文章地址: 图形程序提取算法
资源:2018年LLVM开发者大会技术讲座
Swift for TensorFlow提供了一个按运行定义的编程模型,同时还提供了图算法的全部好处。这是可能的,因为我们在Swift编译器中内置了一个核心的“图程序提取”算法,该算法采用命令式Swift代码并自动构建一个图形作为正常编译流程的一部分。本文档描述并激发了挑战,解释了相关工作,描述了我们与先前工作相比的高层次技术,解释了我们的方法如何工作的归纳智力模型,并用用户术语解释了生成的编程模型。
有助于了解Swift for TensorFlow的总体设计是如何工作的,您可以从Swift for TensorFlow设计概述文档中获得这些信息。
动机
我们的目标是为机器学习研究人员、开发人员和生产工程师提供最好的用户体验。我们相信,提高高性能加速器的可用性将使ML的突破比现在更快。
可用性并不是一件简单的事情:设计的许多方面都有助于(或损害)总体可用性,而ML框架存在的一个关键原因是提供对高性能计算的可用访问。毕竟,在实践中没有充分利用高理论性能是不相关的,例如,因为它需要程序员做太多的工作或专业知识。因此,我们的主要目标是消除过去迫使开发人员在性能和可用性之间做出选择的折衷。
我们的方法来自于我们从第一个原则看整个软件堆栈,并得出结论,如果我们能够增强编译器和语言,我们可以实现新的东西。其结果是本文描述的基于编译器的图形程序提取算法:它允许ML程序员使用正常的控制流编写简单的命令代码,并让编译器完成构建TensorFlow图形的工作。除了图形抽象的性能优势外,该框架还允许其他编译器分析自动检测用户代码中的错误(如形状不匹配),而无需运行它。
相关工作
机器学习框架使用了几种不同的方法,我们将在这里简要探讨这些方法。不过,在我们这样做之前,必须观察所有这些方法(包括我们的方法)的关键共性。机器学习模型包含两种不同类型的代码:张量数字处理逻辑和其他用于命令行选项处理、数据管道设置和其他编排逻辑的通用代码。
所有这些方法只是系统“找到”张量逻辑、提取出来并将其发送到加速器的不同方法。通过探索方法的多样性,我们可以看到它们各自的优势,以及它们所带来的权衡。
线性代数库
在现代ML框架开发之前,NumPy、Eigen等线性代数库和MatLab等系统是探索ML技术的主要途径。它们的优点是非常具体,任何地方的程序员都很熟悉,他们了解一点线性代数,它们相对容易调试和使用,并且它们可以很好地与autodiff api(如autograd)配合使用。这就是为什么流行的神经网络的介绍教神经网络这样的一个原因。
尽管有这些优势,很少有人直接使用NumPy进行计算密集型的ML研究:虽然它在单个CPU上相对高效,但它不允许op融合,不支持gpu(尽管存在扩展)或其他外来的加速器,也不支持向多个设备分发。这会导致数量级的性能增量,从而阻止使用大型模型和大型数据。
这些限制导致了像TensorFlow这样的专门框架的开发。
显式图生成api
对于这些挑战,最流行的解决方案可能是引入一个图抽象,并引入用于构建和执行该图的API(例如TensorFlow会话API)。一旦计算被表示为一个图,许多重要的性能优化就成为可能,对gpu和云tpu等加速器硬件的支持以及跨多个加速器的分布也是如此。
这种方法的缺点是为了实现这些目标而牺牲了大量的可用性。例如,作为一个用户,动态控制流很难表达,因为必须使用特殊的循环/条件运算符并正确地获得控制相关的边。代码中的形状不匹配错误是另一个痛点:通常它们会通过一堆您没有编写的运行时代码生成堆栈跟踪,这使得很难理解错误和最终修复。在解释器中逐步使用张量也是很难的,在调试器中很难单步执行代码,等等。
当面对这些可用性折衷时,一些用户选择牺牲一点性能来显著提高可用性。
按运行方式定义-解释程序
Define-by-run方法为机器学习操作提供了一个“直接执行”模型,而最广泛使用的实现是通过一个解释器(如在TensorFlow中使用了急切执行)。当你说“matmul”时,他们不会建立一个图,而是立即在连接的设备上执行matmul操作。这可能是一个巨大的可用性胜利,特别是对于使用控制流的模型(因为您可以直接使用Python控制流,而不是将控制流转移到一个图中),动态模型更容易编写,因为您可以在模型中嵌入任意Python代码,您可以在调试器中单步执行模型,您可以在Python解释器中迭代地设计ML代码。
这种方法有很多优点,但也有局限性:
- Python解释器的低性能对于某些类型的模型很重要,特别是那些使用细粒度操作的模型。
- GIL可以强制复杂的解决方案(例如,在C++代码中混合),以便将多核CPU作为工作的一部分。
- 即使我们有一个没有GIL的无限快的解释器,解释器也不能“向前看”超过当前操作,这就阻止了发现依赖于当前正在分派和等待的工作的未来工作。这反过来又防止了某些优化,如通用操作融合、模型并行等。
最后,虽然自动微分(AD)不是本白皮书的重点,但“按运行定义”方法阻止了对AD使用“源代码转换”技术。它们使用的“运算符重载”方法是有效的,但无法将宿主语言中的控制流构造转换为计算图,使其成为当差异化失败时,很难执行优化或提供良好的错误消息。
