**
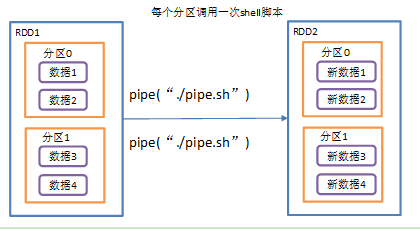
RDD针对每个分区,都调用一次shell脚本(也可以执行python脚本),返回输出的RDD,命令是一个分区执行一次.
脚本要放在 worker 节点可以访问到的位置
步骤1: 创建一个脚本文件_pipe.sh
文件内容如下:
echo "hello"while read line;doecho ">>>"$linedone
步骤2: 创建只有 1 个分区的_RDD
scala> rdd1.pipe("./pipe.sh").collectres1: Array[String] = Array(hello, >>>10, >>>20, >>>30, >>>40)
scala> val rdd1 = sc.parallelize(Array(10,20,30,40), 2)rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at parallelize at <console>:24# 这里可指定绝对路径scala> rdd1.pipe("./pipe.sh").collectres2: Array[String] = Array(hello, >>>10, >>>20, hello, >>>30, >>>40)

若有收获,就点个赞吧
0 人点赞
