-hadoop2.7]# bin/spark-shellUsing Spark's default log4j profile: org/apache/spark/log4j-defaults.propertiesSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).20/10/29 17:24:30 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable20/10/29 17:24:39 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.020/10/29 17:24:39 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException20/10/29 17:24:41 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException# web地址Spark context Web UI available at http://172.16.10.101:4040# 新建了个session,名字是sc , master类型是本地模式,指定cpu核心数资源是计算机的最大cpu内核.Spark context available as 'sc' (master = local[*], app id = local-1603963471476).Spark session available as 'spark'.Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 2.1.1/_/Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_201)Type in expressions to have them evaluated.Type :help for more information.
浏览器访问 http://172.16.10.101:4040 :
开始执行wordcount程序
在spark内部执行
scala> sc.textFile("../demo/").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).collectres0: Array[(String, Int)] = Array((zjj,2), (jj,1), (BBB,1), (xxx,1), (zzz,1), (Zjj,1), (ZZZ,1), (ZJJ,1), (yyy,1), (AAA,2))
发现已经做了单词统计
wordcount提交流程
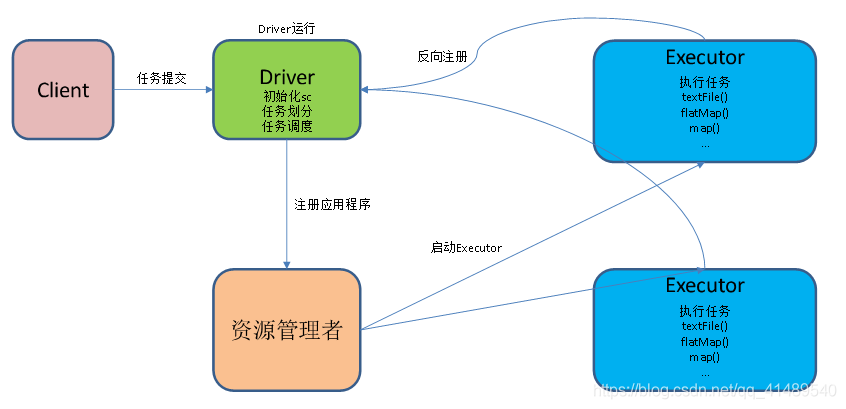
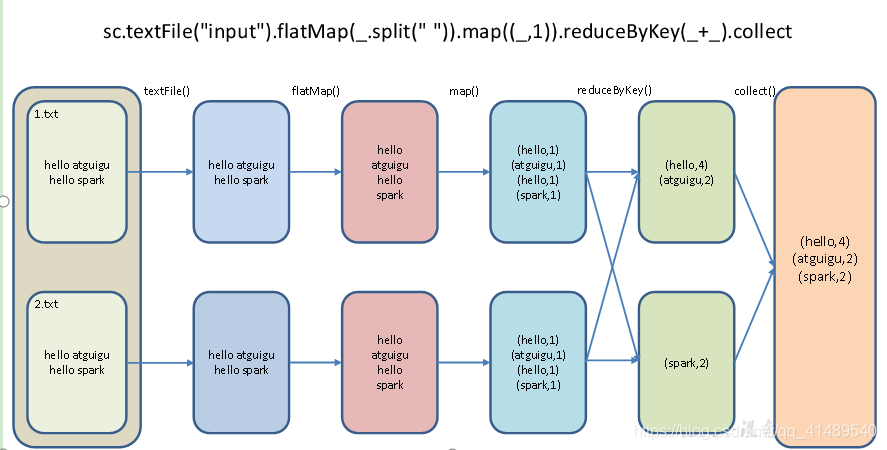
1.textFile(“input”):读取本地文件input文件夹数据;
2.flatMap(.split(“ “)):压平操作,按照空格分割符将一行数据映射成一个个单词;
3.map((,1)):对每一个元素操作,将单词映射为元组;
4.reduceByKey(+):按照key将值进行聚合,相加;
5.collect:将数据收集到Driver端展示.前面的所有的操作是懒加载,不会立即执行,调用collect之后就开始执行了.

若有收获,就点个赞吧
0 人点赞