按运行方式定义-可追踪的JIT
几个活跃的研究项目正在探索跟踪JIT编译器在define by run系统中的使用(例如JAX、一个新的PyTorch JIT等)。这些方法不是让解释器立即执行一个操作,而是缓冲“跟踪”,这提供了图形技术的一些优势和解释器方法的一些可用性优势。另一方面,跟踪jit会带来它们自己的权衡:
跟踪jit将用户模型从计算张量值变回构建阶段图节点,这是用户模型的一个可观察部分。例如,当编译/执行跟踪时,而不是在问题的根源op处执行跟踪时,运行时系统可能会出现故障。这降低了按运行系统定义的关键可用性优势。
- 可追踪的jit完全“展开”计算,这可能导致非常大的跟踪。
- 可追踪的JIT无法跨依赖于数据的分支“向前看”,这可能导致某些类型的模型中出现短跟踪,并在执行管道中出现气泡。
- 可追踪的jit允许动态模型混合使用非张量Python计算,但这样做会重新导致Python的性能问题:这种计算产生的值会分割跟踪,可能会引入执行气泡,并延迟跟踪执行。
总的来说,这些方法提供了一个混合模型,它提供了许多图形的性能以及基于解释器的define-by-run模型的一些可用性,但是包含了沿两个轴的折衷。
多阶段轻型模块化(LMS)
多阶段轻量级模块化是一种运行时代码生成方法,允许直接用语言表达生成的代码。这种方法在机器学习社区中并没有广泛应用,但是像DLVM这样的新的研究系统是LMS技术在Swift机器学习框架中的先锋应用。
LMS允许在源语言中直接表达命令张量代码,在运行时隐式地构建一个图,并且不需要编译器或编程语言扩展。另一方面,虽然LMS技术可以在许多不同的语言中应用,但控制流的自然分段需要一些只有少数语言(例如scala虚拟化)支持的外来特性,因为需要对程序结构进行静态分析。此外,LMS是编程模型中用户可见的部分——即使在Scala中,用户也需要显式地将Rep类型包装在数据类型周围。
LMS与我们的图程序提取方法最为相似。我们选择使用一流的编译器和语言集成,因为张量计算的“分段”只是我们希望解决的可用性问题之一。我们还对使用编译器分析在编译时检测形状错误和其他错误感兴趣,并且我们相信完全集成方法的可用性好处不仅仅是对编译器进行适度投资的理由。
图程序提取:一种新的按运行定义方法
我们的方法基于这样的观察:编译器可以通过解析代码和应用静态分析技术“看到”程序中的所有张量操作。这允许用户直接针对自然张量API编程,并在张量之上构建额外的高级API(如层和估计器)。编译器然后构建一个TensorFlow图作为标准编译过程的一部分,就像其他代码生成任务一样。
这提供了许多优点,包括:
- 自然的按运行定义的模型,包括使用语言控制流(如for循环和if语句)的能力
- 图的完全性能
- 完全访问可以在这些图中表示的任何内容,包括输入管道抽象
- 加速张量操作和任意非张量主机代码之间的自然互操作性,仅在用户程序需要时来回复制数据
- 生成编译器警告或错误消息的能力,允许程序员在需要时避免不必要的主机/设备复制,并理解它们发生的位置
- 执行附加值静态分析以发现其他错误和问题的能力,例如在编译时检测形状错误
最后一点值得强调:虽然TensorFlow是本项目的关键动力,但这些算法完全与TensorFlow无关。相同的编译器转换可用于提取任何与主机程序异步执行的计算,同时(可选地)通过发送和接收进行通信。这对于任何将计算表示为图形的对象都是有用的,包括其他ML框架、其他类型的加速器(例如,对于密码学或图形)以及基于图形的分布式系统编程模型。这些应用程序还将受益于Swift类型系统,例如在编译时静态诊断无效图的能力。
建立编程模型
我们的目标是提供一个简单、可预测和可靠的编程模型,该模型易于直观理解,可以在几段中向用户解释,并且编译器可以通过警告和其他诊断来增强它。
最重要的挑战是,编程模型必须能够进行可靠的静态分析,而且还允许使用高级用户定义的抽象,如(层和估计器)。我们的方法可以用几种支持可靠静态分析的语言实现。有关所涉及问题的详细讨论,请参阅我们的Why Swift For TensorFlow?文档。
为了解释我们的模型,我们提供了一个自下而上的直观解释,从一个琐碎的开始(不是很有用!)编程模型,并以增量方式将其构建成实现我们目标的东西。
一般图表示
我们的图程序提取算法的输出是一个特定于域的(如TensorFlow)图,但是Swift中的表示和提取算法与大多数细节无关。
我们假设每个节点都有一个编码为字符串的操作名、数据流输入和结果、可以选择具有常量属性,并且还可能有副作用。因为提取算法本身并不关心属性或副作用,所以我们在下面的讨论中忽略它们,只考虑操作名及其数据流输入和结果。我们还假设图具有表示控制流的能力,但是下面的算法与这些表示细节无关。我们方法的一个子集可以用于不支持控制流的图抽象。
尽管我们在下面的例子中使用了Swift和TensorFlow,但是这些算法是独立的,我们希望看到其他人把这项工作应用到新的领域和语言中!
