文首推荐下 田渊栋老师在B站的讲座 OR Talk NO.5 | Facebook 田渊栋:用深度(强化)学习为组合优化寻找更好的启发式搜索策略
本文翻译自Keras官网文档-the future of deep learning 第二篇
这是”当前深度学习的限制和未来“的第二篇,第一篇请见 The limitations of deep learning
给定当我们已经了解深层次的神经网络如何工作,它的缺陷以及当前的研究现状,我们是否能够预测中期的研究发展方向?这里给出了几个存粹的个人思考。如果我们都没有可预言未来的能力的话,所参与研究很大程度上都无法成为现实的实现。这完全是个推测性的文章。我分享这些预测的原因不仅仅是因为我期望它们完全在未来被证实为可行, 而却这些想法如此的有趣和很高的可操作性在当前的深度学习环境下。
在高层的抽象角度来看,我认为承诺的主要方向是:
- 模型完全近似于当前的计算机程序,建立在比我们现在的可微层(神经网络层)丰富得多的基础单单元之上-这就是我们将如何进行推理和抽象,这是当前模型的根本弱点。(这里谈构建模型过程中具体的推理和抽象复杂度非常高而且很多带有一定的随机性,无法被预判)。
- 新的学习形式,使上述的想法成为可能性,二不是仅仅允许模型进行可微的转换。
- 模型将需要较少的参与,将人类工程师从繁重的调参任务解放出来。 具有自学习(self-learning)和可迁移的能力。
- 对以前学习过的特性和体系结构进行更大的系统重用;基于可重用和模块化程序子程序的元学习系统。
此外,请注意,这些考虑因素并不特定于迄今为止一直是深度学习的基础的有监督学习,而是适用于任何形式的机器学习,包括无监督、自我监督和强化学习。从根本上说,你的标签来自哪里或你的训练循环是什么样子并不重要;机器学习的这些不同分支只是同一个结构的不同方面。
模型即程序
正如我们在上一篇文章中所指出的,在机器学习领域,我们可以期待的一个必要的变革发展,是从单纯执行模式识别、只能实现局部泛化的模型,向能够实现抽象和推理、能够实现极端泛化的模型的转变**。目前能够进行基本形式推理的人工智能程序都是由人类程序员硬编码的:例如,依赖于搜索算法、图形处理、形式逻辑的软件。例如,在DeepMind的AlphaGo中,显示的大多数“智能”是由专家程序员设计和硬编码的(例如蒙特卡罗树搜索);从数据中学习只发生在专门的子模块(价值网络和策略网络)。但在未来,这样的人工智能系统可能完全可以学习,而不需要人类的参与。
有什么途径可以实现这一点?考虑一种众所周知的网络类型:RNNs。重要的是,RNN比前馈网络的限制要小一些。这是因为rnn不仅仅是一个几何变换:它们是在for循环中重复应用的几何变换。时序for循环本身是由人类开发人员硬编码的:它是网络的内置假设。自然,rnn在它们所能表示的方面仍然非常有限,主要是因为它们执行的每一步仍然只是一个可微的几何变换,并且它们在一个连续的几何空间(状态向量)中通过点将信息从一个步骤传递到另一个步骤。现在,想象一下神经网络,它将以类似的方式“扩充”编程原语,例如for循环,而不仅仅是一个硬编码的for循环,它有一个硬编码的几何存储器,而是一个大的编程原语集,模型可以自由地操作这些原语来扩展它的处理功能,例如if分支,而语句、变量创建、用于长期内存的磁盘存储、排序运算符、高级数据结构(如列表、图表和哈希表)等等。这样一个网络所能代表的程序空间将远远大于现有的深度学习模型所能代表的程序空间,而且其中一些程序可以获得更好的泛化能力。
