论文地址:Cloudburst: 有状态的FAAS, Sreekanti et al., arXiv 2020
今天的论文选择是来自伯克利的RISELab的关于无服务器计算的一个新的选择,它解决了去年“伯克利针对无服务器计算的看法”中概述的一些限制,此时,当前平台提供的粗粒度解决方案限制了工作良好的应用程序设计的种类。上周,我们研究了一个函数传送解决方案;Cloudburst使用更常见的数据传送将数据带到函数运行时旁边的缓存中(尽管您也可以提出这样一种情况:将函数执行放在数据被缓存的位置的调度算法也是函数传送的一种风格)。
考虑到FaaS的简单性和经济吸引力,我们很有兴趣探索能够保持当前产品的自动缩放和操作优势的设计,同时增加性能、成本效益和一致的共享状态和通信。
Cloudburst的关键组成部分是一个高度可伸缩的持久状态(Anna)KV存储、与函数执行环境共存的本地缓存以及缓存一致性协议,以在数据进出缓存时保持开发人员的健全性。哦,当然也有一个调度程序让一切运转起来。
在Cloudburst设计团队的愿望列表中:
- 正在运行的函数的“热”数据应该物理地保存在附近,以便进行低延迟访问
- 任何函数调用站点都应允许更新
- 跨功能通信应以线速工作
- 物理托管的逻辑分解
Canonical云平台体系结构将存储和计算服务分离,以便每个服务都可以独立扩展和操作,即它们被分解。Cloudburst提倡一个设计点,作者称之为“物理托管的逻辑分解”(简称LDPC)。从存储和计算可以独立配置和计费的角度来看,它是分解的,但从物理上来说,热数据可以在本地缓存到访问它的函数运行时旁边。
这是一个听起来很花哨的名字,但它本质上与我们几十年来在企业应用程序中使用的设计是相同的:想想在关系数据库前面有一个L2 ORM缓存的应用服务器。直到现在,数据库本身才是一个分布式KVS,应用程序功能的片段粒度要细得多。
低延迟的自动缩放KVS既可以用作全局存储,也可以用作类似DHT的覆盖网络。为了为函数提供更好的数据局部性,可以在承载函数inocations的每台计算机上部署KVS缓存。Cloudburst的设计包括计算层中一致的可变缓存
程序设计模型
Cloudburst程序是用Python编写的。函数参数可以是常规Python对象或KVS引用。这样的引用在运行时被透明地检索和反序列化。函数可以组成DAG,Cloudburst运行时会自动将结果从一个DAG函数传递到下一个DAG函数。Cloudburst API包括通过KVS的简单get/put/delete操作,以及在函数执行器之间发送消息的send和recv操作。

高层体系结构
Cloudburst有四个关键组件:函数执行器、缓存、函数调度程序和资源管理系统。Anna是RiseLab中的一个高度可扩展的KVS,它支持使用晶格组合的各种无协调一致性模型。