一个微小的编程模型
如果您对问题有足够的约束,那么基于可靠静态分析的图形提取就很简单:首先,我们不支持任何变异、指针别名、控制流、函数调用(或其他抽象!),聚合值,如结构或数组,并且与主机代码没有互操作性。
有了这些限制,我们只能表示一个非常简单的编程模型,其中每个“op”都有一个神奇的语法,它接受一个操作名、一个或多个图形值作为参数,并返回一个或多个结果值。由于还没有与宿主代码的互操作性,因此图操作仅由图操作生成和使用。
我们的实现使用#tfop作为拼写操作的独特语法,并具有众所周知的类型(名称如TensorHandle和VariantHandle)来表示图形值。请注意,TensorHandle是我们系统的内部实现细节,不是普通用户会看到或与之交互的东西。使用这种类型和操作语法,我们可以编写如下函数:
/// Compute matmul(x,w)+b in a TensorFlow graph.
func multiplyAndAdd(x: TensorHandle, w: TensorHandle, b: TensorHandle) -> TensorHandle {
let tmp = #tfop(“MatMul”, x, w)
let tmp2 = #tfop(“Add”, tmp, b)
return tmp2
}
因为我们在接受的内容上添加了很多约束,所以通过静态分析将其转换为一个图是很简单的:我们可以对代码进行自上而下的遍历。每个函数参数都转换为图形的输入。每个操作都很容易识别,并且可以1-1转换为图形节点:给定自顶向下的遍历,输入已经是图形节点,操作名、输入和任何属性(这里不讨论)都立即可用。因为我们没有控制流,所以只有一条返回指令,它指定图形的结果。
这给了我们这样一个结果:
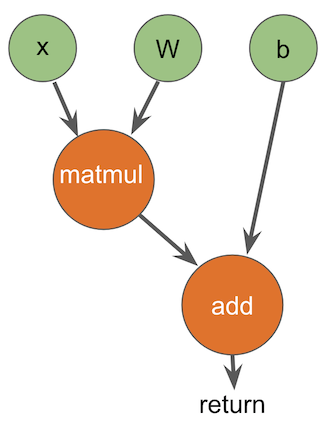
除了转义过程之外,还需要注意的是,我们有一个定义良好的语言子集,很容易向用户解释(不过,它还不是很有用!)。编译器可以通过编译器错误来加强模型的限制,例如,如果用户试图在变量中存储TensorHandle,将TensorHandle传递给非图形操作(如print)或使用控制流。因为分析是内置在编译器中的,所以编译器错误可以直接指向导致问题的代码行,这对可用性很有帮助:用户确切地知道他们做错了什么,以及为了让代码编译必须修复什么。
也就是说,虽然这是一个可靠、可预测和可实现的模型的良好基础,但这种设计是如此有限,以至于无法实现我们的目标。为了扩展它,我们开始在上面组合特性,使模型更加通用和可用。
添加可变变量
我们将添加的下一个功能是变量,它允许更改和重新分配。例如,我们希望允许这样的代码:
/// Compute a+b+c+d in a TensorFlow graph.
func addAll(a: TensorHandle, b: TensorHandle, c: TensorHandle, d: TensorHandle) -> TensorHandle {
var result = #tfop(“Add”, a, b)
result = #tfop(“Add”, result, c)
result = #tfop(“Add”, result, d)
return result
}
鉴于我们没有控制流或别名,我们可以通过对代码执行自上而下的传递、“重命名”每个赋值的结果并在以后使用重命名的值进行更新,从而轻松地消除代码中的所有变量变异。在本例中,编译器“desugars”将此代码转换为:
/// Compute a+b+c+d in a TensorFlow graph.
