使用场景
在生产上,一般对数据清洗之后直接放到HDFS上,然后再将目录加载到分区表中;
准备数据
order_created.txt
用 tab分割
10703007267488 2014-05-01 06:01:12.334+0110101043505096 2014-05-01 07:28:12.342+0110103043509747 2014-05-01 07:50:12.33+0110103043501575 2014-05-01 09:27:12.33+0110104043514061 2014-05-01 09:03:12.324+01
order_created.txt 存放位置
[root@zjj101 soft]# pwd/root/soft[root@zjj101 soft]# lsdata docker hadoop-2.7.2 hive-1.2.1 myconf order_created.txt tmp[root@zjj101 soft]#
在hdfs上创建准备放数据的目录
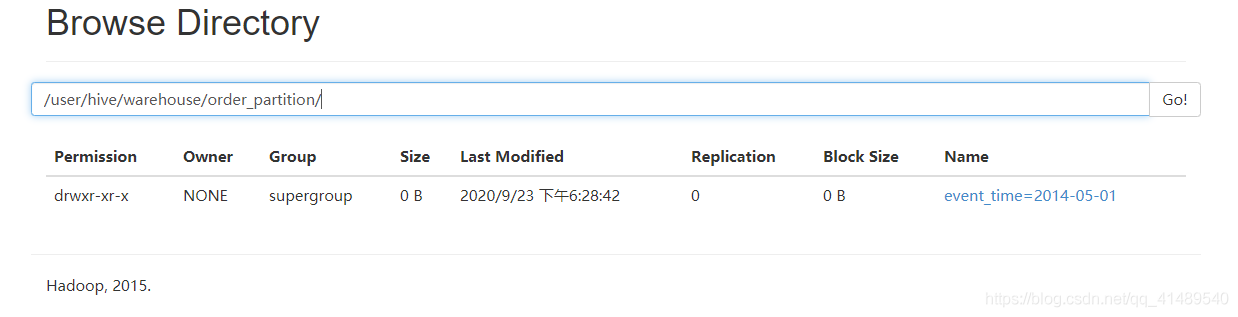
准备放到这里:
/user/hive/warehouse/order_partition/
shell
[root@zjj101 soft]# hadoop fs -mkdir /user/hive/warehouse/order_partition/event_time=2014-05-02[root@zjj101 soft]#
已经生成
将数据上传到hdfs上面
shell:
[root@zjj101 soft]# hadoop fs -put /root/soft/order_created.txt /user/hive/warehouse/order_partition/event_time=2014-05-02[root@zjj101 soft]#
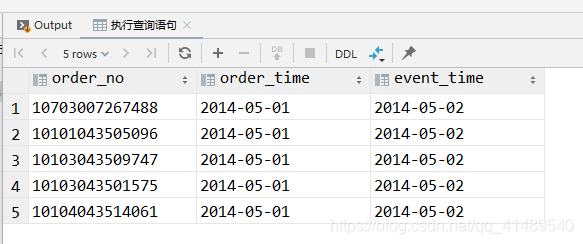
查看数据是否上传成功

此时查看已经有了
关联元数据再查询
sql
-- 刚刚给数据放到hdfs上面了,但是元数据没有,所有需要修复一下再执行查询语句,否则的话是查询不到的msck repair table order_partition;-- 执行查询语句select *from order_partitionwhere event_time = '2014-05-02';

若有收获,就点个赞吧
0 人点赞
