举例子
假如Driver说有个BigArr ,这个变量数据很大,在运行的时候需要在Executor进程里面运行,那么就需要将这个BigArr分发过去.
假如说每个Executor有两个线程,每个线程有一个BigArr,如果BigArr占用1G内存的话,那么一个Executor进程就会有2个G的BigArr
如果程序只是对BigArr进行读操作而不进行修改操作,这个时候完全可以搞一个BigArr就可以了.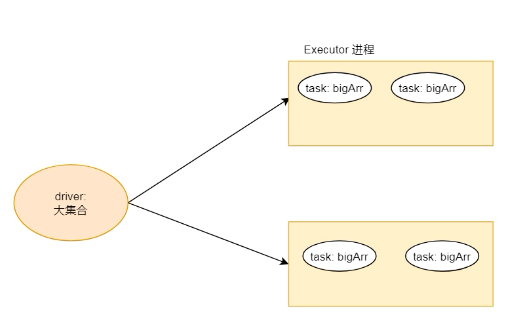
解决办法
我们可以给每个Executor里面的每个线程的BigArr都放到Executor进程里面,让多个线程共享进程里面的BigArr,这样节省了系统内存资源. 这就是广播变量.
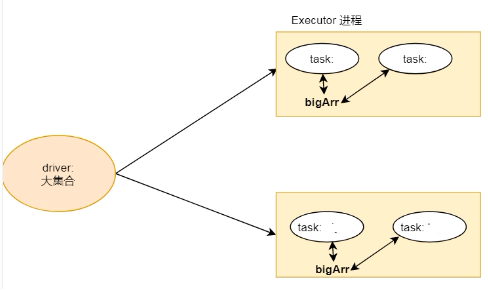
广播变量概念
广播变量在每个节点上保存一个只读的变量的缓存, 而不用给每个 task 来传送一个 copy.这样降低了通讯的成本,
广播变量通过调用SparkContext.broadcast(v)来创建. 广播变量是对v的包装, 通过调用广播变量的 value方法可以访问.
广播变量只会被发到各个节点一次,应作为只读值处理(修改广播变量的值不会影响到别的节点).
代码演示
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object demo {def main(args: Array[String]): Unit = {val bigArr = 1 to 1000 toArrayval conf: SparkConf = new SparkConf().setAppName("BroadCastDemo1").setMaster("local[2]")val sc: SparkContext = new SparkContext(conf)// 广播出去.val bd = sc.broadcast(bigArr)val list1 = List(30, 50000000, 70, 600000, 10, 20)val rdd1: RDD[Int] = sc.parallelize(list1, 4)//获取 广播变量的引用 , 使用广播变量的value值就可以获取到广播变量内部封装的值// 过滤rdd1和bigArr有交集的变量val rdd2 = rdd1.filter(x => bd.value.contains(x))rdd2.collect.foreach(println)Thread.sleep(1000000)sc.stop()}}
输出
30701020

若有收获,就点个赞吧
0 人点赞
