存在的问题
在定义共享一个变量去记录计数的时候会出现一个问题
import org.apache.spark.{SparkConf, SparkContext}import org.apache.spark.rdd.RDDobject demo {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("Add").setMaster("local[2]")val sc: SparkContext = new SparkContext(conf)val list1 = List(30, 50, 70, 60, 10, 20)val rdd1: RDD[Int] = sc.parallelize(list1, 2)var a = 0val rdd2: RDD[Int] = rdd1.map(x => {a += 1x})rdd2.collectprintln(a) //输出: 0Thread.sleep(10000000)sc.stop()}}
上面程序a的结果为0
出现原因
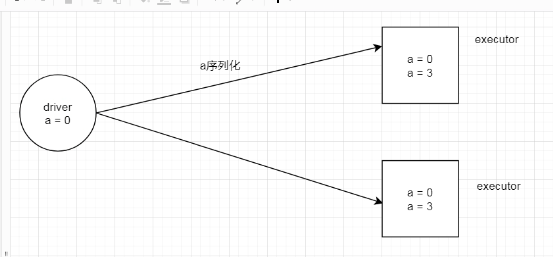
在Driver端声明了一个变量,等于0 ,然后开始执行程序.程序在Executor上执行需要给a的值序列化到Executor过去, 此时在程序里面是给Executor里面的值进行操作的,并没有对Driver的值进行操作, 所以Driver的值一直就是0了.
解决办法 使用累加器
使用累加器,解决了共享变量的写的问题
累加器概念
累加器用来对信息进行聚合,通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,所以更新这些副本的值不会影响驱动器中的对应变量。
如果我们想实现所有分片处理时更新共享变量的功能,那么累加器可以实现我们想要的效果。
Spark提供的Accumulator,主要用于多个节点对一个变量进行共享性的操作。Accumulator只提供了累加的功能,但是却给我们提供了多个task对一个变量并行操作的功能。task只能对Accumulator进行累加操作,不能读取它的值。只有Driver程序可以读取Accumulator的值。
累加器是一种变量, 仅仅支持“add”, 支持并发. 累加器用于去实现计数器或者求和. Spark 内部已经支持数字类型累加器(Long累加器 double累加器 collection累加器 这三种累加器), 开发者可以添加其他类型的支持(自定义累加器).
累加器使用场景
- 需要对共享变量做修改
- 对同一个rdd需要遍历多次计算多个指标,可以使用累加器一次完成多个指标的运算.
累加器的注意事项
累加器只能在行动算子中使用,尽量不要用在转换算子里面,因为转换算子里面极有可能导致累加器计算的值会失败,如果失败就会进行重试,如果重试的话,那么累加器的值就会出现重复计算的问题了.
累加器案例
import org.apache.spark.{SparkConf, SparkContext}import org.apache.spark.rdd.RDDimport org.apache.spark.util.LongAccumulatorobject demo {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("Add").setMaster("local[2]")val sc: SparkContext = new SparkContext(conf)val list1 = List(30, 50, 70, 60, 10, 20)val rdd1: RDD[Int] = sc.parallelize(list1, 2)// 声明一个累加器val acc: LongAccumulator = sc.longAccumulator("one")val rdd2: RDD[Int] = rdd1.map(x => {acc.add(1)x})rdd2.collect// 取出累加器的值println(acc.value) //输出: 6Thread.sleep(10000000)sc.stop()}}
自定义累加器
https://www.yuque.com/docs/share/8303f193-a62a-4b9a-8fc5-2b4ccb8bf440?# 《Spark自定义int类型的累加器》
https://www.yuque.com/docs/share/827097fa-1c4e-4638-8d55-29634a730d77?# 《Spark自定义Map类型的累加器》

若有收获,就点个赞吧
0 人点赞