func addAll(a: TensorHandle, b: TensorHandle, c: TensorHandle, d: TensorHandle) -> TensorHandle {
let result1 = #tfop(“Add”, a, b)
let result2 = #tfop(“Add”, result1, c)
let result3 = #tfop(“Add”, result2, d)
return result3
}
我们在这里没有给出证明,但是众所周知,变量可以被证明地降低到重命名的不可变值,因为我们的编程模型不支持别名或控制流。如前一节所述,我们还知道可以将任何结果函数(仅使用不可变值)降为一个图。因此,通过归纳,我们知道我们可以可靠地将这个扩展的功能类降到一个图中,同时保持我们可靠地静态诊断超出我们支持的模型的任何东西的能力。
这个归纳模型是我们转换的关键:我们可以引入新的抽象,只要我们可以证明以可预测的方式消除它们。可预测性是这里的一个基本要求:引入一个需要基于启发式的分析技术来消除的新抽象是有问题的,因为当启发式失败时,它会影响可以编译哪种类型的代码。编译器将能够诊断该故障,但这将导致一个不稳定和难以预测的用户编程模型。
添加过程内(功能内)控制流
早期的编译器基于位向量数据流分析,并在优化器中广泛使用重命名,以构建更精确的use def链并消除分析中的错误依赖。这些技术最终被推广到一种被称为静态单赋值(SSA)形式的方法中,并被现代编译器系统广泛采用。
SSA形式及其数学公式的细节超出了本文的范围,但将给出大致的笔划。SSA推广了上面的重命名转换,以支持静态过程内控制流(即if、while、for、break、switch和其他控制流语句),这些语句通常用控制流图(CFG)表示。它的标准公式可以重命名没有别名的变量(我们的模型没有别名),并引入一个称为“phi”节点的概念来表示控制流合并点处的值。这允许我们从所有标准语言构造的函数中的一般控制流中消除变量变异。例如,SSA construction重命名此代码:
/// Compute a weird function in a TensorFlow graph using control flow and mutation.
func conditionalCode(a: TensorHandle, b: TensorHandle, c: TensorHandle, d: TensorHandle) -> TensorHandle {
var result = #tfop(“Mul”, a, b)
if … {
result = #tfop(“Add”, result, c)
} else {
result = #tfop(“Sub”, result, d)
}
return result
}
在这个低层的伪代码中:
/// Compute a weird function in a TensorFlow graph using control flow and mutation.
func conditionalCode(a: TensorHandle, b: TensorHandle, c: TensorHandle, d: TensorHandle) -> TensorHandle {
bb0:
result1 = #tfop(“Mul”, a, b)
if (…) goto then_block else goto else_block
then_block:
result2 = #tfop(“Add”, result1, c)
goto after_ifelse
else_block:
result3 = #tfop(“Sub”, result1, d)
goto after_ifelse
after_ifelse:
result4 = phi(result2, result3)
return result4
}
一旦SSA构造消除了变异,我们就需要将函数的控制流图转换为目标图所使用的控制流表示。在TensorFlow的情况下,我们选择生成纯函数While和If控制流结构,这些结构由XLA编译器后端推广,但也可以生成标准的TensorFlow开关/合并原语。
由于我们要降到功能控制流表示,我们使用众所周知的“结构分析”技术将控制流图转换为一系列单入口单出口(SESE)区域。这些技术也适用于任意的控制流图结构,包括不可约的控制流,这些控制流可以出现在具有非结构化goto语句的语言中(但Swift没有)。
当应用于上述示例时,我们的SESE转换生成如下结构:
/// Compute a weird function in a TensorFlow graph using control flow and mutation.
func conditionalCode(a: TensorHandle, b: TensorHandle, c: TensorHandle, d: TensorHandle) -> TensorHandle {
let result1 = #tfop(“Mul”, a, b)
// Note: named parameter labels are our representation for constant attributes.
let result4 = #tfop(“If”, …, result1, c, d, true: ifTrueFunction, false: ifFalseFunction)
return result4
}
func ifTrueFunction(result1: TensorHandle, c: TensorHandle, d: TensorHandle) -> TensorHandle {
let result2 = #tfop(“Add”, result1, c)
return result2
}
func ifFalseFunction(result1: TensorHandle, c: TensorHandle, d: TensorHandle) -> TensorHandle {
let result3 = #tfop(“Sub”, result1, d)
return result3
}
我们的实现处理Swift支持的分支结构和循环,并且应该很容易将它们泛化为支持外来的控制流结构,比如间接goto,只要目标图有一种表达方法,或者主机程序有一种方法可以异步地将目标标识符传递给图形运行时。
结合SSA构造和SESE区域形成,可靠地将任意的局部变异和局部控制流转化为已知的可以降到图的形式,这是我们编程模型的一个重要扩展。也就是说,我们的模型仍然有重要的缺失部分,所以让我们继续建设!
添加主机/图通信
除了使用语言本机控制流的能力之外,define by run模型的最大好处可能是允许用户将张量计算与宿主代码混合和匹配:这对于动态机器学习模型(在NLP中很常见)和包括模拟器的强化学习算法是至关重要的,因为研究人员有时希望在不编写CUDA代码的情况下实现他们自己的张量运算,并且因为能够调用print来查看您的代码在做什么是很好的!
