论文地址:简化云编程:伯克利无服务器计算视图Jonas等人,arXiv 2019
十年前,伯克利发表了《伯克利云计算观》一文,预测云计算的使用将加速。今天的论文选择被称为它的逻辑继承者:它预测无服务器计算的使用将加速。更准确地说:
……我们预测无服务器计算将在未来的云计算中占据主导地位。
感谢来自Google、Amazon和Microsoft等公司的评论员,因此可以合理地假设主要的云提供商至少对这里的视图有一些输入。这个讨论是相当高层次的,而且在某些方面,它给伯克利带来了一种公关的感觉(甚至还有一个可爱的集体作者电子邮件地址:serverlessview at Berkeley.edu),但是它的35页足够让我们感兴趣,可以让我们深入了解…
基本结构如下。首先,我们得到了定义无服务器的必要尝试,一起讨论了它为什么重要。然后,作者研究了当前的一些限制(参见“无服务器计算:前进一步,后退两步”),然后提出了未来几年需要改进的地方。论文最后对无服务器的常见谬误(和陷阱)以及一组预测做了很好的总结。我要从那里开始!
预测、谬误、陷阱
谬论:云功能实例的每分钟成本比具有类似容量的常规VM实例高出7.5x,因此无服务器云计算比有服务器云计算更昂贵。
反驳:从一个函数中获得的等效功能远远超出了使用单个VM实例所能实现的功能。另外,没有活动就不付钱。将两者结合在一起意味着无服务器可能最终会降低成本。
预测(对我来说,这是整篇论文中最有趣的一句话!):
我们看不出无服务器计算的成本应该高于无服务器计算的根本原因,因此我们预测计费模型将不断发展,几乎任何规模的应用程序在无服务器计算中的成本都不会越来越低。
但是是的,按实际使用计费意味着成本不太可预测(希望是一个好方法!)比“永远在线”的解决方案。
谬论:由于函数是用高级语言编写的,因此在无服务器计算提供程序之间移植应用程序很容易。(有人真的认为无服务器增加了可移植性吗?我听到的所有谈话都与此相反。
反驳/陷阱:与服务器计算相比,无服务器计算的供应商锁定可能更强。(是的,因为您的函数也依赖于事件模型和后端服务集)。
预测:“我们预计将创建新的BaaS存储服务,以扩展在无服务器计算上运行良好的应用程序类型,”以及“无服务器计算的未来将是促进BaaS。”
陷阱:(今天)“很少有所谓的‘弹性’服务能够满足无服务器计算的真正灵活性需求。”
谬论:云功能无法处理需要可预测性能的低延迟应用程序
反驳:如果您预先预热/保持一个功能池就绪,那么它们就可以(将这一思想与“我们看不出无服务器计算的成本应该高于服务器计算的根本原因…”结合起来)
预测:
虽然服务器云计算不会消失,但随着无服务器计算克服了当前的局限性,这部分云的相对重要性将下降。无服务器计算将成为云时代的默认计算模式,在很大程度上取代了服务器计算,从而结束了客户机-服务器时代。
(那么新的类型是什么?客户端功能架构??)还有一件事:“我们希望无服务器计算比有服务器计算更容易安全地编程…”
无服务器的动机
简单地说,无服务器计算=FaaS+BaaS。在我们的定义中,要使服务被认为是无服务器的,它必须在不需要显式配置的情况下自动扩展,并根据使用情况计费。在本文的其余部分,我们将重点讨论云功能的出现、演变和未来…
如果你分析得恰到好处,你就可以在等式中找出无服务器平台的另一个重要部分:在连接FaaS和BaaS的“+”符号中,是一组平台事件,可以用来将两者粘合在一起,它们在我心目中是整个模型的重要部分。
无服务器提供的一个关键功能是将用户的责任转移给云提供商,以解决许多运营问题: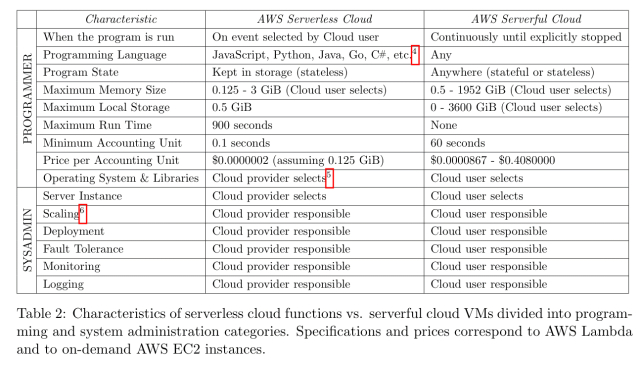
作者列出了无服务器计算和服务器计算之间的三个重要区别:
- 解耦合计算与存储:存储与计算规模分开,独立配置和定价。(等一下,EBS处于“服务器”模式时,我不明白吗??)
