论文地址:最终一致性的事务——Burckhardt等人。2012年
我本周还想报道另一篇ECOOP的15篇论文——Burckhardt等人的《全球序列协议》(Global Sequence Protocol),但这篇论文建立在云类型的概念上(类似于CRDTs的精神,而不是我个人以前遇到的东西),这反过来又建立在使用修订图处理最终一致事务的基础上。我们将研究今天的最终一致事务,明天的云类型,然后在周三的全球序列协议文件。
在“最终一致的事务”中,Burckhardt等人。为我们提供一个理解最终一致事务是什么的模型(并洞察它与顺序一致事务的区别),一种基于修订图创建最终一致系统的方法,以及一些构建此类系统的示例。
- 什么是最终一致的事务?
最终,一致性系统保证所有更新最终都会传递到所有副本,并且它们以一致的顺序应用。最终一致性在系统构建者中很受欢迎。一个原因是,它允许暂时断开连接的副本对客户端保持完全可用。这对于在移动设备上实现客户端特别有用。另一个原因是它不需要立即在所有服务器副本上执行更新,从而提高了可伸缩性。从理论上讲,最终一致性的好处可以理解为它推迟达成共识的能力。
最终一致的事务是不可序列化的,但它们支持传统的原子性和隔离保证。它们还提供了一些传统事务所不具备的有用属性:
- 事务不能失败,不能回滚
- 所有代码,甚至是长时间运行的任务,都可以在事务内部运行,而不会影响性能
本文中最终事务的定义基于查询更新接口和自动机模型。查询更新接口是一个三元组(Q,U,V),其中Q是一组查询操作,U是一组更新操作,V是查询返回的一组值。查询更新自动机(Q U A)提供查询更新接口后面的状态模型:对于接口(Q、U、V),QUA添加(S、s0),其中S是允许的状态集,s0是初始状态。然后,Q中的每个查询都被解释为S→V中的函数,U中的每个更新都被解释为S→S中的函数。
QUAs可以自然地支持抽象数据类型(例如集合,甚至是整个文档),这些数据类型提供更高级别的操作(查询和更新),而不仅仅是加载和存储。在针对弱一致性模型进行编程时,这些数据类型通常很重要[18],因为它们可以确保在处理并发和潜在冲突的更新时,数据表示保持完整。
与抽象数据类型相比,有两个重要的考虑因素:
- 查询操作和更新操作之间有严格的分离-不能有同时返回值的更新。
- 所有更新都是总功能,因此更新不可能失败。当然,如果不满足系统的前提条件,您可以定义一个更新函数,它不会更改系统的状态。
例如,在我们的形式化过程中,我们不允许一个带有pop操作的经典堆栈抽象数据类型,原因有二:(1)pop都会删除堆栈的顶部元素并返回它,因此它既不是更新也不是查询,(2)pop不是total,即它不能应用于空堆栈。这种限制对于实现最终的一致性至关重要,因为在这种情况下,更新的顺序和应用可能会被延迟,因此更新可能会应用到不同于程序最初发出更新的状态。
