论文地址:简单的测试可以防止大多数关键故障:分布式数据密集型系统中的生产故障分析 Yuan et al. OSDI 2014
简单的测试可以防止大多数关键的失败。多亏了我第一次听说这件事的凯蒂·麦卡弗里。作者研究了来自5个数据密集型分布式系统(Cassandra、HBase、HDFS、MapReduce、Redis)的198个随机抽样的用户报告故障。这些系统中的每一个都是为了容忍组件故障而设计的,并广泛应用于生产环境中。
对于考虑到的每一个故障,我们都仔细研究了故障报告、用户和开发人员之间的讨论、日志和代码,并手动复制了73个故障,以便更好地理解发生的具体表现。
本文有很多非常有趣的发现和立即适用的建议。但对我来说,最好的发现是,故障越严重(影响所有用户、关闭整个系统等),根本原因往往越简单。事实上:
几乎所有的灾难性故障(总共48次–92%)都是由于对软件中明确表示的非致命错误的错误处理不当造成的。
其中大约有三分之一(这些故障会让整个生产系统记住)是由错误处理中的小错误引起的。它们可以通过简单的代码检查来检测,甚至不需要对系统有任何特定的了解。以下是您要检查的三件事:
- 忽略错误(或只包含日志语句)的错误处理程序。此示例导致HBase中的数据丢失:

- 注释中带有“TODO”或“FIXME”的错误处理程序。此示例关闭了一个4000节点的生产群集:

捕捉抽象异常类型(如Java中的异常或可抛出异常)并随后采取激烈操作(如中止系统)的错误处理程序。此示例关闭了整个HDFS群集:
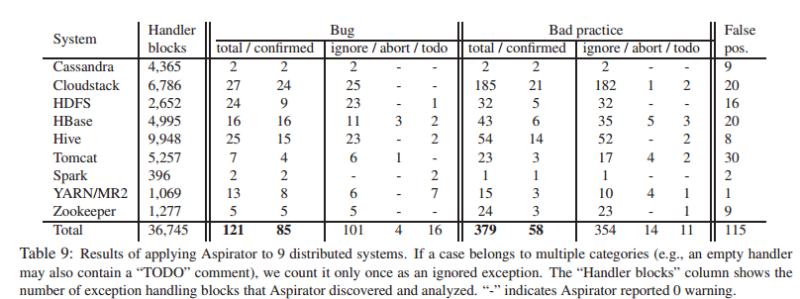
对于这三个场景,作者构建了一个名为Aspirator的静态检查工具,并使用它来检查一些真实的系统,包括研究中的系统。
如果使用Aspirator并修复捕获的错误,我们研究的Cassandra、HBase、HDFS和MapReduce灾难性故障的33%都可以预防。
使用Aspirator检查下表所示的9个系统,发现500个新的错误和不良实践,以及115个误报。其中171个被报告为bug返回给开发人员,截至论文发表时,143个已经被开发人员确认或修复。
另外57%的由错误处理导致的灾难性故障确实需要一些特定的系统知识来检测,但对其中的很大一部分来说并不是很多…
在23%的灾难性故障中,虽然错误处理中的错误是系统特有的,但它们仍然很容易被发现。更正式地说,在这些情况下,错误处理将在错误处理阶段通过100%语句覆盖率测试暴露出来……一旦错误处理代码中有问题的基本块被触发,故障就一定会暴露出来。
最后34%的灾难性故障确实涉及错误处理逻辑中的复杂错误。系统地根除这些错误要困难得多,但是嘿,除掉另外三分之二可能引发灾难的错误是一个很好的开始!
其他一般发现
**
失败大多很容易重现
大多数生产故障(77%)可以通过单元测试再现。
如果您确实需要一个实时系统来重现故障,那么您几乎肯定可以使用三节点系统:
几乎所有(98%)的故障都保证出现在不超过3个节点上。84%将在不超过2个节点上显示…。不必有大型集群来测试和重现故障。
此外,大多数失败需要不超过三个输入事件才能使它们显式。其中74%是确定性的——也就是说,只要输入正确的事件序列,它们就一定会发生。你需要的信息可能在日志里。
对于大多数(84%)的故障,它们的所有触发事件都会被记录下来。这表明,仅根据现有的日志消息就可以确定地重播大多数故障。
- 但是日志是有噪声的,每个故障打印的日志消息的中值是824,这是一个最小的配置和最小的工作负载,足以重现故障。

若有收获,就点个赞吧
0 人点赞