在解释我们的方法之前,我们将介绍一个在训练循环中使用Atari模拟器的(抽象的)示例,并解释不同的define by run方法如何处理它。该示例是用我们当前的有限编程模型编写的,但是添加了主机到图之间的通信:
func hostAndGraphCommunication() -> TensorHandle {
var values = #tfop(“RandomInitOp”)
for i in 0 … 1000 {
let x = #tfop(“SomeOp”, values)
// This is not a tensor op, it has to run on the host CPU.<br /> // It might be dispatched to a cluster of worker machines.<br /> let result = atariGameSimulator(x)let y = #tfop("AnotherOp", x)<br /> values = #tfop("MixOp", result, y)<br /> }
return result
}
在基于解释器的define-by-run系统中,主机CPU运行解释器,并在遇到解释器时分派每个操作。当遇到atariGameSimulator调用(它不是TensorFlow操作)时,解释器只是将数据从加速器复制回主机,进行调用,并在到达使用它的MixOp操作时将结果复制回加速器。
可追溯的jit通过让解释器收集更长的张量操作序列来进一步实现这一点——这种操作的“跟踪”允许对张量代码进行更多的优化。这个例子太简单了,无法真正展示它的威力,但即使在这里,跟踪JIT也应该能够在第一次迭代中构建包含randomininitop操作和SomeOp操作的跟踪,从而允许它们之间的操作间融合。另一方面,只要找到数据依赖项,跟踪jit就必须结束跟踪:对atariGameSimulator的调用需要x的值,因此跟踪就停止在那里。
由于这些系统的工作方式,它们中的任何一个都无法发现另一个操作可以在加速器上与主机上的atariGameSimulator并行运行。此外,由于跟踪JIT分割跟踪,SomeOp和AnotherOp之间的数据布局优化通常是不可能的:这两个位于不同的跟踪中。
这种情况只是基于编译器的方法能够真正发挥作用的一个例子,因为编译器可以看到对atariGameSimulator的调用之外的内容。这给了它更好的优化范围,允许它构建更大的区域,并在模型需要它的确切位置执行到主机的复制。当目标是充分利用云TPU等超高性能加速器时,这一功能尤为重要。
基于图程序提取的主机/设备通信
TensorFlow已经有了高级的原语来在设备之间发送和接收数据,而且我们实际上可以将整个训练循环表示为一个图形。因此,面对主机/设备通信,我们的编译器将输入“划分”为两个不同的程序:一个在主机上运行,另一个由TensorFlow(以图形表示)运行。实现这一点的算法并不简单,但在概念上很容易理解,特别是考虑到我们的编程模型在这一点上的局限性:没有像函数调用或用户定义的数据类型那样的抽象。
首先,我们从复制函数开始,用send和receive操作替换所有主机代码。这给了我们这样的代码:
func hostAndGraphCommunication_ForGraph() -> TensorHandle {
var values = #tfop(“RandomInitOp”)
for i in 0 … 1000 {
let x = #tfop(“SomeOp”, values)
// REMOVED: let result = atariGameSimulator(x)<br /> #tfop("SendToHost", x)<br /> let result = #tfop("ReceiveFromHost")let y = #tfop("AnotherOp", x)<br /> values = #tfop("MixOp", result, y)<br /> }
return result
}
我们知道,这种转换可以证明消除了所有仅限主机的代码,因此我们现在可以使用前面的方法逐步地去糖并生成一个图。因为图捕获了所有的张量计算,所以对于TensorFlow的图运行时来说,执行跟踪jit所实现的优化是很简单的。这种方法还提供了额外的优化,例如与主机计算并行执行另一个操作,以及SomeOp和另一个操作之间的布局优化。
在构建图之后,编译器接下来需要处理在主机上运行的代码。它只需删除tensor操作,并用TensorFlow运行时的调用替换它们。它还将调用插入到运行时中,以开始和完成TensorFlow图的执行(它大致对应于Session.run)。
总之,我们得到的主机代码如下:
func hostAndGraphCommunication() -> TensorHandle {
let tensorProgram = startTensorFlowGraph(“… proto buf for TensorFlow graph … “)
// REMOVED: var values = #tfop(“RandomInitOp”)
for i in 0 … 1000 {
// REMOVED: let x = #tfop(“SomeOp”, values)
let x = receiveFromTensorFlow(tensorProgram)
// This is not a tensor op, it has to run on the host CPU.
// It might be dispatched to a cluster of worker machines.
let result = atariGameSimulator(x)
sendToTensorFlow(tensorProgram, result)<br /> // REMOVED: let y = #tfop("AnotherOp", x)<br /> // REMOVED: values = #tfop("MixOp", result, y)<br /> }<br /> let result = finishTensorFlowGraph(tensorProgram)<br /> return result<br />}
这些转换的结果是,我们得到两个在不同设备上运行的协同执行程序,而这些设备只需要在需要交换数据时彼此会合。这直接反映了高性能加速器的硬件设计:它们是独立的处理器,从主CPU异步运行代码。在物理层,它们通过发送和接收消息进行通信,例如通过DMA传输或网络包。
因为我们生成了一个TensorFlow图,所以这个设计允许TensorFlow应用有趣的异构技术。例如,TensorFlow的XLA编译器GPUs在操作之间应用了积极的融合,但是允许CPU驱动顶级控制流(比如训练循环)。所有这些自然都不属于这种方法。
最后一点:这种转换在编译器界被称为程序切片。尽管我们不知道这些技术是用于这个目的的,但这些技术背后的算法和理论已经研究了很多年。
基于图程序提取的控制流同步
在上面的讨论中,我们忽略了一些重要的话题:两个共同执行的程序如何保持同步?为什么两个程序都在0中复制for i。。。1000次计算?如果循环条件是只能在主机上运行的,会发生什么情况?如果我们做了一些不确定的事情(比如随机数发生器),这两个程序会发散吗?