模型假设每个操作都发生在事务中。因此,只定义了“yield”,而不是显式的开始和结束事务事件。Yield标点操作流(查询和更新)以将它们划分为事务。
与共享q u A交互的一组客户端可以根据程序发出的更新u∈u、q∈q和v∈v表示客户端发出的查询和返回的响应的对(q,v)以及客户端程序发出的屈服操作来定义它们的交互。
history H将一组客户机c∈c映射到一系列操作(查询对和更新)——收益不被视为历史的一部分。在此基础上,给出了序列一致性的一组规则…
顺序一致性从根本上限制了存在网络分区时的可用性。原因是,某些事务t发出的任何查询都必须看到t之前全局排序的事务中发生的所有更新的效果,即使是在远程设备上。因此,我们不能在存在网络分区的情况下最终提交事务。
现在我们可以看到顺序一致性和最终一致性之间的根本区别:
最终一致性通过允许事务t中的查询只查看t之前全局排序的所有事务的子集来放松顺序一致性。它通过区分可见性顺序(定义查询可见的更新的部分顺序)和仲裁顺序(确定更新的相对顺序)。
给定这两个偏序,我们得到了最终一致性的一组规则。
最终一致性能够容忍临时网络分区的原因是仲裁顺序可以增量地构造,即在事务提交后的一段时间内可能只保留部分确定。这允许即使在存在网络分区的情况下提交冲突的更新。
实现者用于实现可见性排序的技术包括一般因果排序广播和成对反熵。仲裁顺序通常由逻辑或实际时间戳确定,或者通过使操作可交换以使顺序无关紧要。
在下一节(第3节)中,我们将展示如何在不使用时间戳或不要求可交换性的情况下仲裁更新,这一特性使我们的工作与众不同。我们不喜欢使用时间戳,因为它们会出现写稳定问题[20],即无法确定更新的效果,而较旧的更新可能仍在断开连接的网络分区中徘徊。
引入修订图
修订图不仅显示了每个客户机的查询、更新和事务的扩展历史,还显示了修订的分支和连接的扩展历史,这些修订是状态的逻辑副本。客户机一次只能使用一个修订版,并且可以对其执行操作(查询和更新)。由于不同的客户机使用不同的修订版,因此客户机可以同时独立地执行查询和更新(即不创建争用条件)。在联接操作期间进行协调。当一个修订加入另一个修订时,它将重放在联接点处在联接的修订中执行的所有更新。加入修订后,不能再对其执行任何操作(即,客户端可能需要派生新的修订以保持足够的修订可用)。
修订图(见下文)可以有五种不同类型的顶点:特殊起始顶点、分叉顶点、连接顶点、更新顶点和查询顶点。顶点由边连接,这些边可以是后续边、连接边或分叉边。
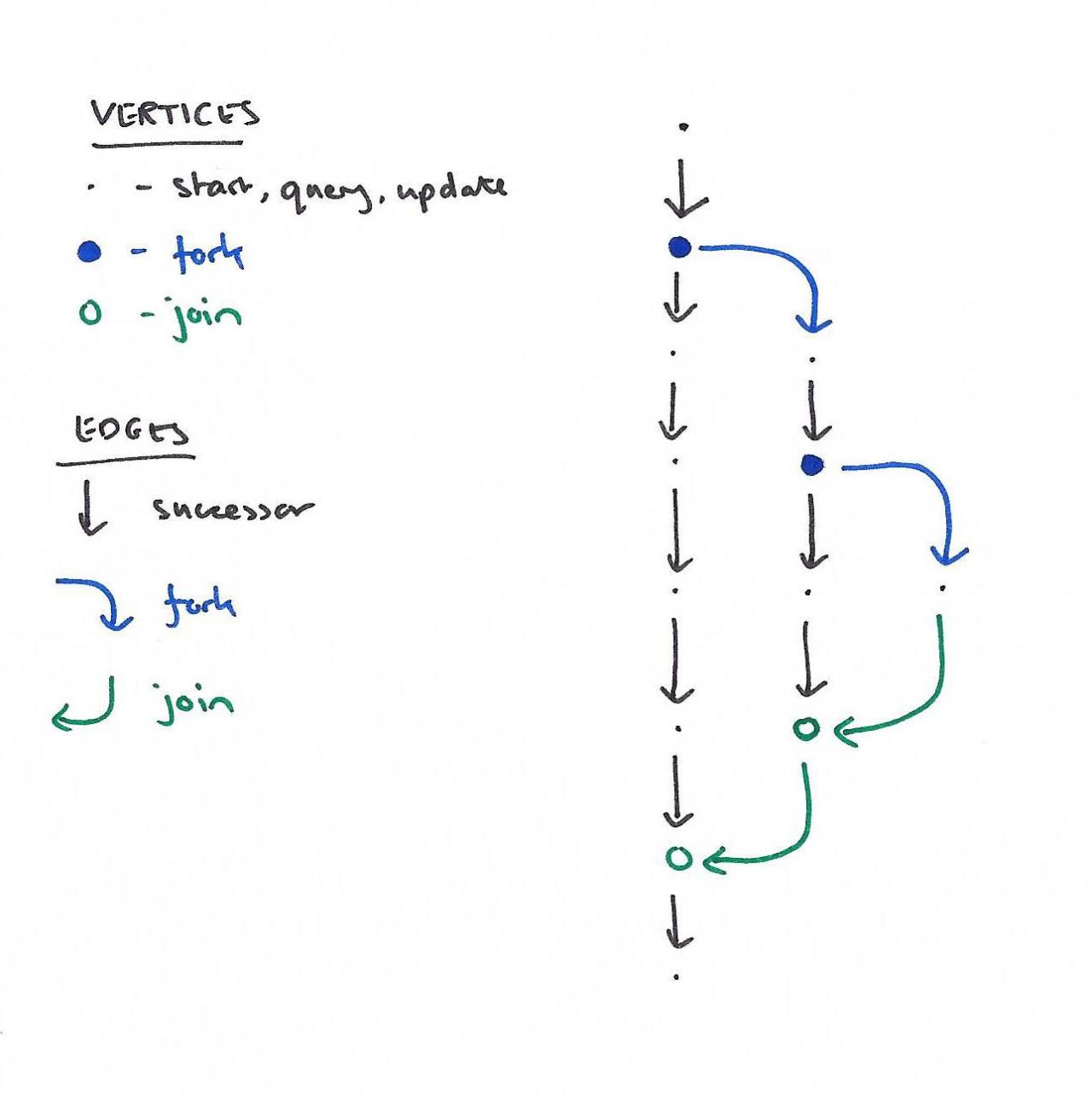
若要构造修订图,请应用以下规则的可能无限序列(从初始起始顶点开始):