一句话来讲,我们将从一方面拥有“硬编码算法智能”(手工软件),另一方面拥有“学习几何智能”(深度学习)。相反,我们将混合使用提供推理和抽象能力的形式算法模块和提供非正式直觉和模式识别能力的几何模块。整个系统将在很少或没有人参与的情况下学习。
我认为人工智能的一个相关的子领域可能会以很大的方式起飞,那就是程序合成,特别是神经程序合成。程序综合包括自动生成简单的程序,通过使用搜索算法(可能是遗传搜索,如在遗传编程中)来探索大量可能的程序。当找到与所需规范匹配的程序时,搜索将停止,该规范通常作为一组输入-输出对提供。如您所见,它是否让人联想到机器学习:给定作为输入输出对提供的“训练数据”,我们找到一个“程序”,它将输入与输出相匹配,并可以推广到新的输入。不同的是,我们通过离散搜索过程生成源代码,而不是在硬编码程序(神经网络)中学习参数值。
我绝对希望这一子领域在未来几年内会出现新的兴趣浪潮。特别是,我预计在深度学习和程序合成之间会出现一个交叉子领域,在那里我们不会完全用通用语言生成程序,相反,我们会生成用一组丰富的算法原语增强的神经网络(几何数据处理流),例如for循环和许多其他。这应该比直接生成源代码更容易处理和有用,并且它将极大地扩展问题的范围,这些问题可以通过机器学习来解决,我们可以自动生成给定适当训练数据的程序空间。符号人工智能和几何人工智能的混合体。现代RNNs可以看作是这种混合算法几何模型的史前祖先。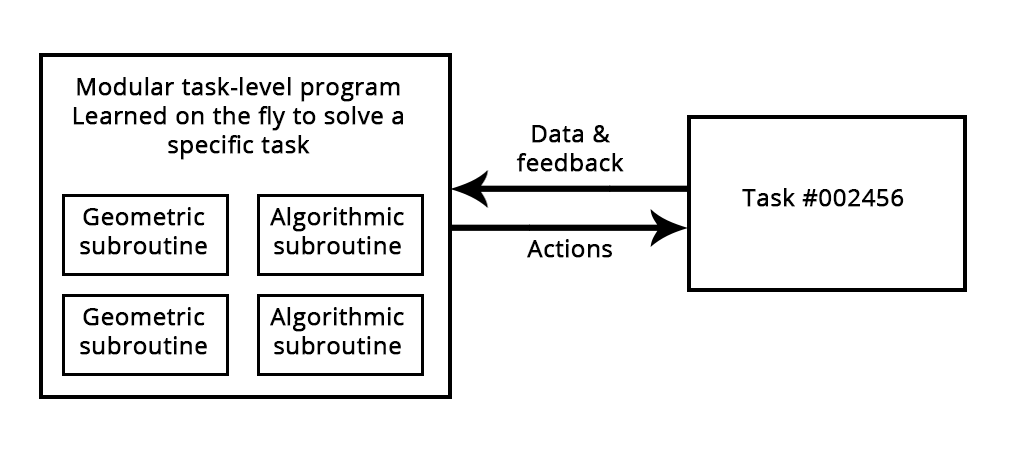
Figure: A learned program relying on both geometric primitives (pattern recognition, intuition) and algorithmic primitives (reasoning, search, memory).
超越反向传播和可微层
如果机器学习模型变得更像程序,那么它们大部分肯定不再是可微的,这些程序仍然会利用连续的几何层作为子程序,这将是可微的,但作为一个整体的模型不会。因此,在一个固定的、硬编码的网络中,使用反向传播来调整权重值,至少不能成为未来训练模型的选择方法,也不能是全部。我们需要找出有效训练不可微系统的方法。目前的方法包括遗传算法、“进化策略”、某些强化学习方法和ADMM(乘法器交替方向法)**。自然地,梯度下降是不会去任何地方梯度信息将总是有助于优化可微参数函数。但我们的模型肯定会比可微的参数函数更加雄心勃勃,因此它们的自动开发(机器学习中的“学习”)将需要比反向传播更多的东西。
此外,反向传播是端到端的,这对于学习良好的链式转换是一件很好的事情,但是由于它没有充分利用深层网络的模块性,因此在计算上效率相当低。为了提高效率,有一个通用的方法:引入模块化和层次结构。因此,我们可以通过引入解耦的训练模块和它们之间的同步机制,以分层的方式组织,使backprop本身更加高效。这一策略在DeepMind最近关于“合成梯度”的工作中有所反映。我希望在不久的将来能有更多这样的工作。