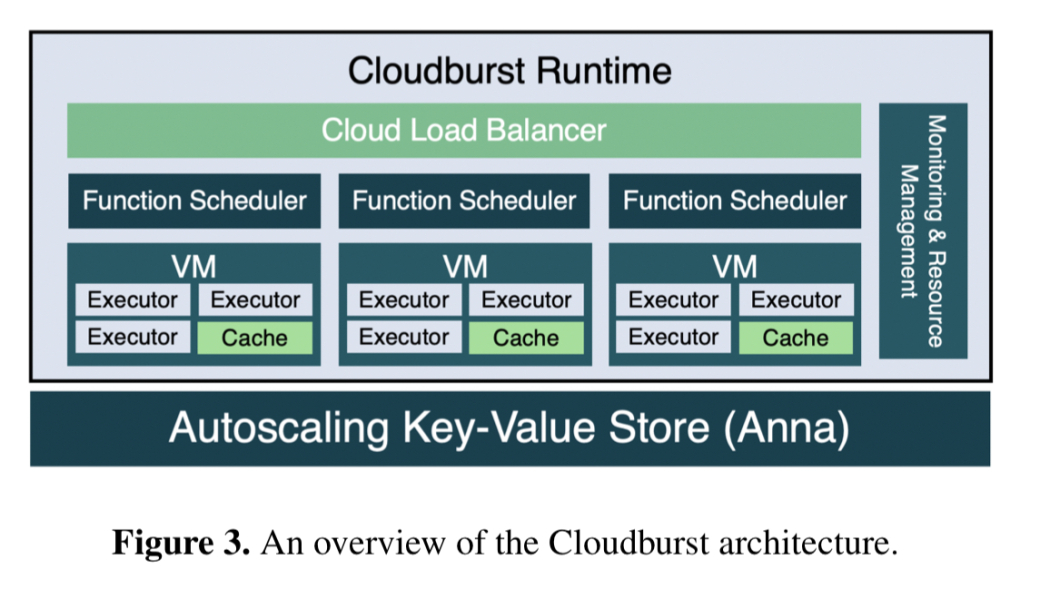
函数执行器只是长寿命的Python进程,可以检索和执行序列化的函数,透明地解析任何持久状态(KVS)引用参数。一个函数执行VM托管多个函数执行器,以及执行器通过IPC与之交互的本地缓存进程。执行器只与缓存交互,后者提供对Anna的读写式访问。为了避免缓存中的陈旧数据,Anna基于其在该节点上存储的密钥的缓存信息定期向节点发送更新。
我们只得到了系统这一部分运行的非常高的细节,一些我想到的开放性问题:
- 缓存在确认来自执行器的请求后异步向要合并的KVS发送更新。缓存本身是否使用某种持久日志记录,或者这里是否存在丢失数据的机会窗口?
- 为什么缓存必须将其缓存的key发布给Anna?Anna不知道哪些客户要求哪些key吗?
- 当缓存中有过时的数据时会发生什么情况?缓存位于Cloudburst使用的连接 因果一致性层的前面还是后面?
所有注册或调用函数或DAG的请求都由调度程序处理。注册的函数被序列化并存储在Anna中,DAG拓扑也是如此。
在调度单个函数和DAG时,我们优先考虑数据的局部性。如果调用的参数具有KVS引用,调度程序将检查其本地缓存的key索引,并尝试选择本地缓存的数据最多的执行器。否则调度程序将随机选择一个执行器。热数据和函数通过背压在许多执行器节点上复制。
Cloudburst监视请求和服务速率(在Anna中存储度量)。当传入请求速率超过服务速率时,监视引擎首先将该函数固定到更多的执行器,然后在CPU利用率超过阈值时向系统添加节点,从而增加分配给该函数的资源。
一致性
作为一个基础,安娜支持个人客户的一致性。但是,DAG的执行可能跨越多个节点,为了支持这个Cloudburst,在上面添加了一个分发会话一致性协议。Anna的保证也只适用于符合其基于格的类型系统的值(支持order insistive、幂等合并操作)。为了处理任意的Python值,Cloudburst将不透明的程序状态包装为晶格类型。看看Cloudburst如何与MRDTs一起工作是很有意思的。
Cloudburst不支持隔离(它允许脏读),但它支持可重复读取和因果一致性(以及Anna支持的其他几种一致性模型)。Cloudburst的因果一致性会话保证了跨多个key和多个物理站点。
对于可重复读取,Cloudbust在第一次读取时创建每个本地缓存对象的快照,然后在DAG执行的整个生命周期中存储这些快照。缓存地址和版本与函数结果一起通过DAG向下游传递。Python程序状态包装在最后一个writer wins格中(本质上是一个值,时间戳对)。
对于分布式会话,因果一致性Cloudburst将Python程序状态包装在因果格中。在这里,我们找到了我关于因果一致性协议和缓存之间关系的问题的答案——它既不是在之前,也不是在之后(两者似乎都有困难),而是集成的!