- 查询:选择某个终端顶点t,创建一个新的查询顶点x,并从t→x添加后续边。
- 更新:选择一些终端顶点t,创建一个新的更新顶点x,并从t→x添加后续边。
- 分叉:选择某个终端顶点t,创建一个新的分叉顶点x,并从t→x添加后续边。为新修订创建一个新的起始顶点y,并从x→y添加分叉边。
- 连接:选择两个满足连接条件的端子t1和t2。创建新的连接顶点x,并从t1→x添加后续边,从t2→x添加连接边。
- 连接条件表示终端t1(“joiner”)必须可以从开始包含t2的修订的fork顶点(“joinee”)访问。这种情况使得修订图比一般任务图更受限制。连接条件有一些重要的,不是立即明显的结果。例如,它意味着修正图总是半格…
修订图可用于确定查询结果
我们现在继续解释如何在修订图中确定查询的结果。基本思想是(1)返回一个与沿根路径应用所有更新一致的结果,以及(2)如果沿该路径存在连接顶点,则它们将通过连接的修订总结所有更新的效果。
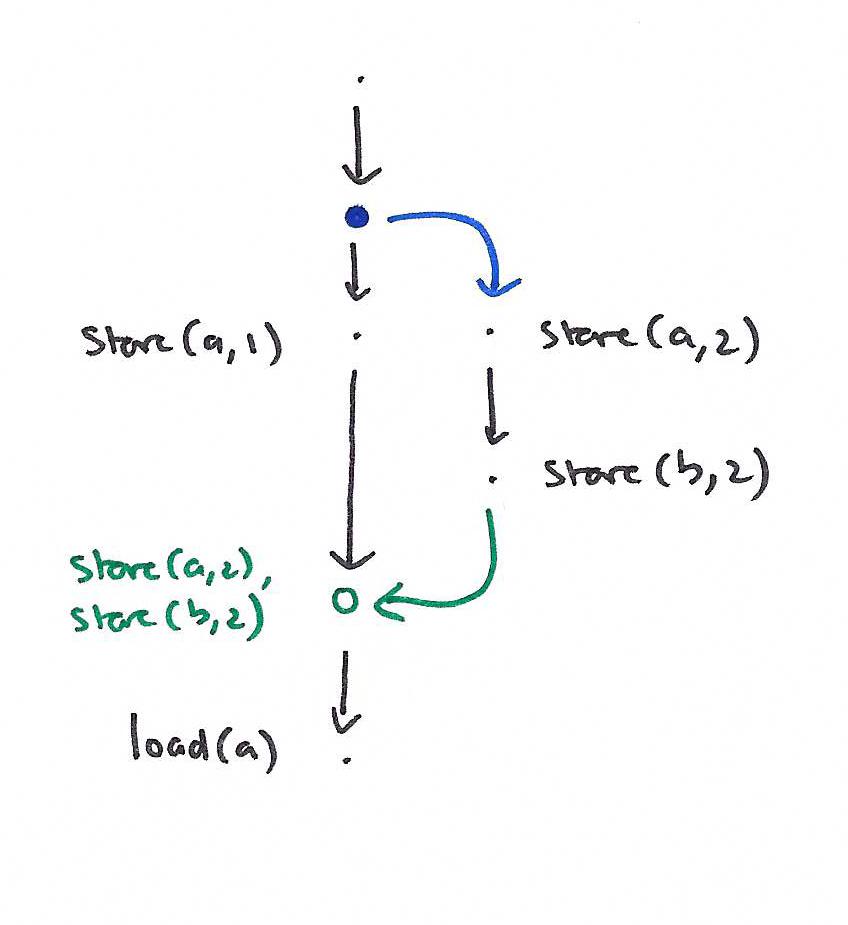
通过将每个查询事件与查询顶点相关联,以及将每个更新事件与更新顶点相关联,历史记录可以与修订关系图相关联。
其目的是使用路径结果在历史记录中验证查询结果,并通过确保事务的事件在修订中形成连续的序列来保持事务的原子性和隔离性。
这篇论文包含了一套正式的规则,使修订图被视为一段历史的忠实“见证人”。鉴于此,我们有一个基于解释修订图的最终一致性模型:
让它成为历史。如果H存在一个见证图,使得没有发生的事件被忽略,那么H最终是一致的。
(“忽略事件”是永远不会连接回主分支的终端,因此“未提交事件”条件是活动条件)。
注意,这个定理为我们实现最终一致的事务提供了坚实的基础:一个实现可以基于动态构造一个见证修订图,从而保证最终一致的事务,实现不需要在运行时实际构造此类见证关系图,但可以依赖于高效的基于状态的实现。
实例
对于基于上述思想的实现,定义fork join QUA(FJ-QUA)就足够了。这是一个QUA,正如我们之前看到的,state by convention由∑表示,加上一个fork函数f:∑→∑X∑,和一个join函数j:∑X∑→∑。
如果我们有一个fork join QUA,我们可以简单地将a∑-state与每个修订关联起来,然后在该状态上本地执行所有查询和更新,而不必与其他修订进行通信。如果实现正确,FJ-QUA的连接函数将保证在连接时应用所有更新…。由于我们可以在∑中存储更新日志,因此始终可以为任何QUA提供FJ-QUA
举例说明了如何创建一个最终一致的系统,其中包含一个同步服务器和一组客户端,以及一个使用服务器池的系统。关于他们的FJ类星体的详细信息,请参阅全文。

若有收获,就点个赞吧
0 人点赞
