概念
概念: 以分区为单位执行map算子
假如说rdd里面有10个元素,那么map算子执行10次.
mapPartitions是按分区处理数据 ,有两个分区就执行两次mapPartitions算子,mapPartitions有点批量处理的意思.
假设有N个元素,有M个分区,那么map的函数的将被调用N次,而mapPartitions被调用M次,一个函数一次处理所有分区。
其实mapPartitions和map处理次数是一样的,mapPartitions是一次给一个分区的数据取出来作为函数来处理,在底层再依次对每个元素进行处理..
mapPartitions适合批量操作.
使用场景之一比如说从MySQL里面拉数据,mapPartitions每个分区执行一次连接MySQL,这样的话,MySQL连接消耗会少一些.
如果是map的话,一个元素连接一次MySQL,那样性能就不太好了.
注意:
如果分区的数据量太大的话需要考虑OOM问题, 如果内存紧张的话,还是建议用map.具体需要根据业务场景来判断.
**
案例
需求: 对分区里面的每个数据都乘以2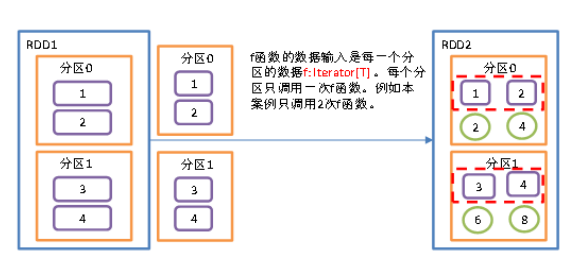
package com.atguigu.spark.day03import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object Spark01_Transformation_mapPartitions {def main(args: Array[String]): Unit = {//创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)//以分区为单位,对RDD中的元素进行映射//一般适用于批处理的操作,比如:将RDD中的元素插入到数据库中,需要数据库连接,// 如果每一个元素都创建一个连接,效率很低;可以对每个分区的元素,创建一个连接//val newRDD: RDD[Int] = rdd.mapPartitions(_.map(_ * 2))// datas 是当前分区数的数据, 如果你想对当前分区数的数据进行操作的话,去需要用map对分区内的数据进行操作// datas是自己命名的变量名,你可以随便命名val newRDD: RDD[Int] = rdd.mapPartitions(datas => {datas.map(elem => elem * 2)})//输出newRDDnewRDD.collect().foreach(println)// 关闭连接sc.stop()}}

若有收获,就点个赞吧
0 人点赞
