准备数据
建表语句:
CREATE TABLE HAO1 ( id char(36) not null primary key, name varchar(50), age INTEGER, createtime DATE)
插入数据:
upsert into HAO1 ( id, name , age, createtime ) values('1', 'zhangsan',15,TO_DATE('2021-01-23 09:00:02'))upsert into HAO1 ( id, name , age, createtime ) values('2', 'lisi',22,TO_DATE('2021-01-23 09:11:02'))upsert into HAO1 ( id, name , age, createtime ) values('3', 'wangwu',25,TO_DATE('2021-01-23 09:56:02'))
覆盖索引概念
Phoenix提供了一种叫Covered Index覆盖索引的二级索引。这种索引在获取数据的过程中,内部不需要再去HBase上获取任何数据,你查询需要返回的列的数据都会被存储在索引中。要想达到这种效果,你的select 的列,where 的列都需要在索引中出现。举个例子,如果你的SQL语句是 select name from hao1 where age=15 ,要最大化查询效率和速度最快,你就需要建立覆盖索引:
explain select name from hao1 where age=15 # 这样查询就是FULL SCAN全表查询,就不粘贴代码了
添加覆盖索引:
CREATE INDEX index1_c ON hao1 (age) INCLUDE(name);
注意关键字INCLUDE,就是包含需要返回数据结果的列。这种索引方式的最大好处就是速度快,而我们也知道,索引就是空间换时间,所以缺点也很明显,存储空间耗费较多
查看添加的覆盖索引
我使用的是Squirrel Sql Client工具,发现HAO1表已经添加了名字为INDEX1_C的索引.
Phoenix的索引其实就是建了一张HBase的表。你可以通过HBase Shell的list命令看到。查看表index1_c,你会发现,这张表一共三列,一列就是索引,第二列是RowKey,最后一列就是Name的值。很明显在这里记录的RowKey,就是为了快速查找HBase中的数据。只是这里用不到,Name已经被缓存在这张索引里面了,直接返回。
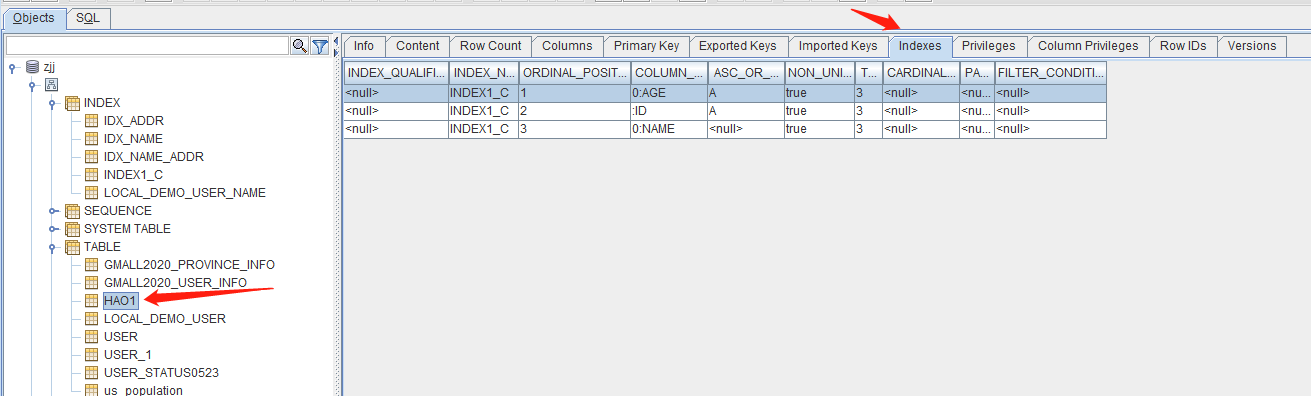
在INDEX列里面也能看到创建了一个INDEX1_C的一个INDEX
查询索引表
select * from index1_c
结果:
| 0:AGE | :ID | 0:NAME |
|---|---|---|
| 15 | 1 | zhangsan |
| 22 | 2 | lisi |
| 25 | 3 | wangwu |
上面已经说了,Phoenix的Index其实就是一个表,第一列是索引字段,第二列是RowKey,第三列是被覆盖索引覆盖的字段.
查询数据
explain select age ,name from HAO1 # 执行结果PLAN 就是FULL SCAN 全表扫描,
explain select age ,name from HAO1 where age = 15 # 执行结果PLAN是CLIENT 1-CHUNK PARALLEL 1-WAY ROUND ROBIN RANGE SCAN OVER INDEX1_C [15] ,也就是范围扫描,用到了索引INDEX1_C
explain select * from HAO1 where age = 15 # 执行结果PLAN 就是FULL SCAN 全表扫描,, 这种还会看原的数据表,因为*是查询所有字段,HBASE不知道你有哪些字段,哪怕你所有字段都被覆盖索引了.HBAS还是会全表查询.

若有收获,就点个赞吧
0 人点赞
