学习型索引结构的案例 Kraska et al., arXiv Dec. 2017
在今天的论文选择中,Kraska等人提出了一个强有力的理由,将应用机器学习纳入未来数据库系统的基本技术列表中。我想不出一个更好的方式来开始新的一年,而不去想这种新旧结合的方式——既有的数据库系统研究和机器学习模型——以及这一切对未来的系统软件意味着什么。我将把我的总结分成两篇文章(今天和明天),这样我们就可以关注今天的大局,明天再深入讨论细节。
我最喜欢这篇论文的地方是它为我们打开了一扇大门,让我们可以用不同的方式来思考系统软件的组件。通过巧妙地构建索引问题,作者展示了在数据管理系统内部使用机器学习的潜力。在当前实现的适用性方面存在一些限制(我们将讨论到),但即使这样,在同时在内存中节省一个数量级的同时,速度提高了70%的结果还是值得注意的。记住,这些改进是针对经过几十年优化的算法而获得的。不过,我不想太直接地把索引用例的细节挂在嘴边,我想先谈一下大局:
我们认为,通过学习的模型替换数据管理系统的核心组件的想法对未来的系统设计具有深远的影响,这项工作只是提供了一个可能的一瞥。
什么时候(在系统软件中)用机器学习模型代替手工设计的数据结构和/或算法有意义?我目前能想到的解决这个问题的最佳类比是个性化。早期的网站和应用程序向所有人显示相同的内容。但今天,大多数网站都为你提供了高度个性化的体验,你发现这对他们和(希望!)为你。一般的体验可能不错,但个性化的体验更好。在这个类比中,相当于系统软件世界中的一个用户,我认为是一个工作负载,其中一个工作负载是数据和访问模式的组合。有一天我们可能会这样说:“早期的系统软件对所有工作负载使用相同的通用配置、数据结构和算法。但如今,大多数系统都在学习和优化其运行的特定工作负载。”
去年我们看了几次,其中一个很容易理解的例子是配置:大多数系统都有一个默认配置,可以跨越一系列的工作负载,但是调整配置以适应您的特定工作负载可以带来很大的性能改进。这就是我认为我们正在寻找的模式:当系统的性能对它运行的特定工作负载的特性敏感时,工作负载个性化有意义,如果我们事先知道这些特性,我们就可以为它们优化系统。坦白地说,几乎所有的系统软件都对其上运行的工作负载的特性敏感!这也让我非常牢记“没有免费的午餐定律”:“……如果一个算法在某一类问题上表现良好,那么它必然会在所有剩余问题集上的性能降低的情况下为此付出代价。”
还需要考虑一些其他因素:工作负载个性化需要在系统的某个有限制的组件(可以抽象为函数的组件)中进行,并且我们需要一种保留保证/遵守约束的方法。考虑到现在概率数据结构的使用,我们已经习惯了它们是近似的(作为一个学习函数)。也许最著名的是Bloom过滤器,它告诉我们一个元素是否可能在一个集合中。布鲁姆过滤器有一个重要的保证-没有假阴性。在许多用例中,学习一个“只有很小概率”为假阴性的函数是完全不一样的。事实证明,作者对这个问题有一个很好的解决方案,我们明天再看!
要充分发挥工作量个性化的潜力,需要一种在线学习/优化方法,因为:
为每个用例构建专门解决方案的工程工作通常太高了……机器学习为学习反映数据中模式和相关性的模型提供了机会。
本文将该方法应用于专业索引结构的自动综合,提出了学习索引的概念。
关于基于CPU、GPU和TPU的架构
本文中的实现是使用cpu完成的,但还有一个原因是神经网络风格的模型在未来会变得越来越有吸引力:它们可以在gpu和tpu上非常高效地运行。虽然CPU的性能正在趋于稳定,但NVIDIA预计到2025年,GPU速度将提高1000倍。随着CPU/GPU/TPU单元的更紧密集成以降低移交成本,GPU/TPU性能曲线将成为在未来十年内实现最大性能的曲线。
引入学习(范围)索引
**
本文主要研究只读内存分析工作负载。在今天的分析数据库中发现的一个典型的B-树索引中,B-树提供了从查找键到排序记录数组中位置的映射。索引包含每N个键的条目,例如,页面中的第一个键。这种B树的保证是,如果密钥存在,它将在返回位置的“页面大小”内找到。这是一个从键到位置的函数,有错误限制保证。我们可以学习函数,但是保证呢?
