论文地址:量化数据库隔离性异常
本周早些时候,我们研究了实用部分群的概率有界腐化性和在最终一致性下陈旧读取的概率。当然,任何低于可序列化性的东西都可能导致异常——这意味着你最喜欢的RDBMS也不能免疫——特别是在默认的隔离级别下。
并发控制的“最高标准”是提供可序列化性,它具有任何完整性约束都将继续保留在数据库中的有价值的特性,前提是它最初是真的,并且每个事务在单独运行时都被编码以保留约束。不幸的是,在大多数平台上实现的确保可串行执行的算法在发生争用时可能会对性能产生有害影响。这些算法包括严格的两阶段锁(2PL),以共享或独占(或其他)模式在各种粒度上对数据项和索引进行锁,这些锁一直保持到事务结束。
在实践中,通常使用较弱的隔离级别(如Read Committed),这是默认设置。我们最终会牺牲性能和正确性…
它被广泛地描述为允许应用程序开发人员利用域知识,这意味着他们的特定代码将在低隔离度下正常工作;然而,没有一套原则或准则来确定给定代码是否如此。[17] 报告了使用产生不可序列化执行的SI部署应用程序的示例。因此在实践中,大多数开发人员实际上看到的是性能和正确性之间的权衡。使用强隔离(如序列化)运行将保护数据完整性,但会限制争用情况下的吞吐量;相反,弱隔离提供更好的性能,但有可能由于并发活动之间不希望的交错而损坏数据。(这里是快照隔离,Oracle的“可序列化”)。
ANSI SQL标准有四个隔离级别:可序列化、可重复读取、已提交读取和未提交读取。
每一层都被“定义”以排除低层允许的某些特殊异常行为。
然而,该标准并不强制要求特定的实现方法,并且在指定每个级别的行为方面存在一些众所周知的缺陷[3]。如果我们假设使用了众所周知的基于锁的并发控制算法,那么层次结构是有效的。
当不使用众所周知的基于锁定的并发控制算法时,事情就不那么简单了:
然而,正如我们所看到的,许多平台实现了用于并发控制的多版本算法。快照隔离被视为一个强大的算法(特别是,它防止了ANSI标准中描述的所有异常,如[3]所示,尽管它确实允许一个称为Write Skew的异常)。通常认为多版本读提交算法比SI弱,因为它允许不一致的读和幻影等异常。实际上,当应用程序被声明为可序列化时,有几个平台使用SI,当应用程序请求较低的隔离级别时,它们使用Read Committed的多版本形式。尽管如此,[3]表明SI并没有RC-MV那么严格地允许。
这意味着在一些病理病例中,在SI下可以看到比在Read-Committed下更多的异常。
微基准是基于两个表A和B构建的,三个事务changeA、changeB和changeAB分别更新表A、B和A和B。还为SI和Read提交的隔离级别构建了一个预测模型,以预测在不同的事务混合下会发生多少完整性冲突。
在图1中,我们展示了一个使用微基准的示例。我们测量了在不同隔离级别、特定平台上以及仅在MPL(提交事务的并发客户端数量)中违反完整性约束的速率。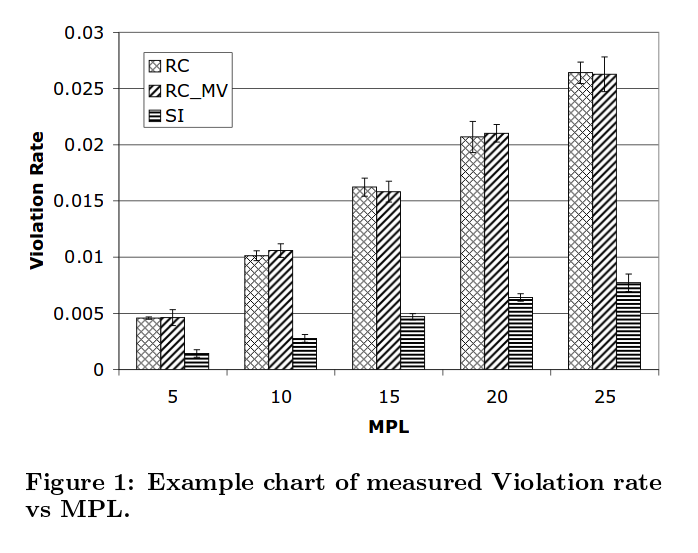
预测显示了正确的趋势,合理的精度如下所示: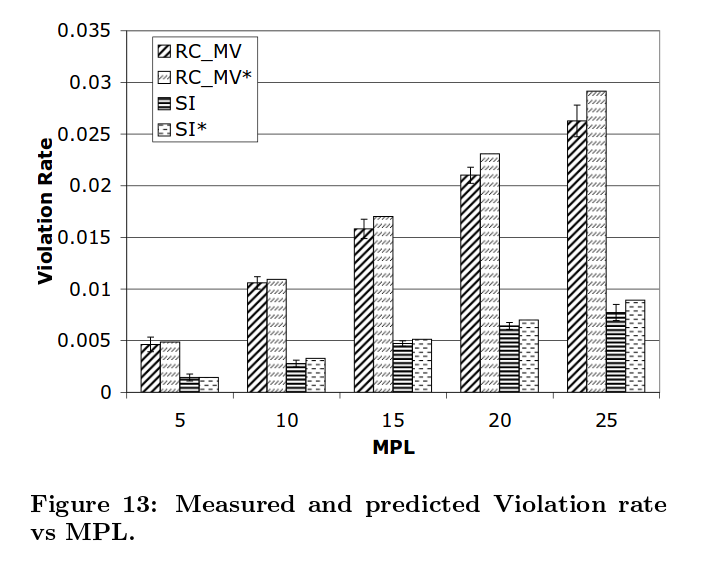
这项工作表明,考虑到对事务组合的理解,可以量化预测的违反完整性的数量,从而帮助开发人员了解在用正确性换取性能时他们放弃了什么。
另一个方向是将我们的预测模型从microbenchmark中的特定事务扩展到处理任意混合的应用程序代码,特别是可以应用到更实际的程序中。这将基于一个静态依赖关系图,该图显示哪些事务对处理同一项,但还需要仔细分析哪些交错实际上会导致违反完整性约束。
(当然,这一声明早于Bailis,Fekete等人的工作。关于I-Confluence,它确实继续调查哪些尝试导致违反完整性约束)。

若有收获,就点个赞吧
0 人点赞