我们可以想象,未来的模型将是全局不可微的(但将具有可微部分)将使用一个高效的搜索过程来训练成长,该搜索过程不会利用梯度,而利用梯度,使用更有效的反向传播方法,可以更快地训练可微部分。
自动机器学习(AutoML)
在未来,模型架构将被学习,而不是由工程师手工制作。学习架构自动地与使用更丰富的原语集和类似程序的机器学习模型齐头并进。
目前,深度学习工程师的大部分工作是用Python脚本处理数据,然后长时间地调整深度网络的架构和超参数,以获得一个工作模型,甚至,达到一个最先进的模型,如果工程师是如此雄心勃勃。不用说,这不是一个最佳的设置。但人工智能也能帮上忙。不幸的是,数据挖掘部分很难实现自动化,因为它通常需要领域知识以及对工程师想要实现的目标的清晰的高层理解。然而,超参数优化是一个简单的搜索过程,我们已经知道在这种情况下工程师想要实现什么:它是由被优化网络的损失函数定义的。建立基本的“AutoML”系统已经是一种常见的做法,它将负责大多数型号旋钮的调节。我甚至在几年前就建立了自己的公司来赢得Kaggle的比赛。
在最基本的层次上,这样的系统只需调整堆栈中的层数、它们的顺序以及每一层中的单元或过滤器的数量。这通常是在诸如Hyperopt之类的库中完成的,我们在第7章中讨论过(注意:使用python来做深度学习)。但我们也可以更加雄心勃勃,尝试从零开始学习一个适当的体系结构,尽可能少的约束。例如,这可以通过强化学习或遗传算法来实现。
AutoML的另一个重要方向是结合模型权重学习模型体系结构。因为每次我们尝试稍微不同的体系结构时从头开始训练一个新的模型是非常低效的,一个真正强大的AutoML系统将设法在通过训练数据的backprop调整模型特性的同时进化体系结构,从而消除所有的计算冗余。在我写这些台词的时候,这种方法已经开始出现了。
当这种情况开始发生时,机器学习工程师的工作不会消失,相反,工程师将在价值创造链中走得更高。他们将开始投入更多的精力来构建真正反映业务目标的复杂损失函数,并深入了解其模型如何影响部署它们的数字生态系统(例如,使用模型预测并生成模型培训数据的用户)-这些问题目前仅是最大的公司可以考虑。
终身学习与模块化子程序重用
**
如果模型变得更复杂,并且建立在更丰富的算法基元之上,那么这种增加的复杂性将需要任务之间更高的重用,而不是每次我们有新任务或新数据集时都从头开始训练新模型。事实上,许多数据集不会包含足够的信息来从头开始开发一个新的复杂模型,因此有必要利用来自以前遇到的数据集的信息。就像你不可能每次打开一本不可能的新书就从头开始学英语一样。此外,由于当前任务和以前遇到的任务之间有很大的重叠,从头开始的每项新任务的培训模型都非常低效。
此外,近年来反复观察到的一个显著现象是,训练同一个模型同时执行几个松散连接的任务,会得到一个在每个任务上都更好的模型。例如,训练一个相同的神经机器翻译模型来涵盖英语到德语的翻译和法语到意大利语的翻译,将得到一个在每种语言对上都更好的模型。将图像分类模型与图像分割模型联合训练,共享相同的卷积基,得到一个在这两个任务上都更好的模型。等等。这是相当直观的:在这些看似不连贯的任务之间总是有一些信息重叠,因此联合模型可以获得关于每个单独任务的更多信息,而不仅仅是针对特定任务训练的模型。
