简介
一个分区字段就是一级目录,如果是两个分区,就是两个分区目录,比如说 area province,那么目录就是 /area/province/xxxxxx ,数据都在xxxxxx这里.

创建表
二级分区使用方式就是在一级分区基础上 PARTITIONED BY后面多写个字段即可
create table order_multi_partition(order_no string,order_time string)PARTITIONED BY (event_timt string, step string)row format delimited fields terminated by '\t';
准备数据
order_created.txt
10703007267488 2014-05-01 06:01:12.334+0110101043505096 2014-05-01 07:28:12.342+0110103043509747 2014-05-01 07:50:12.33+0110103043501575 2014-05-01 09:27:12.33+0110104043514061 2014-05-01 09:03:12.324+01
导入数据
现在order_created.txt所在的目录在/root/soft
[root@zjj101 soft]# lsdata docker hadoop-2.7.2 hive-1.2.1 myconf order_created.txt tmp[root@zjj101 soft]# pwd/root/soft
使用load方式导入
sql:
load data local inpath '/root/soft/order_created.txt' into table order_multi_partitionPARTITION (event_timt = '2014-05-01', step = '1')
查看结果
sql
select *from order_multi_partitionwhere event_timt = '2014-05-01'and step = '1';
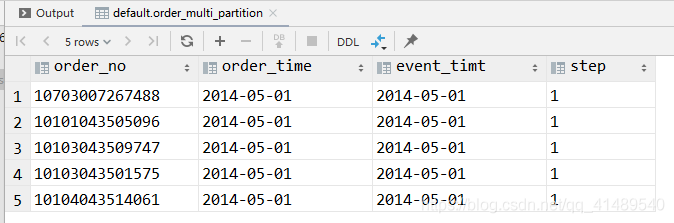
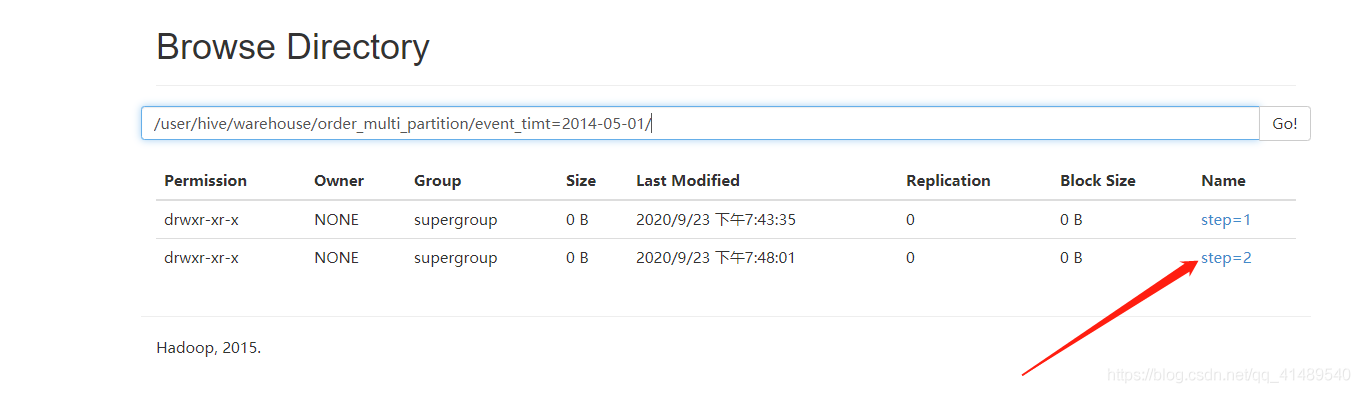
hdfs上面的数据
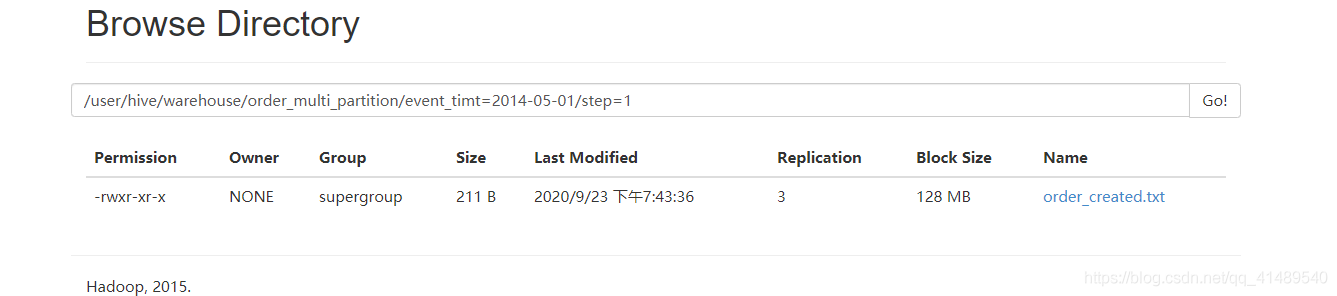
再次上传到另一个二级分区
上传前先查看一下有没有数据
select *from order_multi_partitionwhere event_timt = '2014-05-01'and step = '2';
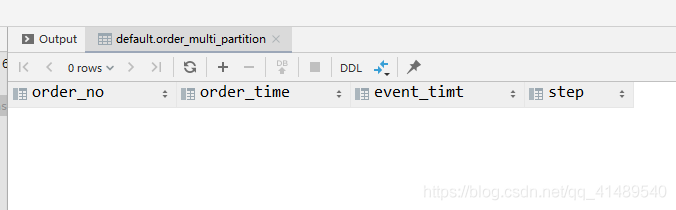
没有数据
将数据导入到step2分区
导入到(event_timt = ‘2014-05-01’, step = ‘2’)分区
sql:
load data local inpath '/root/soft/order_created.txt' into table order_multi_partitionPARTITION (event_timt = '2014-05-01', step = '2');
查看结果
sql:
select *from order_multi_partitionwhere event_timt = '2014-05-01'and step = '2';
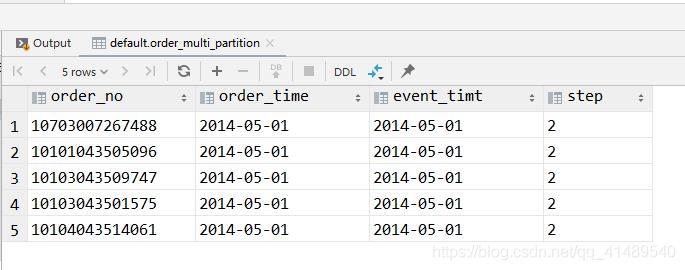
此时就有了

若有收获,就点个赞吧
0 人点赞
