论文地址: 实用部分群的概率有界腐化性——Bailis等人。2012年 和量化与PBS的最终一致性——Bailis等人。2014年
“概率有界腐化性…”是最初的VLDB’12论文,然后作者被邀请向2013/14年出版的VLDB期刊(“量化最终一致性…”)提交一个扩展版本。这篇期刊论文改变了一些用来模拟陈腐的术语(你看到的数据可能已经过时了),使之与早期的太空研究更加紧密地联系在一起。我将主要从2012年的原始版本在这里工作-作为一个独立的文件,我发现它更直观-并参考一些部分从扩展版需要。
让我们先把标题打开一点。
通常,当使用仲裁复制时,我们有N个副本;要写入一个值,我们将其发送给(等待来自)W个副本(写入仲裁)的确认;要读取一个值,我们查阅R个副本(读取仲裁)并从读取仲裁中返回最新的值。短语quorum system用于描述从中选择读和写quorum的集合,并且每个数据项有一个quorum system。
如果您想要严格(强一致性)的quorums,您只需要确保读和写副本集重叠(例如,通过确保每个集包含大多数节点)。部分Quorum放宽了这个约束,允许不重叠的副本集(R+W≤N)。
Quorum复制的数据存储,如Dynamo及其开源后代Apache Cassandra、Basho Riak和Project Voldemort,提供了两种操作模式的选择:具有强一致性的严格Quorum或具有最终一致性的部分Quorum。尽管最终一致性的保证很弱,但运营商经常采用部分数量——这是一个有争议的决定。
这些存储都为每个密钥使用一个仲裁系统,通常使用一致的哈希方案或集中式成员协议维护密钥到仲裁系统的映射。每个节点存储多个密钥。“Dynamo将密钥的复制因子表示为N,成功读取所需的副本响应数表示为R,成功写入所需的副本确认数表示为W。”从从业者帐户中,实际部分群中使用的通用仲裁设置如下:
Apache Cassandra默认为N=3,R=1,W=1,这些设置似乎被广泛使用。
Riak默认为N=3,R=2,W=2,用户推荐用于web、关键任务和财务数据。对于“低值”数据,某些用户建议配置N=2,R=1,W=1。
Voldemort在LinkedIn的运营商经常选择N=c,R=W=(c/2)表示奇数c。N=3,R=1,W=1可能用于需要非常低延迟和高可用性的应用程序,N=2,R=1,W=1也用于某些系统。
我们是在和魔鬼做交易吗?我们知道我们应该用部分数量来实现更低的延迟和更高的可用性,但是代价是什么?假设我们会得到一个我们写下的值,但是这个值会过时吗?读不好的书的机会有多大?直到这篇论文,我们才真正知道如何回答这个问题(这也意味着,除了反复试验之外,我们没有办法找出N、R和W的合适值)。直观地说,我们可以看到读写集重叠的几率越大,我们看到新数据值的概率就越高。因此,虽然我们不能对系统的行为设定绝对的界限,但我们可以给出一些概率的界限,因此就有了“概率有界陈旧性”(PBS)。
因此:“实用部分群的概率有界陈腐性。”
给定N个节点、读仲裁中的R个成员和写仲裁中的W个成员,我们可以计算读包含最近提交的写的概率。从N个节点中,我们可以形成“从N取R”的读解组合。那些不包含最新值的子集是除W的成员之外的所有组合,它们的组合有“take R from N-W”。因此,过时读取的概率为:
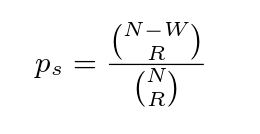
这给了我们一个概率,我们正在读取最新的值。我们可以简单地概括为我们所读的值不超过k个旧版本(PBS k-staleness consistency–或(k,p)-更新的书面术语中的常规语义)的概率:

我们还可以扩展这个概念,给出单调读取的概率——客户机看到与先前读取的值相同或更新的版本的可能性有多大?为了解决这个问题,我们只需要考虑在客户端读取之间可能写入多少个版本。这是客户端读取数据项ratecr的速率,以及全局系统写入该数据项的速率的因子。现在我们可以把它看作k-状态一致性的一个特例,其中k由1+给出(ratecr/rategw):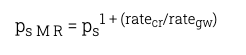
…与传统的概率仲裁系统相比,允许PBS k-状态的群具有渐近更低的负载(并且,在传递上,比严格的仲裁系统)。…这些结果是直观的:如果我们愿意容忍多个版本的过时,我们需要联系更少的副本。过时容忍降低了仲裁系统的负载,从而增加了其容量。
这些都是非常简洁的模型,但可能没有它们可能有用。有两个重要的因素需要考虑:第一,在时间背景下谈论过时似乎更为自然;第二,我们需要考虑实际部分群体系统使用的反熵机制。
知道您将读取一个不超过500ms的值(概率为p)似乎比保证您将看到一个不超过k个版本的值更有用。如果数据项每六个月只更新一次,那可能是一个非常古老的值!当然,如果我们知道更新的速率,那么我们可以将k-失效概率转换为基于时间的概率。
但现在我们需要考虑反熵……一旦写仲裁确认了一个写操作,系统就可以继续运行,但在后台,写操作会通过某种方案继续传播到其他副本。例如,我们可以向所有N个副本发送一个写请求,并在收到确认后立即返回到客户端。这就引出了一个基于时间的一致性度量:
PBS t-可见度模型扩展质量不一致的概率。t-visibility是指在写入提交后t秒开始的读取操作观察到数据项的最新值的概率。此t捕获“不一致窗口”的预期长度
WARS模型可以帮助我们考虑这一点;每个字母表示消息在系统中流动所需时间的概率分布:
- W为写入请求到副本的消息延迟分布建模(注意,此W与仲裁集中的W writer不同)
- A对消息延迟的分布进行建模,以确认这些请求返回到发起方
- R为一个读请求的消息延迟分布建模
- 为返回请求者的读响应消息建模消息延迟的分布
- 如果收到的第一个R响应来自尚未收到最新版本(延迟W)的副本,则读取协调器将看到一个过时的值…。
在协调器等待所有必需的确认(A)和副本等待读取请求(R)的同时,写操作有时间传播到其他副本。读取响应在返回到读取协调器的传输过程中进一步延迟,从而导致重新排序的进一步可能性。定性地说,较长的写尾(W)和较快的读操作增加了由于重新排序而导致过时的可能性。
但是,没有很好的封闭式方程可用于对此进行建模,因此作者转向模拟:
Dynamo很容易推理和编程,但很难以简单的封闭形式进行分析……相反,我们使用蒙特卡罗方法来探索WARS,这种方法很容易理解和实现。
casandra的一个版本被用来描述WARS的延迟,实验表明模型预测和经验观测值非常吻合。然后使用LinkedIn和Yammer生产系统的延迟数据对WARS模型进行校准,以运行一些模拟。全文算法可以在论文的扩展期刊版中找到。
该模型揭示了写延迟(在尾部)的重要性:
Dynamo-style系统的WARS模型表明,较高的单向写入方差(W)会增加陈旧性。为了量化这些影响,我们扫描了一系列指数分布的写分布(改变参数λ,它决定分布的均值和尾部),同时确定了a=R=S……我们的结果证实了这种关系。随着方差和均值的增加,不一致的概率也随之增加。在具有固定均值和可变方差(均匀、正态)的分布下,我们观察到,如果W严格大于A=R=S,则W的平均值小于其方差。减小W的平均值和方差可提高一致读取的概率。这意味着,正如我们将看到的,降低单向写入延迟的技术会导致较低的t可见性。
在LinkedIn的模拟中,使用从磁盘和固态硬盘校准的分布可以观察到这种影响:
LNKD-SSD和LNKD-DISK在实践中证明了写延迟的重要性。在写入提交之后,LNKD-SSD的一致读取概率为97.4%,在5毫秒后达到99.999%的一致读取概率。…相反,在LNKD-DISK下,写操作需要更长的时间(中位数为1.50ms),尾部更长(99.9%为10.47ms)。LNKD-DISK的t可见性反映了这种差异:在写入提交之后,LNKD-DISK只有43.9%的一致读取概率,10毫秒后,只有92.5%的一致读取概率。这表明,由于减少了写方差,ssd可以极大地提高一致性。
如果我们保持R=W=1,并增加副本的数量(N),那么我们可以看到,写操作之后的一致性概率随N的增加而降低。
选择R和W的值是操作延迟和t可见性之间的权衡。为了测量可获得的延迟增益,我们将99.9%一致读取概率所需的t可见性与99.9%的读写延迟进行了比较。部分队列通常表现出良好的延迟一致性权衡(表4)。对于YMMR,R=W=1导致低延迟读写(16.4ms)但高t可见性(1364ms)。但是,设置R=2和W=1会将t可见性减少到202ms,并且读写延迟的总和比最快的严格仲裁(W=1,R=3)低81.1%(186.7ms)。
为了持久性,我们可以将复制从低延迟和高容量的复制中分离出来。例如,运营商可以为持久性和可用性指定最小复制因子,但也可以自动增加N,减少固定R和W的尾部延迟
扩展文件的第7节包含了PBS在多密钥事务和因果一致性中的有趣应用。
事务原子性(不要与线性化能力混淆,在分布式环境中通常称为原子性)确保事务的所有效果都可以看到,或者都看不到。我们可以使用PBS来提供事务原子性概率的保守界。如果我们假设事务中的每个写操作都是独立的,并且所有写操作都被缓冲到事务提交,那么我们观察事务原子性的概率等于P(所有更新都是可见的)+P(没有更新是可见的)。
使用LinkedIn磁盘校准模型,大小为2的事务在50ms后保持一致性的几率为99.4%,而大小为100的事务只有90.2%的几率——不过,1s后这一几率会上升到99.8%。
因果一致性是近年来分布式数据存储研究的热点。在因果一致性下,reads服从数据项中版本的部分顺序[7]。例如,社交网站可能希望强制要求评论回复只能与父母一起查看,并相应地在父母评论之后按部分顺序排序回复。我们可以使用PBS来确定在最终一致的数据存储中违反因果一致性的可能性。
LinkedIn和Yammer的校准模型显示…
特别是当不一致的窗口在数百毫秒内关闭,而对数据项的大多数请求通常发生得更晚时,我们预计在实际的正常操作中,由于最终一致存储操作而导致的因果冲突很少发生。
(尽管忽略“在正常操作期间”这一部分会对您造成风险;))。
当然,概率期望不是一个确定性的保证,但是这个数据,再加上我们的PBS结果,有助于进一步说明,对于许多服务,特别是那些具有人类产生的因果事件链(人类处理时间和精细运动反应限制了到达时间)的服务,最终是如何一致的配置通常提供因果一致性。
锦上添花的是,这个团队建立了一个在线模拟器,这样你就可以用PBS为自己校准战争,设置N、R和W来查看结果。这是一个非常吸引人的方式,使模型发挥作用,也是一个了解系统可能行为的有用工具。

我觉得PBS模拟器和SimianViz(以前的Spigo)一定有一些有趣的组合能够合并在一起使用来更好的解决问题!

若有收获,就点个赞吧
0 人点赞
