函数签名:
def groupByk(implicitkt:ClassTag[K]):RDD[{K,Iterable[T]}]
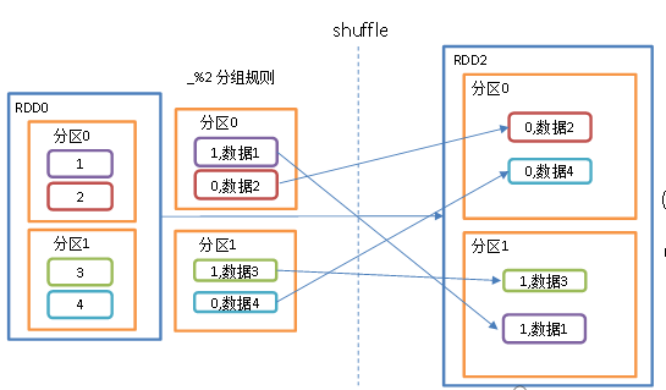
groupBy算子会对RDD里面的每个元素进行遍历,给每个元素取出来作为参数传递给T, 然后根据分组规则去匹配.
groupBy会存在shuffle过程
shuffle:将不同的分区数据进行打乱重组的过程
shuffle一定会落盘。可以在local模式下执行程序,通过4040看效果。
作用:
按照func的返回值进行分组.
func返回值作为 key, 对应的值放入一个迭代器中. 返回的 RDD: RDD[(K, Iterable[T])
每组内元素的顺序不能保证, 并且甚至每次调用得到的顺序也有可能不同.
groupBy算子返回值是元祖,key是当前组,value是当前组的所有元素.
例子
根据偶数和奇数分组
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}/**** Desc: 转换算子-groupBy* -按照指定的规则,对RDD中的元素进行分组*/object Spark05_Transformation_groupBy {def main(args: Array[String]): Unit = {//创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)println("==============groupBy分组前================")rdd.mapPartitionsWithIndex((index, datas) => {println(index + "---->" + datas.mkString(","))datas}).collect()/*输出: 0---->1,2,3,41---->5,6,7,8,9*///按奇数和偶数分组val newRDD: RDD[(Int, Iterable[Int])] =rdd.groupBy(x => x % 2) // 可以简写成 rdd.groupBy(_ % 2)println("==============groupBy分组后================")newRDD.mapPartitionsWithIndex((index, datas) => {println(index + "---->" + datas.mkString(","))datas}).collect()//这里有三个分区,但是是根据奇数偶数分组的,数据就只有两条,要不就是奇数要不就是偶数//所以2号区域就是空的了./*2---->1---->(1,CompactBuffer(1, 3, 5, 7, 9))0---->(0,CompactBuffer(2, 4, 6, 8))*/// 关闭连接sc.stop()}}
按相同元素进行分组
object Spark05_Transformation_groupBy222 {def main(args: Array[String]): Unit = {//创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)val original = sc.makeRDD(List("aaa", "bbb", "ccc", "aaa", "ccc"))val value = original.groupBy(datas => datas)val tuples:Array[(String, Iterable[String])] = value.collect()for (i <- tuples) {println(i)}/*(ccc,CompactBuffer(ccc, ccc))(bbb,CompactBuffer(bbb))(aaa,CompactBuffer(aaa, aaa))*/}}
按把奇数和偶数值分组,并且累加
object Spark05_Transformation_groupBy222 {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")val sc: SparkContext = new SparkContext(conf)val original = sc.makeRDD(List(1, 2, 3, 4, 5, 6))//按奇数偶数分组val gbrdd = original.groupBy(datas => datas % 2)val tuples: Array[(Int, Iterable[Int])] = gbrdd.collect()val value = gbrdd.map({//每个组的值累加case (k, it) => (k, it.sum)})println(value.collect().mkString(",")) //输出: (0,12),(1,9)}}

若有收获,就点个赞吧
0 人点赞
