分布式数据存储
HBase定位是分布式NoSQL数据库,把自己的NoSQL数据库的功能是通过多台机器来实现的,所以HBase定位是分布式的NoSQL.
HBase集群下会有很多台机器,每台机器都叫做RegionServer,RegionServer底层操作数据的时候会和HDFS打交道.
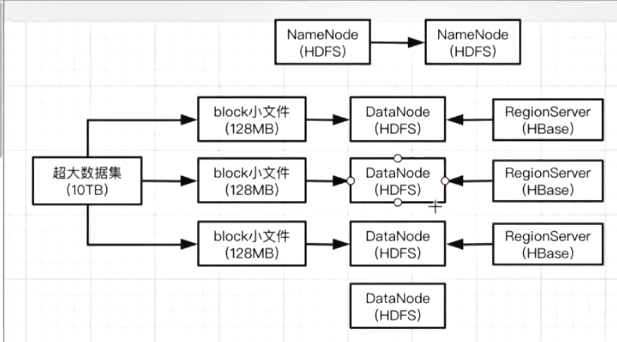
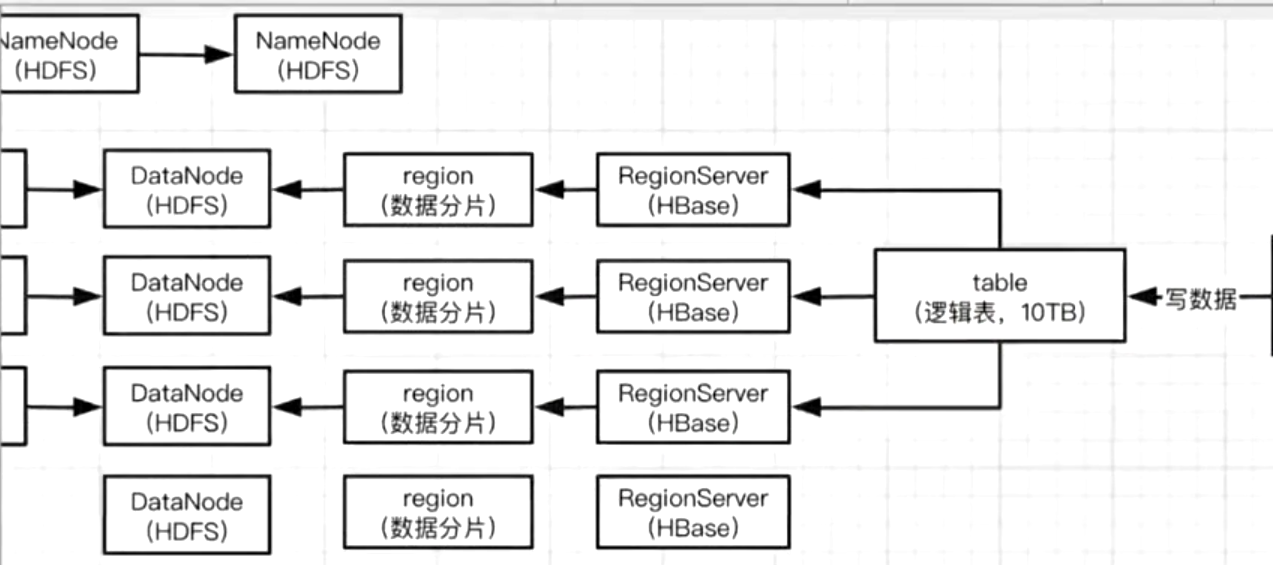
你往HBase里面搞一个表,往表里面灌数据,其实这些数据会分散为很多个region(数据分片)的,每个region其实就是数据的一个分片.
这些region作为数据的分片,最底层的数据其实是存在HDFS上的DataNode上的.
不同的Region(数据分片)其实就交给不同的RegionServer来进行管理.
所以HBase为什么叫做分布式的数据存储,其实就是HBase会用多台机器,多个RegionServer对这些Region进行一个分布式的存放和管理.
这些Region的数据本身也是以一个分布式的形式存放到HDFS集群上的多个DataNode的.
你往HBase里面建一张表,往表里面搞10TB的数据,这些数据其实会拆成很多的Region数据分片, 不同的Region数据分片其实是在不同的RegionServer上面的. 每一台RegionServer管理一部分的Region.
自动数据分片
这个功能是非常强大的,比如说你搞了一个HBase的表,然后表里面搞很多数据,此时表会分成很多的Region,每个Region里是一个数据分片,然后这些Region数据分片就会分散在多台机器上,.
假设你的表里的数据太多了,此时Region会自动进行分裂,分裂成更多的Region,自动分散在更多的机器上,这样保证每个Region的数据量不会太大, 而且如果你的表里面的数据太多的话,会导致你有很多Region,有很多Region之后的话,实际上来说你后面只要对HBase进行线性扩容,就是给HBase加机器(加RegionServer ), 那么更多的机器自然就可以管理更多的Region,也就是会管理更多的数据了
HBase基本架构
HBase是强一致性的
https://www.yuque.com/docs/share/1f395c4c-243d-4710-a5b2-286061a38011?# 《HBase是强一致性的》
HBase支持MapReduce和Spark离线分布式计算
对HBase李的数据进行分布式存储,可以从HBase里面分布式抽数据去计算,也可以把计算后的结果写入HBase分布式存储.
参考

若有收获,就点个赞吧
0 人点赞