乍一看,可能很难与其他类型的ML模型提供相同的错误保证,但实际上它非常简单。B树只对存储的数据提供这种保证,而不是对所有可能的数据提供这种保证。对于新的数据,B-树需要重新平衡,或者在机器学习术语中重新训练,以便仍然能够提供相同的错误保证。这大大简化了问题:最小和最大误差是模型相对于训练(即存储)数据的最大误差。
如果我们对每个键执行模型,并记住最坏的预测,那么我们知道对任何存在的键的查找都必须在这些范围内。因此,使用机器学习模型成为可能,并将O(log n)B树查找转换为常量操作。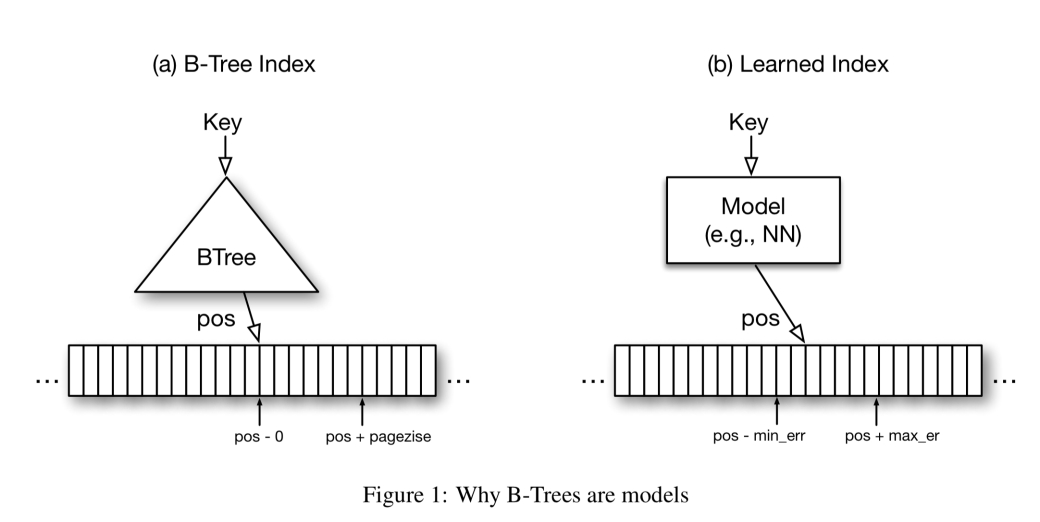
遍历大小为100的单个B树页大约需要50个周期(任何缓存未命中),我们需要这些遍历中的log100N来查找具有N个键的表。相比之下,在NVIDIAs最新的Tesla V100 GPU上,你可以在30个周期内进行100万次神经网络操作。在现代的cpu上,我们有一个大约log100N 400个算术运算的预算来打败B-树。
预测排序数组中键位置的模型有效地近似于累积分布函数(CDF):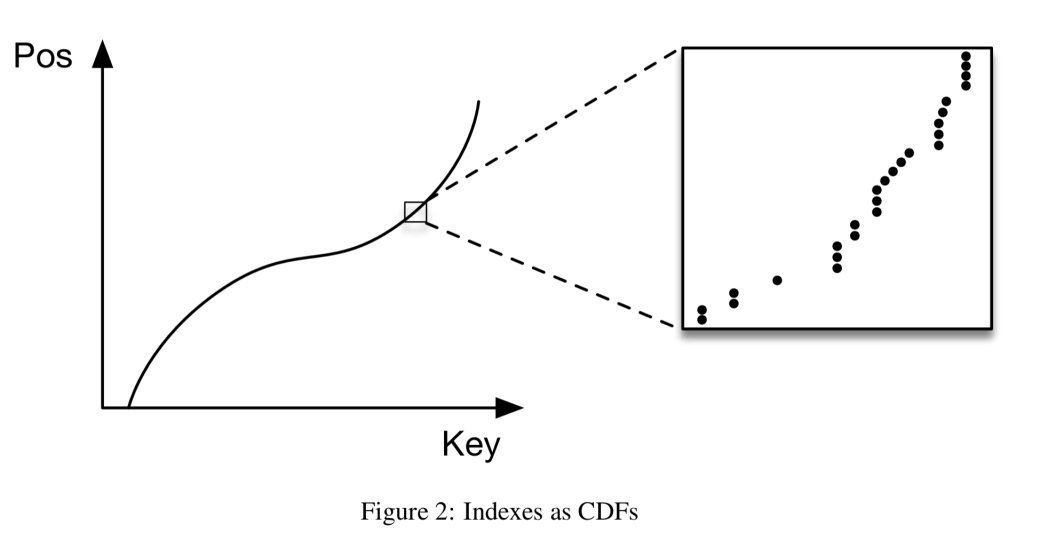
…估计数据集的分布是一个众所周知的问题,学习的索引可以从几十年的研究中受益。
一个不成熟的第一个实现使用一个两层完全连接的神经网络,每层32个神经元,达到每秒1250个预测。B-树仍然快了2-3倍!为什么?
Tensorflow调用开销(特别是在Python前端)太大了。
B-树非常有效地“过拟合”数据。相比之下,学习的CDF可以很好地近似一般的形状,但在单独的数据实例级别上效果不太好(如上图中的标注所示)。“许多数据集都有这样的行为:从顶部看,数据分布看起来非常平滑,而随着我们放大的程度越来越大,由于个体水平上的随机性,估计CDF就越困难。”这使得单个神经网络的“最后一英里”更难。
我们不想最小化平均误差(对于ML优化来说是典型的),而是希望最小化最小和最大误差界限。
B-树具有极高的缓存效率,而标准的神经网络则不然。
当然,如果我们停在这里,那就不是什么故事了。但在明天的文章中,我们将讨论作者为克服这些问题而开发的学习索引框架(LIF)。除了范围索引之外,我们还将研究点索引(本质上,学习散列映射的替代方法)和存在索引(学习Bloom过滤器的替代方法)。

若有收获,就点个赞吧
0 人点赞
