概念
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = self.withScope {reduceByKey(defaultPartitioner(self), func)}
相同的key到一组,然后对value进行运算,怎么计算?就通过reduceByKey的入参函数进行运算,
做完聚合运算之后还可以重新分区.
在一个(K,V)的 RDD 上调用,返回一个(K,V)的 RDD,使用指定的reduce函数,将相同key的value聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置。
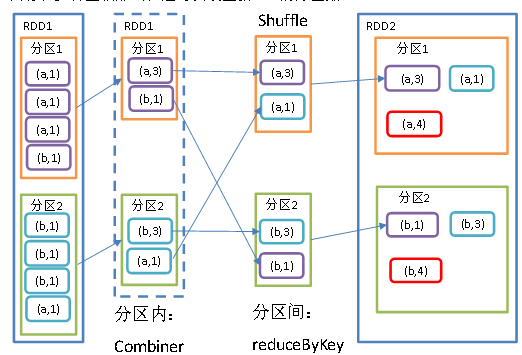
**
先做分区内的聚合,然后进行shuffle过程给相同key的数据放到一个分区,最后将相同的key进行聚合.
案例
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object Transformation_reduceByKey {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")val sc: SparkContext = new SparkContext(conf)val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 3), ("a", 5), ("b", 2)))//在匿名函数里面指定value运算规则//求和运算val resRDD: RDD[(String, Int)] = rdd.reduceByKey((x, y) => x + y)// rdd.reduceByKey((x,y) => x+y) 可以简写为 rdd.reduceByKey(_ + _)resRDD.collect().foreach(println)// 关闭连接sc.stop()}}

若有收获,就点个赞吧
0 人点赞
