Swift for TensorFlow为TensorFlow提供了一个新的编程模型,它将图形的性能与急切执行的灵活性和表现性结合起来,同时在堆栈的各个级别上都非常注重提高可用性。为了实现我们的目标,我们在范围内进行(仔细考虑)编译器和语言增强的可能性,这使我们能够提供良好的用户体验。
对于用户,我们为TensorFlow设计了Swift,使其感觉像一个简单而明显的工具,可以用来编写“工作正常”的机器学习库和模型。然而,如果你看在幕后,这个用户体验的实现是一堆基本上独立的特性和子系统,它们组合在一起,感觉很自然,但也可以单独使用。
本文档提供了这些子组件的高层次视图,并描述了它们如何相互作用和组合在一起。本文件的目标是描述大局,而不需要广泛的主题专业知识。技术性的深入研究白皮书与代码本身的链接一样,都是为了提供一个更深入的视角。
我们将描述项目的这些部分:
Swift*
Swift是一种开放源代码的通用编程语言,它拥有庞大且不断增长的用户群。我们之所以选择Swift,是因为它有一个开放的语言设计过程,以及“Why Swift for TensorFlow”文档中详细说明的特定技术原因。我们假设大多数读者都不熟悉它,所以我们将在这里简要介绍一些关于它的其他重要内容。
Swift的开发始于2010年,其目的是将编程语言设计的最佳实践整合到一个系统中,而不是试图寻求学术上的新鲜事物或虔诚地宣传编程方法。因此,它支持多范式开发(如功能、面向对象、通用、过程等)的一体化系统,并将许多学术语言(如模式匹配、代数数据类型和类型类)中的知名概念引入前沿。它没有强烈鼓励开发人员用Swift重写所有代码,而是注重与其他语言的互操作性,例如,允许您直接导入C头文件并在没有FFI的情况下使用它们,以及(现在)在没有包装器的情况下使用pythonapi的能力。
Swift的大胆目标是从低级系统编程一直到高级脚本,重点是易于学习和使用。由于Swift需要易于学习和使用,但也需要强大的功能,它依赖于逐步披露复杂性的原则,这一原则会将复杂性的成本积极地影响到从复杂性中受益的人。结合高性能的“脚本语言感觉”对机器学习非常有用。
Swift设计的最后一个相关方面是,Swift语言的大部分实际上是在其标准库中实现的。”像Int和Bool这样的“内置”类型实际上只是标准库中定义的结构,用于包装魔术类型和操作。因此,有时我们开玩笑说Swift只是“LLVM的语法糖”。这种能力对我们的工作非常重要,因为TensorFlow模块中的张量类型只是TensorFlow的“语法糖”,PythonObject类型只是PyObject的语法糖!
还有很多关于Swift和大量在线内容的酷点。如果您有兴趣了解更多有关Swift编程的一般概念,请使用以下链接开始:
- Swift-Tour是对Swift的高级语法和感觉的一个简单的浏览,是更大的“Swift编程语言”一书的一部分。
- 值语义功能强大,在Swift代码中扮演着重要角色,正如在“用Swift中的值类型构建更好的应用程序”中所解释的那样[YouTube]。
- Swift支持经典的OOP,但它改编了Haskell类型系统的思想。这在“Swift中面向协议的编程”【YouTube】中有解释。
一个警告是:Swift在早期发展很快,所以在Swift 3(2016年发布)之前,任何引入都要小心。
Tensorflow
TensorFlow是一种广泛应用的机器学习框架。TensorFlow提供了一个基于图形的Python API,在这里您可以显式地构建图形操作,然后使用会话API执行一次或多次图形。此外,TensorFlow还添加了急切执行,允许您在Pythonic模式下逐个调用操作,但没有图形的好处。
在这种情况下,许多用户最初会认为Swift for TensorFlow只是一种直接的语言绑定。然而,Swift for TensorFlow允许您编写命令式的急切执行风格的代码,而Swift则提供显式图形api的全部性能。这背后的魔力是一个编译器转换,它可以分析您的代码并自动构建TensorFlow图和运行时调用。这件事的好处是TensorFlow“只起作用”,你根本不需要考虑图。
为了理解这是如何工作的,了解TensorFlow如何表示它的图是很重要的。TF_函数将张量计算表示为接受一定数量张量输入并产生一定数量张量结果的函数。TensorFlow图中的每个“op/”节点由一个字符串op name、一个输入值列表、一个属性列表(保证是常量)定义,并产生一些张量结果。每个输入和结果值都有一个与之关联的“dtype”,它描述元素类型(由TF_DataType enum指定),属性也有自己的简单类型系统(integer、string、float、shape等)。TensorFlow文档中描述了这方面的细节。
