论文地址:面向多重性的数据库 Marzoev等人,HotOS’19
web应用程序的典型备份存储包含许多用户的数据。应用程序代表经过身份验证的用户进行查询,但由应用程序本身来确保用户只看到他们有权看到的数据。
任何前端都可以访问整个存储,而不管应用程序用户使用结果如何。因此,前端代码负责保护用户数据的权限检查和隐私保护转换。这是危险的和容易出错的,并且已经导致了许多实际的错误…可信计算基础(TCB)有效地包括了整个应用程序。
multiverse数据库背后的核心思想是将数据访问和隐私规则推入数据库本身。数据库负责授权和转换,应用程序只负责在数据库调用中验证和正确委派已验证主体。这样的设计排除了一整类应用程序错误,保护私有数据不被意外泄漏。
在共享后端存储接口上指定和透明地强制执行一次访问策略将更安全、更容易。尽管are数据库的状态具有专门为此目的而设计的安全功能,例如行级访问策略和视图授予,但这些功能对于许多web应用程序来说过于受限。
特别是,依赖于数据的隐私策略可能不适合行或列级别的访问控制,并且可能允许公开传统访问控制将阻止的聚合或转换信息。
对于多维数据库,每个用户都会看到一个一致的“平行维度”数据库,其中只包含允许用户查看的数据。因此,应用程序可以发出任何查询,我们可以放心,因为它只会看到允许的数据。

当然,最具挑战性的事情是有效地维护所有这些”平行维度“。我们将讨论这个问题,但首先让我们看一些隐私策略的示例以及如何表达它们。
表达隐私政策
在原型实现中,策略用类似于Google Cloud Firestore安全规则的语言表示。策略只需要是给定更新的记录数据和数据库内容的确定函数。现在支持以下内容:
- 行抑制策略(例如,排除与此模式匹配的行)
- 列重写策略(例如转换/掩码值)
- 支持基于角色的组策略(即依赖于数据的访问控制)
- 聚合策略,它限制一个世界仅以聚合或差异私有形式查看某些表或列。
考虑一个课堂讨论论坛应用程序(例如Piazza),在该应用程序中,学生可以将匿名的问题发送给其他学生,但不能将匿名的问题发送给教师。我们可以结合行抑制和列重写来表达此策略:
也许我们想让助教在他们教的课程中看到匿名的帖子。我们可以通过成员条件定义组,然后将策略附加到该组:
写入策略(当前实现中不支持)允许指定允许的更新。例如:
聚合策略可用于将任何匹配的聚合重写为差异专用版本。这一点的基础可能是,例如,Chan等人的“私人和持续发布统计数据”。将这些政策与其他政策结合起来仍然是一个开放的研究问题。
管理多维
多维数据库由一个基本维度(它表示没有应用任何读取端隐私策略的数据库)和许多用户维度(它们是数据库的转换副本)组成。
为了获得良好的查询性能,我们希望预先计算每个用户的Universe。如果我们天真地那样做,我们最终会有很多领域需要存储和维护,而存储需求本身将是令人望而却步的。
一个空间和计算效率高的多维数据库显然不能将所有用户维度全部实现,必须支持对用户维度的高性能增量更新。因此,它需要支持高性能更新的部分具体化视图。最近的研究提供了这个丢失的密钥原语。具体来说,可伸缩的并行流数据流计算系统现在支持部分有状态和动态变化的数据流。这些想法使得建立一个高效的多元维度数据库成为可能。
