大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的,就是在yarn上运行。不过,有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际job的执行时间要多的多。对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
用户可以通过设置hive.exec.mode.local.auto的值为true,来让Hive在适当的时候自动启动这个优化。
主要注意的是本地MapReduce模式只有在ReduceTask数量为1的时候才有效.
set hive.exec.mode.local.auto=true; //开启本地mr,不走yarn ,其实数据量少的时候本地模式快,但是数据量大的时候还不如yarn,因为yarn是分布式运算.
//设置本地MapReduce的最大输入数据量,当输入数据量小于这个值时采用本地MapReduce的方式,默认为134217728,即128M,下面的参数值,如果任务小于这个值的话就在本地模式运行,否则就采用yarn模式运行.
set hive.exec.mode.local.auto.inputbytes.max=50000000;
//设置本地MapReduce的最大输入文件个数,当输入文件个数小于这个值时采用本地MapReduce的方式运行,默认为4,如果超过了这个数量就会在yarn上面运行.
set hive.exec.mode.local.auto.input.files.max=10;
临时设置
注意,这样的配置只是当前会话有效,关闭客户端就失效了,如果想一直有效,就配置到配置文件里面去.
# 查看初始值 ,默认是falseset hive.exec.mode.local.auto;# 开启本地模式,并执行查询语句set hive.exec.mode.local.auto=true;# 执行查询语句看看时间select * from emp cluster by deptno;Time taken: 1.328 seconds, Fetched: 14 row(s)# 关闭本地模式,并执行查询语句set hive.exec.mode.local.auto=false;# 执行查询语句看看时间select * from emp cluster by deptno;Time taken: 20.09 seconds, Fetched: 14 row(s)
能看到时间相差了不少
永久设置
在 /hive-1.2.1/conf 文件夹下面找到hive-site.xml 配置文件
hive-site.xml :
<property><name>hive.exec.mode.local.auto</name><value>true</value></property>
保存之后重启hive
如何重启hive 如果不会的话,查看这个:
重启hive需要等待一会儿,重启完了查看配置是否生效
sql:
set hive.exec.mode.local.auto;
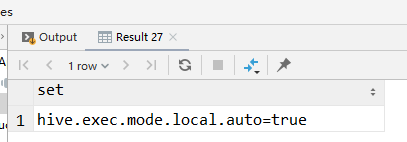
说明配置生效了.
效果对比
没配置之前
sql> select t1.base,concat_ws('|', collect_set(t1.name)) namefrom (select name,concat(constellation, ",", blood_type) basefrom person_info) t1group by t1.base[2020-10-03 16:21:31] 3 rows retrieved starting from 1 in 32 s 156 ms (execution: 32 s 129 ms, fetching: 27 ms)
配置之后
[2020-10-03 16:34:05] 1 row retrieved starting from 1 in 24 ms (execution: 8 ms, fetching: 16 ms)sql> select t1.base,concat_ws('|', collect_set(t1.name)) namefrom (select name,concat(constellation, ",", blood_type) basefrom person_info) t1group by t1.base[2020-10-03 16:34:34] 3 rows retrieved starting from 1 in 3 s 306 ms (execution: 3 s 271 ms, fetching: 35 ms)
可以看到差距是很大的.

若有收获,就点个赞吧
0 人点赞