让我们考虑一个简单的例子,它迭代地进行计算,直到在用户的键盘上按下一个键——一个显然必须在主机上求值的谓词。为了使以后的代码更易于解释,该示例使用while true和break,但是编译器可以处理任何形式:
func countUntilKeyPressed() -> TensorHandle {
var result = #tfop(“Zero”)
while true {
let stop = keyPressed()
if stop { break }
result = #tfop("HeavyDutyComputation", result)<br /> }
return result
}
当我们应用上面的程序切片算法时,我们应用程序切片将张量运算分割成一个图。在执行此操作时,该算法注意到HeavyDutyComputation依赖于退出循环的条件:如果不移动可能导致循环退出的控制流,则无法移动循环。执行此操作时,它会看到keyPressed()是一个宿主函数(就像前面示例中的atariGameSimulator调用一样),因此它会安排在宿主上运行该函数并将该值发送给TensorFlow。graph函数的结果如下:
func countUntilKeyPressed_ForGraph() -> TensorHandle {
var result = #tfop(“Zero”)
while true {
// REMOVED: let stop = keyPressed()
let stop = #tfop(“ReceiveFromHost”)
if stop { break }
result = #tfop("HeavyDutyComputation", result)<br /> }
return result
}
… 宿主函数如下所示:
func countUntilKeyPressed() -> TensorHandle {
let tensorProgram = startTensorFlowGraph(“… proto buf for TensorFlow graph … “)
// REMOVED: var result = #tfop(“Zero”)
while true {
let stop = keyPressed()
sendToTensorFlow(tensorProgram, stop)
if stop { break }// REMOVED: result = #tfop("HeavyDutyComputation", result)<br /> }
let result = finishTensorFlowGraph(tensorProgram)
return result
}
有趣的是,主机只是在跟踪加速器正在执行的重载计算,通过一个布尔值流发送消息,告诉加速器何时停止。在计算结束时,张量结果值作为程序的结果被复制回一次。
让主机CPU处理机器模型中的所有高级控制流可以保证两个程序保持同步:例如,在一个地方(主机上)计算非确定性随机谓词,并将结果发送到加速器。这也是编排GPU计算的标准模型。
另一方面,当主机和加速器之间的延迟很高(例如,如果涉及到网络)或从诸如云TPU这样的加速器寻求最大性能时,这种方法可能是性能问题。因此,作为一种性能优化,我们的编译器通过在两个设备上复制计算来寻找减少通信的机会。这使得它可以促进简单的条件(比如0中的i。。。1000)运行“in graph”,消除一些通信跳数。
性能可预测性与隐式主机/设备通信
最后一个重要的主题是性能可预测性。我们喜欢我们的define-by-run模型允许用户灵活地混合主机和张量代码,但这带来了一个问题,即这可能导致非常难以理解的陷阱,即大型张量值在设备之间过度地来回跳跃。
这个问题的解决方案正好适合标准编译器设计:默认情况下,Swift在生成隐式副本时生成编译器警告(如上面的示例所示),这使得在引入副本时立即清楚。
当拷贝是有意的时候,这些警告可能会很烦人,因此,用户可以完全禁用警告(例如,在性能无关紧要的小问题上进行研究时),也可以通过调用一个方法(当前名为x.toAccelerator()和x.toHost())来逐个禁用警告,以告知编译器(以及将来的代码维护者!)副本是故意的。
此模型对于大规模部署代码的生产工程师特别有用,因为他们可以将警告升级为错误,以确保即使代码继续发展,也不会有隐式副本潜入。
既然我们已经有了处理宿主程序和TensorFlow程序之间通信的健壮方法,那么让我们回到改进编程模型的任务上来,使其更易于用户使用,也不那么原始。
添加结构和元组
如前所述,只要我们有一个可证明的方法来消除抽象,我们就可以向模型中添加任何抽象。一旦它们被消除,我们就可以使用上面描述的方法将代码降低到图形。在结构和元组的情况下,只要编译器能够看到类型定义,Swift就保证能够将它们标量化。这是可能的,因为我们的编程模型中没有别名。
这很好,因为它允许用户用张量和其他值组成高层抽象。例如,编译器将此代码按比例缩放:
struct S {
var a, b: TensorHandle
var c: String
}
let value = S(a: t1, b: t2, c: “Hello World”)
print(value.a)
let tuple = (t3, t4)
print(tuple.0)
转换为:
let valueA = t1, valueB = t2
let valueC = “Hello World”
print(valueA)
// equivalent to: tuple0 = y; tuple1 = z
let (tuple0, tuple1) = (y, z)
print(tuple0)
这允许编译器在主机上处理字符串处理逻辑,并在TensorFlow中处理tensor。用户可以用他们觉得最自然的方式构建他们的模型。
尽管可以如上所述处理结构和元组,但类更为复杂,因为除其他原因外,它们的引用可能是别名。我们将在下面更详细地讨论它们。
添加函数调用
下一个大的跃进是添加函数调用,编译器可以通过内联证明可以消除这些调用。这两个要求是编译器需要能够看到函数的主体,并且调用必须是直接调用:间接函数调用、虚拟调用和通过存在值进行的调用需要别名或类层次结构分析之类的东西来消除歧义,这些基于启发式的技术导致了脆弱的编程模型。
幸运的是,Swift有很强的静态特性,结构上的所有顶级函数、方法和许多其他东西(如结构上的计算属性)都是一致的直接调用。就我们的建模能力而言,这是一个巨大的进步,因为我们现在可以构建一组合理的面向用户的tensorapi。例如,如下所示:
struct Tensor {
// TensorHandle is now an internal implementation detail, not user exposed!