- 在不管理资源分配的情况下执行代码。
- 按使用的资源而不是分配的资源的比例支付。
无服务器计算和前几代PaaS之间的根本区别在于自动缩放和相关的计费模型:
- 比多种自动缩放技术更精确地跟踪负载,
- 一直缩小到零
- 以更细粒度的方式计算代码执行所花费的时间,而不是为执行程序而保留的资源。
但是,还有一点我无法理解:“通过允许用户携带自己的库,无服务器计算可以支持比PaaS服务更广泛的应用程序,PaaS服务与特定的用例紧密相连。”我非常确定,我可以从一个函数引用的任何库/包,我也可以来自my Node.js/Java/Ruby/Python/…app的引用!
根据2018年的一项调查,当今最流行的无服务器应用如下: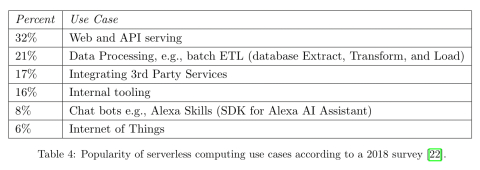
当前限制
本文的第3节研究了一组五个应用程序,以了解当前的优缺点。下表对这些进行了总结。使用functions-as-a-service实现数据库是一个坏主意。
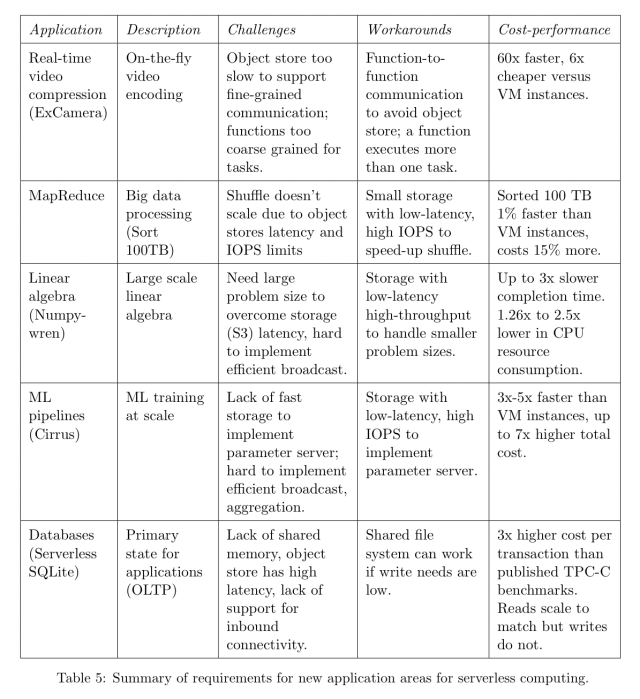
其中几个工作负载的一个共同点是资源需求在执行过程中可能会有很大的变化,因此尝试利用细粒度的自动缩放无服务器产品是很有吸引力的。
这项工作目前存在四个主要限制:
- 对细粒度操作的存储支持不足
- 缺乏细粒度的协调机制(标准事件机制中的延迟太高)
- 标准通信模式的性能很差(可能是O(N)或O(N^2),这取决于用例,但是“N”通常会增加很多,因为我们拥有的功能比vm多得多。
- 冷启动延迟导致不可预知的性能
对未来的建议
第一个建议(§4.1)涉及支持具有特定资源需求(例如访问加速器)的无服务器功能。
一种方法是使开发人员能够显式地指定这些资源需求。然而,这将使云提供商更难通过统计复用实现高利用率,因为它对功能调度设置了更多的限制……更好的替代方案是提高抽象级别,让云提供商推断资源需求,而不是让开发人员指定它们。
因此,场景A开发人员(例如)通过元数据显式指定函数需要GPU,场景B平台通过检查推断函数需要GPU。我不清楚这对进度限制有什么影响!尽管通过巧妙的推理,我们可能更接近真实的资源需求,但是我们知道开发人员在发出显式请求时往往会过度提供资源。我们必须将抽象级别提高到接近SLOs的水平,才能让事情变得真正有趣,即使这样,云平台也需要有多种可行的策略来选择,以满足这些目标。在$4.5节中,我们还讨论了这个主题,我们发现“或者,云提供商可以监视云功能的性能,并在下次运行时将它们迁移到最合适的硬件上。“
- 第二个建议是向平台公开功能通信模式(计算图),以便这些信息可以通知布局。AWS Step函数是朝这个方向迈出的一步;)。
第4.2节讨论了需要更多存储选项。特别是,用于功能(例如,内存中的数据网格)和无服务器持久存储之间协调的无服务器临时存储,这意味着访问低延迟持久共享密钥值存储。相关的ask是用于功能协调的低延迟事件/信令服务。
在这里再次指出,与其试图在未来的云平台上复制旧的应用程序开发模式,使用类似Bloom的无服务器方法及其底层的CALM哲学将提供我们在这里寻找的大部分内容:具有自然公开的计算图的更高级别抽象,以及平台作出知情调度和自动缩放决策的能力。
通过研究新的轻量级隔离机制、使用unikernels和延迟加载库,可以最大限度地缩短启动时间。
第4.4节讨论了安全挑战:细粒度提供对私钥的访问、跨功能的权限委托,以及通过网络通信模式的信息泄漏(这些模式更能揭示大量细粒度组件)。

若有收获,就点个赞吧
0 人点赞
