概念
功能说明
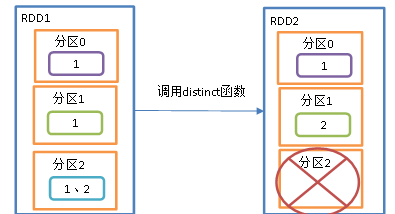
对内部元素进行去重复,并将去重复的元素放到新的RDD里面 ,默认情况下distinct算子会生成与原来RDD分区个数一致的分区数
distinct算子也可以指定分区数,比如说我有10W条数据,去重复之后就变成了1W条数据了,那么之前的分区就可能不需要那么多了.
distinct算子底层有shuffle过程,会给分区元素打乱重组.
实操
不指定分区
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object Spark09_Transformation_distinct22 {def main(args: Array[String]): Unit = {//创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//创建RDDval numRDD: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,5,4,3,3),5)numRDD.mapPartitionsWithIndex{(index,datas)=>{println(index + "--->" + datas.mkString(","))datas}}.collect()/* 没去重复之前是5个分区输出:1--->2,33--->5,42--->4,54--->3,30--->1*/println("---------------")//对RDD中的数据进行去重, 100W条数据去重复之后可能还剩下10W条数据,那么 distinct 也可以重新指定分区val newRDD: RDD[Int] = numRDD.distinct()newRDD.mapPartitionsWithIndex{(index,datas)=>{println(index + "--->" + datas.mkString(","))datas}}.collect()/*去重复之后还是五个分区4--->42--->21--->10--->53--->3*///newRDD.collect().foreach(println)// 关闭连接sc.stop()}}
指定分区
distinct算子可以指定分区数.
五个分区的元素经过去重复之后变成两个分区了
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object demo {def main(args: Array[String]): Unit = {//创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//创建RDDval numRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 5, 4, 3, 3), 5)numRDD.mapPartitionsWithIndex {(index, datas) => {println(index + "--->" + datas.mkString(","))datas}}.collect()/* 没去重复之前是5个分区输出:1--->2,33--->5,42--->4,54--->3,30--->1*/println("---------------")//指定两个分区数val newRDD: RDD[Int] = numRDD.distinct(2)newRDD.mapPartitionsWithIndex {(index, datas) => {println(index + "--->" + datas.mkString(","))datas}}.collect()/*输出1--->1,3,50--->4,2*///newRDD.collect().foreach(println)// 关闭连接sc.stop()}}
根据 bean的年龄字段去重复
import org.apache.spark.{SparkConf, SparkContext}case class User(age: Int, name: String) {override def hashCode(): Int = this.ageoverride def equals(obj: Any): Boolean = obj match {case User(age, _) => this.age == agecase _ => false}}object demo {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("Distinct").setMaster("local[2]")val sc: SparkContext = new SparkContext(conf)//年龄相等就重复,需要覆写hashCode和equals这两个方法.val rdd1 = sc.parallelize(List(User(10, "lisi"), User(20, "zs"), User(10, "ab")))val rdd2 = rdd1.distinct(2)rdd2.collect.foreach(println)sc.stop()}}
输出结果就是:
User(20,zs)
User(10,lisi)

若有收获,就点个赞吧
0 人点赞
