Flume事务概述
为什么要用Flume事务
我们都知道Flume是一个日志文件传输的工具,传输过程会经过三大步骤:
1.通过source 把数据从数据源(网络端口,本地磁盘等)读出出来2.通过source把数据传入到channel里面3.再把数据从channel传输到sink里面,sink把数据传给目的地(hdfs).
当然传输数据的过程并不是只有这三个步骤,flume 竟然是传输数据的,所以得考虑到数据传输时数据的完整性 . Flume在传输数据的时候很有可能因为传输速率的不一致导致channel满了,从而导致数据丢失。
channel是被动的,source这边是主动把数据put给channel,sink这边是主动把数据从channel拉取take,所以channel是被动操作的。
一般channel使用MemoryChannel,这是内存的,断电会丢失数据,也可以使用filechannel(磁盘),filechannel速度慢,但有提供日志级别的数据恢复功能,不过不断电MemoryChannel是不会丢数据的,所以一般选用memorychannel也OK。
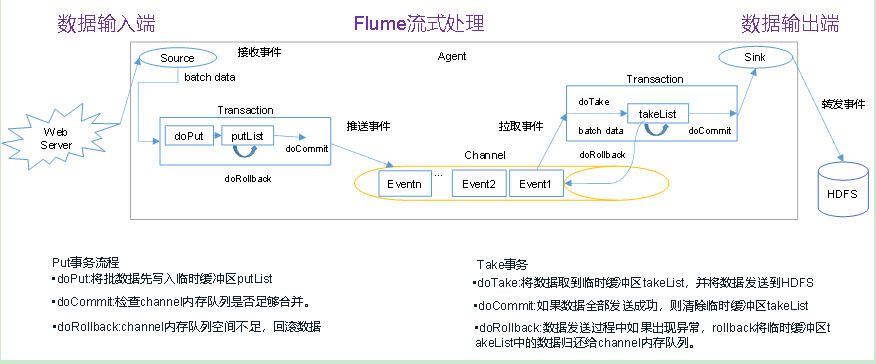
source把数据传给channel 时不是直接传给channel,中间还有put事务,当然从channel到sink也不是直接传过去的,中间还有take事务。
事务的局限性
事务只能保证 source->channel,channel->sink,这两个过程数据不丢,但是如果source 或者 sink 挂了事务就解决不了了
事务流程
Put事务流程
首先Source对接数据源对接之后封装成一个个Event对象,多个Event组成一个List集合,Source是一次放一批Event到Channel里面.
事务实现
为了保证事务, Source是不会直接给数据推送给Channel的,而是在Source和Channel之间有个缓冲,在源码里面叫PutList,
Source会把要推送给Channel的数据放到PutList容器里面,PutList集合也有容量的,PutList的Size容量大于等于的Source.
source将封装好的event,先放入到putList中,放入完成后,一次性commit(),这批event就可以写入到channel!
写入完成后,清空putList,开始下一批数据的写入!
假如一批event中的某些event在放入putList时,发生了异常,此时要执行rollback(),rollback()直接清空putList。
putList在初始化时,需要根据一个固定的size初始化,这个size在channel中设置.
在channel中,这个size由参数transactionCapacity决定.
put事务步骤
doput :先将批数据写入临时缓冲区putlist里面 docommit:去检查channel里面有没有空位置,如果有就传入数据,如果没有那么dorollback就把数据回滚到putlist里面。
Take事务
sink不断从channel中拉取event,没拉取一个event,这个event会先放入takeList中.
当一个batchSize的event全部拉取到takeList中之后,此时由sink执行写出处理.
假如在写出过程中,发送了异常,此时执行回滚!将takeList中所有的event全部回滚到channel.
反之,如果写出没有异常,执行commit(),清空takeList.
take事务步骤:
dotake:将数据读取到临时缓冲区takelist,并将数据传到hdfs上。 docommit :去判断数据发送是否成功,若成功那么清除临时缓冲区takelist 若不成功(比如hdfs系统服务器崩溃等)那么dorollback将数据回滚到channel里面。
Flume如何保证不丢数据
- 如果你用的不是异步Source,那么是不会丢数据,
2. 如果你用的是异步Source,那么你在Channel满了之后可以在客户端来缓存数据,那也不会丢数据
为什么只要不是异步Source就能保证不丢数据呢?
因为在Flume里面是有事务机制的,能保证数据不丢失.
Flume里面有两个事务,因为Source需要给Event存到Channel里面,而Sink需要从Channel里面来取Event,所以就各有一个事务,一个叫put事务,一个叫take事务.

若有收获,就点个赞吧
0 人点赞
