前提
https://blog.csdn.net/qq_41489540/article/details/109175329
编写Flume配置文件
f1.conf
#a1是agent的名称,a1中定义了一个叫r1的source,如果有多个,使用空格间隔a1.sources = r1a1.channels = c1 c2#组名名.属性名=属性值a1.sources.r1.type=TAILDIRa1.sources.r1.filegroups=f1# 一批写多少个a1.sources.r1.batchSize=1000#读取/tmp/logs/app-yyyy-mm-dd.log ^代表以xxx开头$代表以什么结尾 .代表匹配任意字符#+代表匹配任意位置a1.sources.r1.filegroups.f1=/tmp/logs/^app.+.log$#JSON文件的保存位置a1.sources.r1.positionFile=/root/soft/apache-flume-1.7.0/custdata/log_position.json#定义拦截器a1.sources.r1.interceptors = i1a1.sources.r1.interceptors.i1.type = com.atguigu.dw.flume.MyInterceptor$Builder#定义ChannelSelectora1.sources.r1.selector.type = multiplexinga1.sources.r1.selector.header = topic# 要和你自己写的拦截器一样才行.a1.sources.r1.selector.mapping.topic_start = c1a1.sources.r1.selector.mapping.topic_event = c2#定义chanel为 KafkaChannela1.channels.c1.type=org.apache.flume.channel.kafka.KafkaChannel# Kafka地址a1.channels.c1.kafka.bootstrap.servers=zjj101:9092,zjj102:9092,zjj103:9092#定义Kafka主题地址.如果不自己创建的话会自动创建,建议自己创建,自己创建可以指定分区和副本.a1.channels.c1.kafka.topic=topic_start# 不希望存header信息a1.channels.c1.parseAsFlumeEvent=falsea1.channels.c2.type=org.apache.flume.channel.kafka.KafkaChannela1.channels.c2.kafka.bootstrap.servers=zjj101:9092,zjj102:9092,zjj103:9092a1.channels.c2.kafka.topic=topic_eventa1.channels.c2.parseAsFlumeEvent=false#连接组件 同一个source可以对接多个channel,一个sink只能从一个channel拿数据!a1.sources.r1.channels=c1 c2
创建两个topic
创建 topic_start 和 topic_event ,都是三个分区两个副本数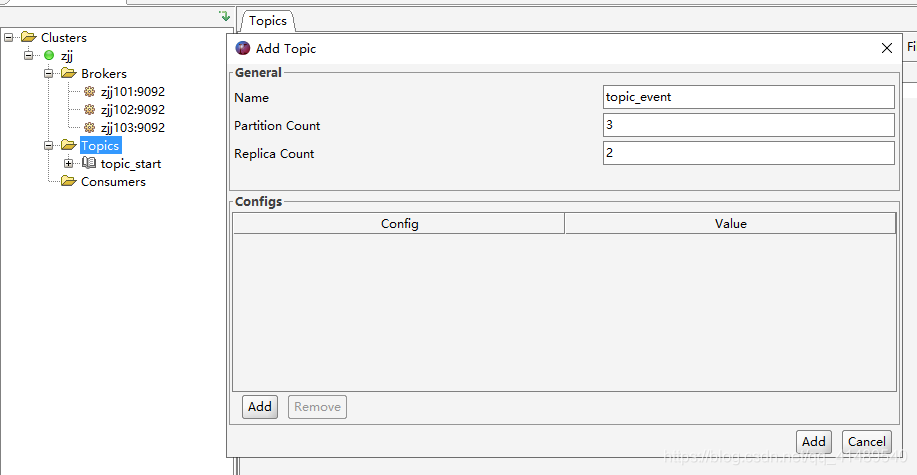
启动Flume收集日志
[root@zjj101 conf]# flume-ng agent -c conf/ -n a1 -f /root/soft/apache-flume-1.7.0/conf/f1.conf -Dflume.root.logger=DEBUG,console
查看Flume记录日志的json文件
发现已经读了app-2020-10-15.log 文件.
[root@zjj101 custdata]# cat log_position.json[{"inode":1870589,"pos":696353,"file":"/tmp/logs/app-2020-10-15.log"}][root@zjj101 custdata]#
用kafka 工具查看
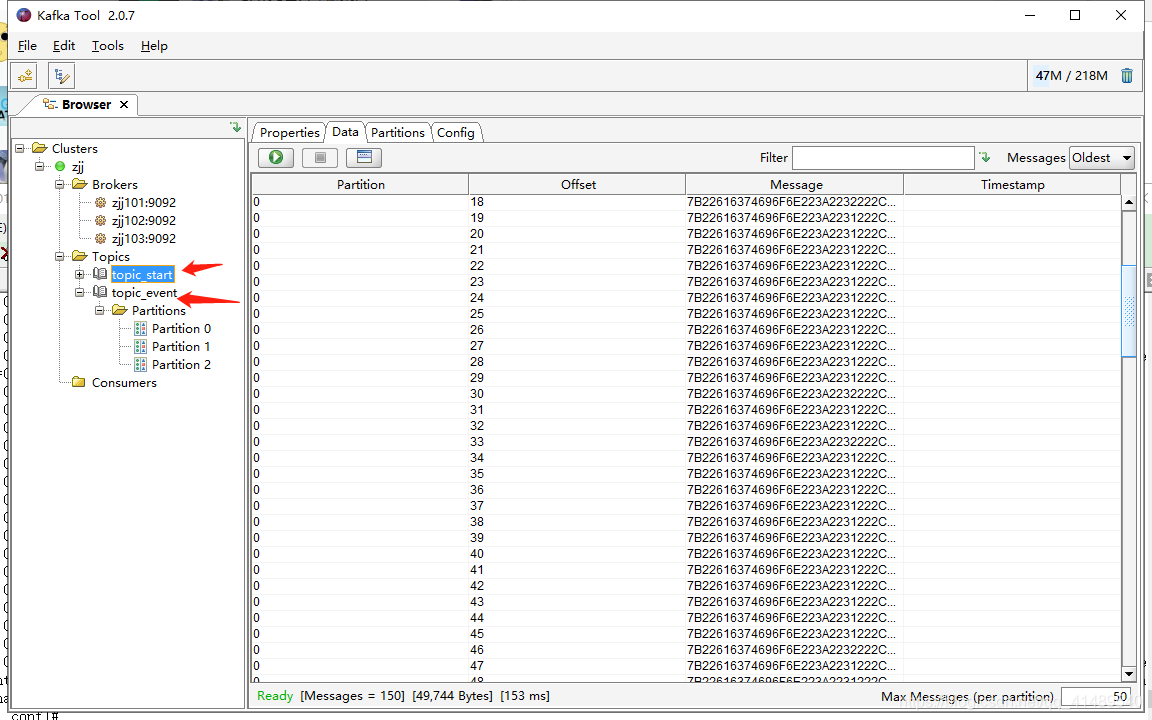
发现已经有数据了

若有收获,就点个赞吧
0 人点赞