Swift for TensorFlow有一个低级语法,允许您使用不同的tfop语法直接访问任何op(该语法是一个可能会被修改的占位符)。例如,这里有几个在张量类型上定义的方法(为了表示而稍微简化了),您可以在Ops.swift中看到它们的完整定义。

虽然+示例非常简单,但卷积示例显示了这些函数所起的另一个重要作用:它们是处理“快速思考事物的方式”和“张量流思考事物的方式”之间的桥接的适配器。例如,Swift程序员可以将填充看作Swift枚举,即使TensorFlow使用字符串。类似地,strips可以作为一个强类型的4元元组传递,这段代码在作为数组传递给TensorFlow时处理删除该类型信息。
图形程序提取
图程序提取转换是实现TensorFlow集成无缝工作的关键技术。这就像编译器中的一个附加阶段,它使用静态分析来查找张量操作并将它们拆分为张量流图。在较高级别上,增强的Swift编译器如下所示: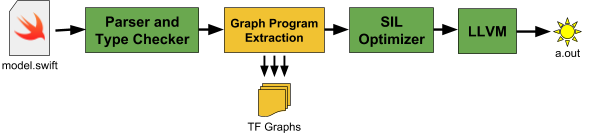
首先,编译器在代码中找到张量操作(由于上面描述的是低级tfop语法,这一点很简单)。接下来,它将设计高层抽象(如结构、元组、泛型、函数、变量等),这些抽象通过一个称为“deabstraction”的过程连接张量操作。在去抽象后,张量运算通过SSA数据流边缘直接连接在一起,并嵌入到Swift中间语言(SIL)表示的控制流图中。此代码主要在TFDeabstraction.cpp中实现。
一旦张量运算被取消,我们称之为“分区”的转换将从程序中提取图形运算,并构建一个新的SIL函数来表示张量代码。除了从主机代码中删除tensor操作外,还将向新的运行时库中注入新的调用,以启动TensorFlow,集合以收集任何结果,并在运行时在主机和tensor程序之间发送/接收值。大部分图形程序提取转换本身位于TFPartition.cpp中。
一旦张量函数形成,它就会被应用一些转换,并最终使用TFLowerGraph.cpp中的代码被发送到张量流图。在TensorFlow图形成之后,我们将其序列化为protobuf,并将这些位直接编码到可执行文件中,使其易于在程序运行时加载。
我们不知道有任何其他系统使用这种方法,但我们的实现借鉴了许多相关的概念性工作,包括程序切片、抽象解释,并作为静态编译器分析实现。请参阅我们详细的图形程序提取白皮书,以了解有关所有这些工作原理的更多信息。
最后,虽然TensorFlow是我们构建这个基础结构的原因,但它的算法独立于TensorFlow本身:同一个编译器转换可以从主机程序中提取任何通过发送和接收进行通信时异步执行的计算。这是有用的,可以应用于任何表示计算为图的对象,包括其他ML框架、其他类型的加速器(用于密码学、图形、转码等)和基于图抽象的通用分布式系统编程模型。我们有兴趣在未来探索这种算法的新应用。
TensorFlow模块
TensorFlow模块是在Swift程序中导入TensorFlow后得到的代码库。它用Swift编写,位于stdlib/public/TensorFlow目录中。它实现了一些不同的功能:
用户api:张量、ShapedArray等。
正如我们在关于Swift一节中所描述的,Swift的许多经验实际上是在标准库中定义的,而不是编译器本身。同样,由于我们的图形程序提取方法非常通用和灵活,TensorFlow模块定义了大多数用户体验和使用TensorFlow的感觉。关于用户体验的设计选择并没有融入到语言或编译器中,这给了我们在TensorFlow库中试验不同方法的很大空间。
我们最重要的设计限制是,我们不希望使用Swift for TensorFlow的用户编写意外导致主机和加速器之间不必要的来回复制的代码。因此,我们选择实现一个用户模型,该模型提供两个主要概念:“数组”和“张量”。这两个都表示n维值的张量,但是我们系统中的“数组”应该被认为是宿主程序中的数据,而“张量”是主要由张量流管理的值。除此之外,这意味着“数组”符合MutableCollection和RangeReplaceableCollection,因此具有普通的集合api,但是Tensor具有与TensorFlow操作相对应的方法和运算符。