private var value: TensorHandle
func matmul(_ b: Tensor) -> Tensor {
return Tensor(#tfop(“MatMul”, self.value, b.value))
}
static func +(lhs: Tensor, rhs: Tensor) -> Tensor {
return Tensor(#tfop(“Add”, lhs.value, rhs.value))
}
}
func calculate(a: Tensor, b: Tensor, c: Tensor) -> Tensor {
let result = a.matmul(b) + c
return result
}
将计算函数的主体用内联的形式去掉:
let tmp = Tensor(#tfop(“MatMul”, a.value, b.value))
let result = Tensor(#tfop(“Add”, tmp.value, c.value))
… 然后对张量结构进行缩放以产生以下结果:
let tmp_value = #tfop(“MatMul”, a_value, b_value)
let result_value = #tfop(“Add”, tmp_value, c_value)
… 这对于图来说是微不足道的提升。这些简单的去锯齿转换是如何清晰地组合的,这是非常好的,但只有在它们得到保证并且可以与用户能够理解的简单语言结构绑定时,才会出现这种情况。
我们在这里没有足够的空间进入它,但是这个内联转换也适用于像map和filter这样的高阶函数,只要它们的闭包参数是不转义的(这是默认的):内联map调用最终会公开对其闭包的直接调用。此外,Swift的一个重要设计点是,我们所依赖的非混叠属性甚至扩展到inout参数和变异结构方法的自参数。这使得编译器能够积极地分析和转换这些值,这是Swift的排他性法则的结果,它将Fortran风格的非别名属性授予这些值。
值得一提的是,TensorFlow图支持函数调用。从理论上讲,我们应该能够使用它们来避免代码爆炸问题,这些问题理论上可能来自于广泛的内联。到目前为止,使用TensorFlow实现的机器学习模型很少使用这些特性,而且我们在实践中也没有遇到图大小的问题,因此对此进行探索并不是当务之急。
添加泛型
Swift泛型模型可以通过泛型专门化的方法被证明是不可靠的,当然,这也是对普通Swift代码的一个重要性能优化!这是我们系统表达能力的一个巨大扩展:它允许Swift直接捕获和执行关于张量数据类型的规则。例如,我们可以将上面的示例扩展为如下所示:
struct Tensor
private var value: TensorHandle
func matmul(b: Tensor) -> Tensor {
return Tensor(#tfop(“MatMul”, self.value, b.value))
}
static func +(lhs: Tensor, rhs: Tensor) -> Tensor {
return Tensor(#tfop(“Add”, lhs.value, rhs.value))
}
}
这方面的好处是,Tensor API的用户可以自动获得dtype检查:如果您意外地尝试使用Tensor
另一个好处是,这也扩展到了高级和用户定义的抽象,例如,如果您定义这样的代码:
struct DenseLayer
var weights: Tensor
var bias: Tensor
var dLoss_dB: Tensor
var dLoss_dW: Tensor
init(inputSize: Int, outputSize: Int) {…}
}
…
fcl = DenseLayer
通用专业化将导致:
struct DenseLayer_Float {
var weights: Tensor_Float
var bias: Tensor_Float
var dLoss_dB: Tensor_Float
var dLoss_dW: Tensor_Float
init(inputSize: Int, outputSize: Int) {…}
}
…
fcl = DenseLayer_Float(inputSize: 28 * 28, outputSize: 10)
一般的专门化将减少到这个:。。。然后Swift将应用所有其他的解构转换,直到我们得到一些可以简单地转换成图的东西。