我们还将Cloudburst缓存扩展为因果一致性存储,实现了螺栓连接因果一致性协议。
除了读取集元数据之外,可重复读取还通过DAG传播,在因果一致性模式下,Cloudburst还为读取集发送一整套因果依赖项。
评估
第一个评估将函数合成开销与纯AWS Lambda、通过S3通信的Lambda函数、通过DynamoDB通信的Lambda函数和AWS Step函数以及使用分层消息总线的SAND无服务器平台和Dask分布式Python运行时进行比较。
Cloudburst的功能组合与最先进的Python运行时延迟相匹配,性能比商用无服务器基础设施高1-3个数量级。
这些开销使分布式算法得以实现,评估表明,基于gossip的浮点度量分布式聚合比使用Lambda和DynamoDB的实现快3倍(见6.1.3节)。
对随机产生的250多个dag进行了一致性模型的开销测试。在达到分布式会话因果一致性(最强的模型)的过中,中位延迟始终较低,但尾延迟确实随着所需协调量的增加而增加。
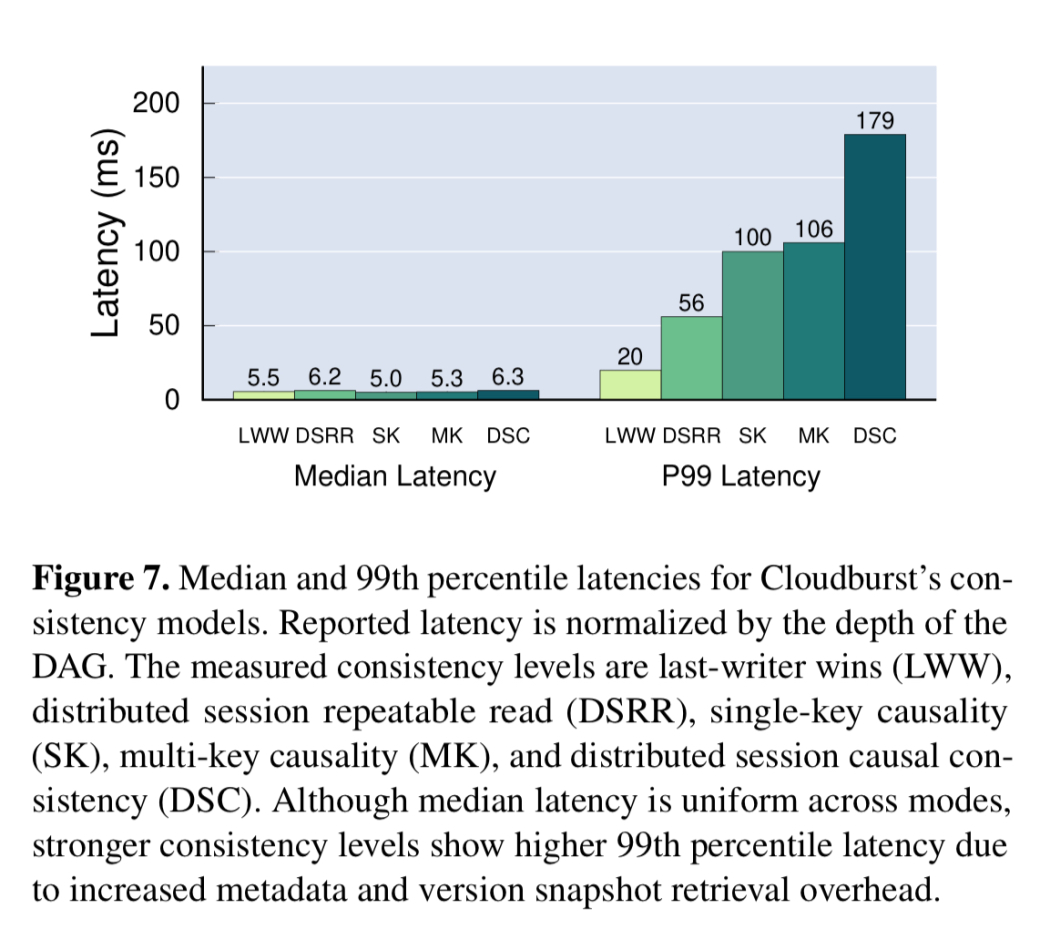
尽管Cloudburst的非平凡一致性模型增加了尾部延迟,但对于类似的任务,中值延迟比DynamoDB和S3快一个数量级,同时提供了更强的一致性。
评估的最后一部分比较了在两个应用场景中Cloudburst的性能:机器学习模型预测服务和Retwis twitter克隆。移植retwis py非常简单(更改了44行代码),结果交付的性能与服务基线相当。对于服务于用例的模型,Cloudburst提供了与单个Python进程相当的性能,其性能比AWS Sagemaker高1.7倍。
最后的想法
Cloudburst表明,分解和托管并不是天生的冲突。事实上,LPDC设计模式是我们解决有状态无服务器计算的关键。

若有收获,就点个赞吧
0 人点赞