“数组”和“张量”都动态排列了n维版本,分别命名为ShapedArray和Tensor。我们也在试验静态排序版本(在Swift.Array之上组成的Array2D、Array3D等)和(Tensor1D、Tensor2D、Tensor3D等)。下面是几个简单的例子,展示了张量和shapedaray:
Tensor的实现基于构建TensorFlow图节点的#tfop magic语法,并在Tensor.swift、Ops.swift、RankedTensor.swift.gyb和TensorProtocol.swift中定义。ShapedArray的实现遵循实现Swift集合时使用的标准技术,主要在ShapedArray.Swift和RankedArray.Swift.gyb中定义。除了类型的张量族之外,我们还尝试在张量流图节点之上为数据管道、资源、变量和其他可以表示为图节点的事物构建抽象。
Extraction的运行时入口点
图程序提取算法将张量运算分解成张量流图,张量流图被序列化成protobuf并编码成程序的可执行文件。它重写宿主代码以插入对“start tensor program”、“finish tensor program”和“terminate tensor program”运行时入口点的调用,这些入口点是根据TensorFlow api在CompilerRuntime.swift文件中实现的。
我们的运行时目前有几个支持的驱动TensorFlow的路径,包括启用XLA的路径、经过经典执行器的路径、使用“紧急执行”运行时入口点的路径,以及一些对云TPU配置的专门支持。这一点仍在迅速发展,并将不断发生变化。
编译器和运行时模型中最重要的未实现部分是支持在共同执行的异步主机和TensorFlow程序之间发送和接收数据。这是我们模型中非常重要的一部分,它允许您透明地对张量值使用主机调用(例如打印或Xcode Playground值记录),并自由地混合主机和加速器代码。这是今后几周要优先执行的任务。同时,我们完全支持在tensor程序的开始和结束时传递和接收的参数和结果。
自动微分
自动微分(Automatic differentication,AD)是所有机器学习框架都希望实现的一种强大技术,因为梯度对于这项工作非常重要(例如,使用SGD)。TensorFlow将自动微分作为TensorFlow图转换来实现,但我们希望部署更强大的技术来改善用户在故障情况下的体验,从而能够区分自定义数据结构、递归和高阶微分。因此,我们为Swift构建了一个独立的广告特性:它完全独立于AD的标准TensorFlow实现,也完全独立于Swift中的TensorFlow支持。
其工作方式是让Swift AD支持任意用户定义的类型。Swift for TensorFlow以此为基础,使其张量类型符合广告系统,允许他们按您的预期参与。这方面的一个好处是,对非张量数值分析感兴趣的Swift程序员可以将AD用于对他们的工作很重要的任何其他类型。

Swift中的自动微分是用静态分析实现的编译器IR转换。当在反向模式下对一个函数进行微分时,编译器生成一个单独的函数,其中包含相应的“原始代码”和“伴随代码”,后者反过来计算模型输出相对于输入参数的偏导数。由于我们希望Swift中的AD在所有用例中都是完全通用的,并且允许自定义数据结构和任意函数,所以编译器不会对单个数学操作进行假设。相反,开发人员指定要用于函数的伴随代码,以及两个反向传播的伴随值应如何组合-全部用纯Swift代码表示。编译器将区分并链接这些函数的任何使用。
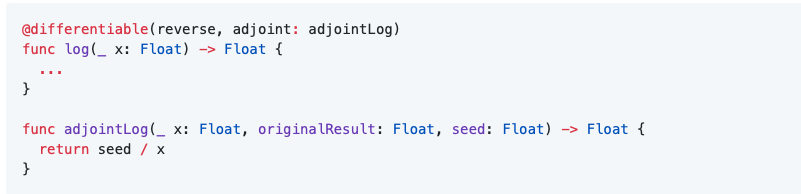
我们对函数使用@differentiable属性来指定函数的自定义伴随。@differentiable的第一个参数指定函数是使用forward模式(还不支持)还是reverse模式AD可微。第二个参数指定一个伴随函数,它接受原始参数、中间原始值、原始结果和种子(从另一个函数向后传播的伴随值)以及计算梯度。
除了使运算符可微外,编译器还需要知道如何组合前向传递中“扇出”的两个导数(通常是通过求和和和积规则,但有时也要广播)以及如何创建零梯度。类型可以通过实现与矢量数字协议的一致性来指定自定义行为,我们已经使所有浮点类型一致。当其标量类型为FloatingPoint时,张量也符合。有了这个基础,只要沿着数据流调用的函数是可微分的,用户就可以请求任何函数在向量数值类型上的梯度。当数据流中的任何操作不可微时,例如调用不可微函数或分配给全局变量,编译器将产生编译时错误并指向相关问题的位置。