因此,我们将基础维度中的数据库表作为数据流的根顶点,并且随着基础维度的更新,记录将通过流移动到用户维度中。当数据流图中的边跨越通用边界时,将插入任何必要的数据流运算符以强制执行所需的隐私策略。所有适用的策略都应用于转换到给定用户群的每个边缘,因此无论数据通过哪个路径到达该边缘,我们都知道策略将被强制执行。
我们可以动态地构建数据流图,在第一次执行查询时为用户范围扩展流。通过在两个维度之间共享计算和缓存数据,可以减少基本更新所需的计算量。将其实现为一个联合的部分状态数据流是安全地执行此操作的关键。
通过将所有用户的查询作为一个联合数据流进行推理,系统可以检测到这样的共享:当存在相同的数据流路径时,它们可以合并。
逻辑上不同但功能上等价的数据流顶点也可以共享一个公共的后备存储。在给定的维度中,任何到达这样一个顶点的记录都意味着维度可以访问它,因此系统可以安全地公开共享副本。
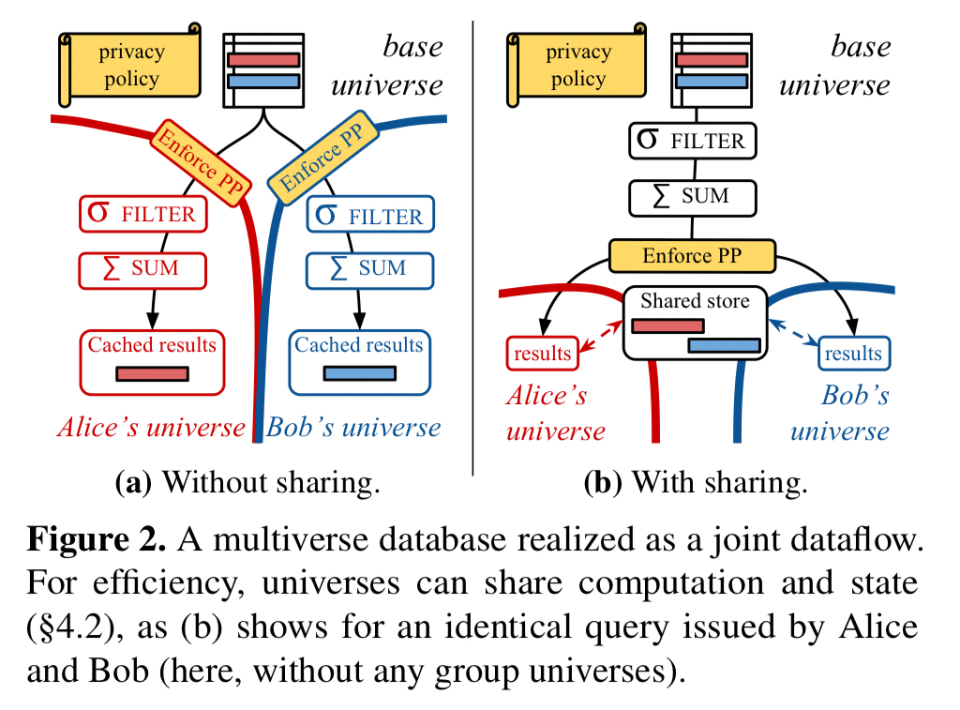
正如用户维度可以按需创建一样,非活动维度也可以按需销毁。在封面下,这些都是数据流图的操作,部分有状态的数据流可以在不停机的情况下支持这些操作。
原型评估
作者基于Noria数据流引擎构建了这些思想的原型实现。大约有2000行锈迹。一个Piazza风格的班级论坛讨论应用程序,有1百万个帖子,1000个班级,以及允许助教看到匿名帖子的隐私政策,被用作基准测试的基础。
该团队将原型与5000个活动用户Universe、一个具有内联隐私策略的MySQL实现(“with AP”)和一个不强制实施隐私策略的MySQL实现(“without AP”)进行了比较:
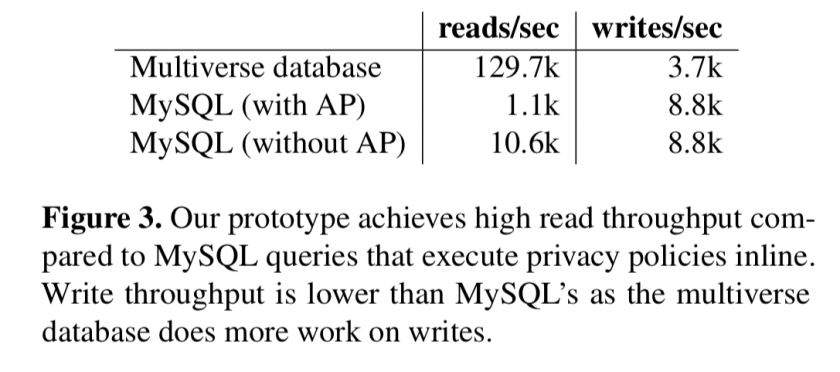
由于原型是从存储在内存中的预先计算的维度中读取数据,因此缓存的结果很快,并且与MySQL进行了非常有利的比较。不过,写的速度要慢得多(大约是2倍)——大部分开销是在实现中,而不是基本的。一个维度的内存占用为0.5GB,5000个维度的内存占用为1.1GB,为相同的查询引入了一个共享记录存储,使它们的空间占用减少了94%。
这些结果是令人鼓舞的,但一个现实的多维数据库必须进一步减少内存开销,并有效地跨机器运行数百万用户维度。Noria和任何其他当前的数据流系统都不支持执行这种部署所需的巨大数据流。尤其是,对数据流的更改必须避免对数据流图进行完全遍历,以加快创建维度的速度。
对写授权策略的支持(对于数据相关的策略有一些棘手的一致性考虑)是未来的工作,开发策略检查器(可能类似于Amazon的基于SMT的AWS策略检查器)也有助于确保策略本身的一致性和完整性。
我们的初步结果表明,一个大的、动态的、部分状态的数据流可以支持实际的多维数据库,这些数据库易于使用,并获得良好的性能和可接受的开销。我们很高兴能进一步探索多元维度数据库范式和相关的研究方向。

若有收获,就点个赞吧
0 人点赞
