作用
对 RDD 进行分区操作,如果原有的 partionRDD 的分区器和传入的分区器相同, 则返回原 pairRDD,否则会生成 ShuffleRDD,即会产生 shuffle 过程.假如说原来是根据hash分区的,你又分区,但是还是根据hash分区的,此时就不会出现shuffle过程.
RDD的特性是一组分区,每个分区的数据不一样. 默认分区器是HashPartitioner,HashPartitioner是根据每个值的key,然后去调用hashcode方法拿到一个hash值(int整数),然后用int整数对当前分区数做取模运算,比如说 有两个分区. hash值%2,不是0就是1, 如果结果是0就放0号分区,如果结果是1就放1号分区里面.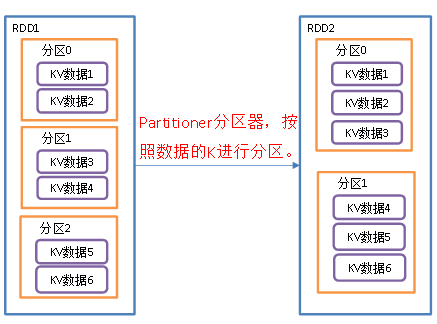
案例
默认HashPartitioner的使用
import org.apache.spark.rdd.RDDimport org.apache.spark.{HashPartitioner, Partitioner, SparkConf, SparkContext}object Transformation_partitionBy2 {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")val sc: SparkContext = new SparkContext(conf)//创建RDD//注意:RDD本身是没有partitionBy这个算子的,通过隐式转换动态给kv类型的RDD扩展的功能// val rdd2: RDD[Int] = sc.makeRDD(List(1,2,3,4))// rdd2.partitionBy()如果是单个值的类型的话,调用rdd的partitionBy方法是不行的,因为没这个方法val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "aaa"), (2, "bbb"), (3, "ccc")), 3)rdd.mapPartitionsWithIndex {(index, datas) => {println(index + "------" + datas.mkString(","))datas}}.collect()/*1------(2,bbb)2------(3,ccc)0------(1,aaa)*/println("----------------------------------------------")//用hash 分区val newRDD: RDD[(Int, String)] = rdd.partitionBy(new HashPartitioner(2))newRDD.mapPartitionsWithIndex {(index, datas) => {println(index + "------" + datas.mkString(","))datas}}.collect()/*1------(1,aaa),(3,ccc)0------(2,bbb)*/sc.stop()}}

若有收获,就点个赞吧
0 人点赞