我们目前在跨任务重用模型的过程中所做的工作是利用执行常见功能(如视觉特征提取)的模型的预先训练权重。你在第五章看到了这一点。在将来,我希望这一点的通用版本是常见的:我们不仅可以利用以前学到的特性(子模型权重),还可以利用模型架构和培训过程。随着模型变得越来越像程序,我们将开始重用程序子例程,比如在人类编程语言中找到的函数和类。
想想今天的软件开发过程:一旦一个工程师解决了一个特定的问题(比如Python中的HTTP查询),他们就会把它打包成一个抽象的、可重用的库。未来面临类似问题的工程师可以简单地搜索现有的库,下载一个库并在他们自己的项目中使用。以类似的方式,在未来,元学习系统将能够通过筛选高级别可重用块的全局库来组装新程序。当系统发现自己为几个不同的任务开发类似的程序子例程时,如果能提出一个“抽象的”,可重用的子例程版本,并将其存储在全局库中。这样一个过程将实现抽象的能力,这是实现“极端概括”的必要组成部分:一个在不同任务和领域中有用的子程序可以说是“抽象”了问题解决的某些方面。这个“抽象”的定义类似于软件工程中的抽象概念。这些子程序可以是几何(具有预先训练的表示的深度学习模块)或算法(更接近当代软件工程师操作的库)。
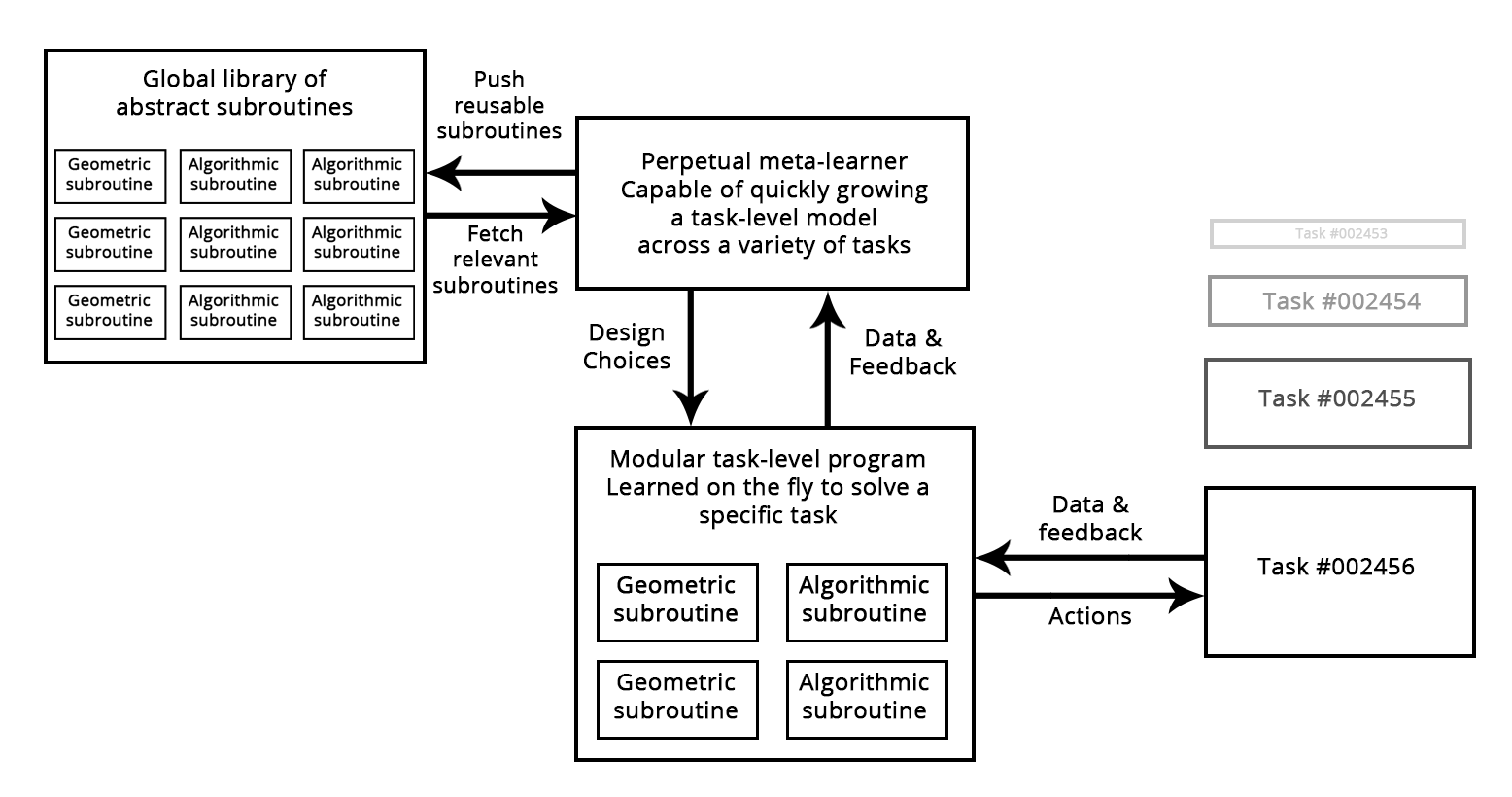
Figure: A meta-learner capable of quickly developing task-specific models using reusable primitives (both algorithmic and geometric), thus achieving “extreme generalization”.
总结: 长期愿景
**
简而言之,以下是我对机器学习的长期愿景:
- 模型将更像程序,并且将具有远远超出我们当前使用的输入数据的连续几何变换的能力。可以说,这些程序将更接近于人类对周围环境和自身所维持的抽象心理模型,并且由于其丰富的算法性质,它们将能够更强的泛化。
- 特别是,模型将混合算法模块,提供形式化的推理、搜索和抽象能力,几何模块提供非正式的直觉和模式识别能力。AlphaGo(一个需要大量手工软件工程和人为设计决策的系统)提供了一个早期的例子,展示了符号和几何人工智能之间的融合。它们将自动生长,而不是由人类工程师手工制作,使用存储在可重用子程序的全局库中的模块化部件,该库是通过学习数千个先前任务和数据集的高性能模型而发展起来的。当元学习系统识别出常见的问题解决模式时,它们将变成一个可重用的子程序,类似于当代软件工程中的函数和类,并添加到全局库中。这实现了抽象的能力。
- 这个全球图书馆和相关的模型增长系统将能够实现某种形式的类似人类的“极端概括”:在新的任务、新的情况下,该系统将能够使用很少的数据来组装适合该任务的新工作模型,多亏了1)丰富的程序类原语,能够很好地概括;2)丰富的类似任务经验。同样地,人类也可以学习使用很少的游戏时间来玩一个复杂的新游戏,因为他们有很多以前玩过的游戏的经验,并且因为从以前的经验中得到的模型是抽象的和程序化的,而不是刺激和动作之间的基本映射。
和程序化的,而不是刺激和动作之间的基本映射。因此,这种永久性的学习模型增长系统可以被解释为一种人工通用智能AGI。但别指望任何奇点机器人的启示会接踵而至:这是一个纯粹的幻想,来自于对智能和技术的一系列深刻误解。然而,这种批评不属于这里。
**

若有收获,就点个赞吧
0 人点赞