这里还有很多事情要做,但是这个文档已经太长了,所以我们将避免进一步逐案讨论。最后值得一提的是,Swift对“面向协议编程”的方法允许许多传统上用OOP表示的东西通过使用协议需求的默认实现所允许的混合行为组合结构以纯静态的方式表示。
这种方法的局限性:模型外语言特性
我们已经广泛地讨论了Swift的静态方面,但完全忽略了它的动态方面:类、存在性和建立在它们之上的动态数据结构,如字典和数组。这些实际上是两个不同的类要考虑。我们先从动态类型开始:
Swift将聚合类型分为两类:动态(类和存在)和静态(结构、枚举和元组)。因为存在类型(即静态类型为协议的值)可以由类实现,所以这里我们只描述类的问题。Swift中的类是非常动态的:每个方法都是通过vtable(在Swift对象的情况下)或消息发送(其类型仅从Apple平台上的NSObject或另一个Objective-C类派生)动态调度的。此外,类中的属性可以被派生类重写,指向类实例的指针可以以非结构化方式别名。
事实证明,这与Java、C#、Scala和Objective-C等面向对象语言中的情况相同:在完全通用性中,不能分析类引用(这在我们的Why Swift for TensorFlow文档中讨论过)。编译器可以通过基于启发式的分析(使用过程间别名分析和类层次分析等技术)来处理许多常见情况,但将这些技术作为编程模型的一部分,意味着代码的微小更改会破坏它们所依赖的启发式。这是依赖果断式优化作为编程模型的用户可见行为的一部分的内在结果。
我们的感觉是,将这些启发式方法使用到编程模型的用户参数部分是不可接受的。问题是,这些方法依赖于被分析程序的全局属性,而局部的小变化会破坏全局属性。在我们的例子中,这意味着对一个独立模块的微小更改可能会导致在代码中完全不相关的部分引入新的隐式数据副本——这可能会导致意外引入千兆字节的数据传输。我们称之为“远距离的恐怖行为”,因为它会给我们的用户带来不安的感觉,所以我们予以否认。
第二个问题是数组、字典和其他类型的集合是由类之类的引用类型构建的。事实证明,Swift的数组和字典类型是基于值语义的原则构建的,这些原则在Swift提供的指针别名和其他现有分析的基础上自然地组合在一起。因为这些是非常常用的,并且可能是实现中的特殊情况,有人可能会说我们应该在编译器中为这些类型构建特殊支持(比如TensorFlow中的tf.tensorray)。
另一方面,这些数据结构中的索引本身几乎总是动态的:不在数组中使用常量索引,而是使用数组,因为在数组的所有元素上都有for循环。虽然我们有可能为在数组元素上展开循环构建特殊支持,但这是一个滑坡,最终会导致向模型中添加大量额外的特殊情况。在我们实现的这一点上,我们更喜欢保持底线,而不是特殊情况下任何“众所周知”的类型:如果需要的话,以后添加新的东西比主动添加和不需要的时候删除更容易。
虽然Swift的类型系统总体上很适合我们在这个项目中所做的工作,但有一个例外的情况,我们希望看到改进。Swift有一个设计良好的错误处理系统(有详细的理论基础)。不幸的是,虽然这个系统的设计是专门用来支持抛出类型错误的,但是目前,Swift只支持通过类型删除错误存在来抛出值。这使得我们的TensorFlow工作和其他任何依赖于可靠静态分析的工作完全无法进行错误处理。我们希望看到这个扩展来支持“类型抛出”作为一个自然的解决方案来完成Swift的静态方面。
向用户解释Swift for TensorFlow模型
上面我们声称,良好的可用性要求我们“提供一个简单、可预测和可靠的编程模型,该模型易于直观理解,可以用几段话向用户解释,并且编译器可以用警告和其他诊断来加强”。我们认为我们的设计达到了这个目的。
我们的用户模型只适用于一个段落:您使用普通的张量API编写普通的命令Swift代码。只要坚持Swift的静态方面:元组、结构、函数、非转义闭包、泛型等等,就可以使用(或构建)任意的高级抽象而不影响性能。如果将张量操作与宿主代码混合使用,编译器将前后生成副本。同样,欢迎您使用类、存在性和其他动态语言特性,但它们会导致到主机/从主机复制。当出现张量数据的隐式副本时,编译器将用编译器警告提醒您。
此用户模型的优点之一是它直接与Swift语言鼓励的几个默认值(例如闭包默认为不转义,使用零成本抽象来构建高级api)保持一致,以及Swift API设计的核心价值(例如,价值语义的普遍使用强烈鼓励在类上使用结构)。我们相信这将使TensorFlow“在实践中感觉良好”变得迅速,因为您不必使用反惯用的设计来使事情正常工作。
我们的实现工作还很早,但是我们现在正从一个早期项目转变为一个公共开源项目,因为我们相信这种方法背后的理论已经被证明了。在实现过程中,我们已经足够深入地理解这些算法的实际实现所面临的工程问题。

若有收获,就点个赞吧
0 人点赞