我们提供了两个用于请求函数梯度的微分运算符:#gradient()和#valueAndGradient()。前者接受一个函数并返回另一个计算原始函数梯度的函数。后者接受一个函数并返回另一个函数,该函数计算原始函数的结果和梯度。可选的变量参数wrt:指定要区分的参数(自)的索引。下面的示例演示如何针对某些参数请求可微函数的梯度。
今天,我们已经有了基本的基础设施来支持带有定义良好的伴随词的直线代码上的反向模式AD,但是我们计划支持完整的控制流,并与社区讨论对正向模式广告的需求。要了解有关自动差异化的更多信息,请参阅Swift中的自动微分化。
Python互操作性
机器学习社区的很大一部分使用Python,我们都希望充分利用Python提供的海量数据科学、可视化和其他随机包来完成我们的工作。我们可以做一些事情来减轻从Python编程到Swift for TensorFlow编程的负担。例如,Swift已经支持命令行解释器,并且#!编写工作流脚本。我们相信伟大的Jupyter笔记本集成是很重要的,因为它是许多人工作流程的一部分。
为了进一步平滑转换,我们可以直接从Swift调用pythonapi,这允许ML程序员继续使用数据科学和其他有用的api,同时也可以从Swift中获得TensorFlow代码的好处。下面是一个实际情况的示例,其中注释掉了显示纯Python语法以供比较的代码:
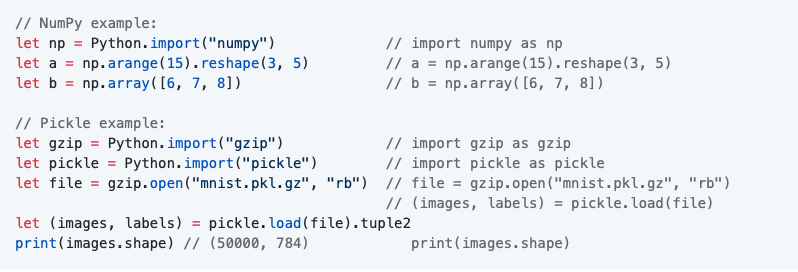
如您所见,这里的语法非常接近:主要区别在于Swift要求在使用之前声明值,并且我们决定将Python内置函数(如import、type、slice等)放在Python下。命名空间(以避免混淆全局范围)。这不需要开关或任何其他包装,所以它是超级容易使用。
此功能在不对编译器或语言进行特定于Python的更改的情况下完成—它完全在Python.swift文件中实现。这意味着,如果在将来变得重要,我们可以使用相同的技术直接与其他动态语言运行时(例如Javascript、Ruby等)集成。Python支持也完全独立于我们在项目其余部分构建的其他TensorFlow和自动区分逻辑。它是Swift生态系统的一个非常有用的扩展,它可以独立运行,对于服务器端开发或其他任何希望与现有pythonapi互操作的东西都很有用。
要了解更多关于这是如何工作的信息,请查看Python互操作性的深入研究,或者浏览GitHub上Python.swift中的实现。
未来方向
我们专注于完成TensorFlow模型的基本Swift,获得更多使用它的经验,并开始构建开发人员社区。尽管如此,我们仍然有很多关于如何推动事情发展的想法,当然也欢迎更多的想法!例如:
- 可用性检查:Swift有一个强大的模型来处理有条件可用的功能,称为“可用性检查”,TensorFlow生态系统也有许多类似的挑战:许多操作只在某些设备上可用,一些操作只在某些数据类型上工作,一些部署目标(如XLA和TFLite)有额外的限制。我们想考虑扩展可用性检查或构建一个类似的系统,以允许我们静态地诊断您正在部署的硬件和配置对Tensor ops的误用。我们应该能够直接指向有问题的代码行,并给出有关我们检测到的问题的详细错误消息。
- 部署支持:我们想探索一个模型,其中部署的模型在代码中显式声明,包括它们打算支持的设备。这样可以改进可用性检查(如上所述),允许更好地管理用于推理的接口,消除某些类的错误,并且应该直接支持希望更新权重值而不重新编译和更改代码的部署工作流。我们有一个初步的计划,如何追求这一点,但需要发展出更多的想法。
- Shape检查:Shape错误是机器学习研究和生产效率的一个持续性问题。我们已经从TensorFlow图形构建API中得到了一些基本的形状检查,但是我们需要在一级支持上进行投资,以便在高级API边界而不是在这些API的实现中生成更好的诊断和诊断更多的错误。我们对这项工作有初步的想法,但还需要进一步探讨。
命名维度:经常要求的特性是能够在张量中使用符号维度名称。这里可以探讨几种不同的可能模型。
区分不透明闭包:静态区分函数要求编译器可以看到函数体。但是,这限制了微分运算符的表达能力,例如,用户不能将梯度运算符应用于具有函数类型的函数参数,因为编译器不能总是看到原始函数的主体。我们将讨论引入一个新的函数约定的可能性——当一个可微函数被传递时,一个指向其原函数和伴随函数的指针被传递。这使得编译器可以直接调用primal和adjoint,而无需查看函数声明。这对于类和协议方法很重要。
量化支持:我们相信如果将定点量化工具集成到编译器中,我们可以获得更好的用户体验,这将有助于将量化集成到训练过程中。

若有收获,就点个赞吧
0 人点赞
