参考
我是照着这个作者的文章学习, 并且自己又总结了一下, 毕竟本人能力有限,不可能完全照着官方文档去自己研究 = =所以很多东西都是把别人的知识偷过来,自己再练习一下总结一下,占为己有,就变成自己的东西了…
原作者:
添加链接描述
准备数据
/root/soft/buckt_data.txt
1,name14,name43,name36,name65,name57,name79,name98,name82,name2
创建普通的表
create table test(id int comment 'ID',name string comment '名字')comment '测试分桶中间表'ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
用来导数据用, 因为要想往分区表里面导入数据必须要经过MapReduce程序
查看
select *from test;
现在是空的
往空的test临时表里面导数据
load data local inpath '/root/soft/buckt_data.txt' into table test;
再看一下test临时表
select *from test;
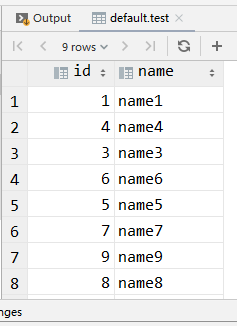
有了,但是数据是乱的.
创建排序的分桶表
每个分区筒里面根据id升序
sql
create table test_bucket_sorted(id int comment 'ID',name string comment '名字')comment '测试分桶'clustered by (id) sorted by (id) into 4 bucketsROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
查看是否开启了分桶和排序
sql
set hive.enforce.bucketing ; -- 查看分桶配置set hive.enforce.sorting ; -- 查看排序配置
默认是false,需要配置成true
下面SQL依次执行一遍
sql:
set hive.enforce.bucketing=true; --开启强制分桶,默认是不会帮你分桶的set hive.enforce.sorting=true; -- 开启强制排序,默认是不会帮你排序的.
从临时表里面导入数据
上面已经执行了
sql:
select *from test;
看到test这个临时表数据是乱序的
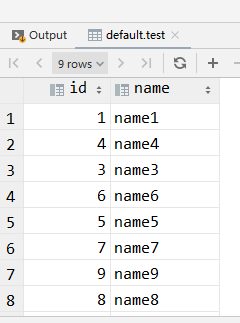
开始导入数据,
sql:
insert into test_bucket_sortedselect *from test;
查看导入的结果
sql:
select *from test_bucket_sorted;
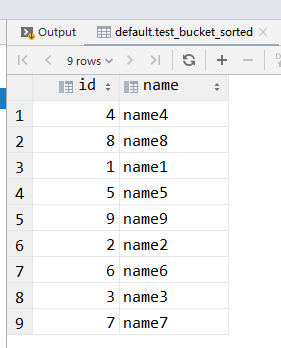
看到这里别着急,最初我也是以为分桶表排序后查询的顺序也是一致的,其实结论不是这样的, 因为你分桶表是给数据分到多个地方,多个地方里面每一个桶里面才是根据某个字段排序的,并不是查询出来的就是语句就是排序的, 这点我在初学的时候我犯过这个错误..
验证是否根据id进行排序了
登录hdfs
可以看到已经分了四个桶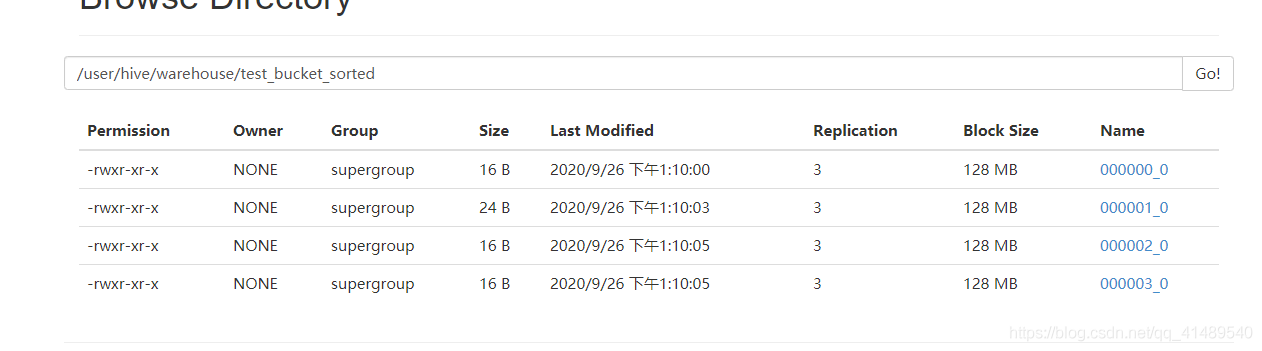
依次打开这四个文件
shell:
[root@zjj101 ~]# hadoop fs -cat /user/hive/warehouse/test_bucket_sorted/000000_04,name48,name8[root@zjj101 ~]# hadoop fs -cat /user/hive/warehouse/test_bucket_sorted/000001_01,name15,name59,name9[root@zjj101 ~]# hadoop fs -cat /user/hive/warehouse/test_bucket_sorted/000002_02,name26,name6[root@zjj101 ~]# hadoop fs -cat /user/hive/warehouse/test_bucket_sorted/000003_03,name37,name7[root@zjj101 ~]#
可以看到这四个文件里面每个都是根据第一个字段进行排序的, 也就是根据id排序的. 这才是分桶表排序的地方, 并不是说我执行了select from test_bucket_sorted; 看到的结果没排序我就认为排序失败了..这是我初学时候犯过的错误.
下面再仔细对比一下.
下面执行完了select from test_bucket_sorted; 给四个桶的数据都打出来了,顺序和上面 481592637 顺序是一样的.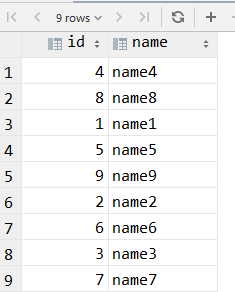

若有收获,就点个赞吧
0 人点赞
