论文地址: Ground:数据上下文服务 Hellerstein et al. , CIDR 2017
当代数据系统的分类性质的一个不幸后果是,缺乏一个标准机制来汇集对其管理的数据的来源、范围和使用的集体理解。
更直截了当地说,许多组织最多只能对他们拥有的数据、数据来自何处、谁使用这些数据以及依赖于这些数据的结果有一个模糊的认识。这些都是与元数据有关的问题。而元数据问题现在正触及危机点,原因有两个:
- 糟糕的组织生产力——很难找到有价值的数据,而且人类的努力经常重复。我们去年研究的Google产品和机器学习沿袭系统提供了大量证据,证明元数据系统在规模上提高了生产率(近乎必要)。
- 治理风险。随着监管机构取缔数据的使用和传输,这正成为一个日益严重的问题。
数据管理必然需要跟踪或控制谁访问数据,他们对数据做什么,把数据放在哪里,以及如何在下游使用数据。由于没有存储元数据和回答这些问题的标准位置,因此不可能强制执行策略和/或审核行为。
例如,在即将出台的GDPR法规中,如果您不能做到这一点,并且您的数据包含有关人员的信息,那么您可能会被罚款2000万美元或收入的4%,以较高者为准。
数据上下文服务是数据库技术创新的机遇,也是该领域的迫切需求。
Hellerstein等人。认为除了大数据的三个V之外,我们还应该担心数据上下文的“ABC”:应用程序、行为和变化。
A代表申请
应用程序上下文描述如何解释数据以供使用:这可能包括编码、模式、本体、统计模型等。定义很宽泛:
所有涉及到的工件——包装脚本、视图定义、模型参数、训练集等等——都是应用程序上下文的关键方面。
B代表行为
行为上下文捕获数据是如何随着时间的推移而创建和使用的。请注意,它因此跨越了多个服务、应用程序等。
我们不仅必须跟踪上游沿袭(导致创建数据对象的数据集和代码),还必须跟踪下游沿袭,包括从该数据对象派生的数据产品。
除了沿袭,行为上下文bucket中还包括使用日志。“因此,行为上下文元数据通常可以大于数据本身!”
C代表改变
更改上下文包括数据、代码和相关信息的版本历史记录。
通过跟踪跨越代码、数据和整个分析管道的所有对象的版本历史,我们可以简化调试并启用审核和反事实分析。
P代表人和目的?
添加一个“P”相当混乱的尼斯“ABC”计划,但在隐私法规(例如,前面提到的GDPR)方面,我想我也会试图召集人,也许目的是作为模型的顶级部分。(在地面上,这些将被包含在应用程序上下文中)。一个组织需要能够追踪它拥有的与某个人相关的所有信息,以及处理这些信息的每个系统。此外,根据全球数据保护条例,它还需要跟踪在收集数据时获得同意的使用目的,并能够证明数据不在这些目的之外使用。
G代表Ground
作者正在构建一个名为Ground的数据上下文服务,旨在成为有关数据及其使用的信息的单一访问点。Ground有一个共享的元模型,用于描述应用程序、行为和更改上下文信息。这个元模型是所有东西结合在一起的“共同点”。“地上”服务构建在这个元数据之上(参见下图中的示例)。“地下”服务涉及捕获和维护元模型中的信息。
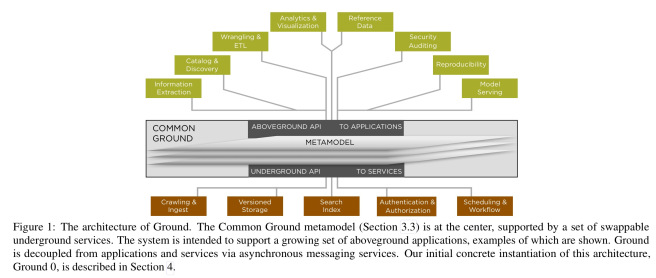
信息可以通过地上和地下两种服务进入地面:通过爬取(如在GOODS系统中)、通过restapi、通过消息总线分批或实际上是其他几种方式。当元数据到达时,Ground发布通知,这些通知可以由地面服务使用,例如,这些服务可以丰富它。
例如,应用程序可以订阅文件爬取事件,将文件交给OpenCalais或Alchemy API之类的实体提取系统,然后用提取的实体标记相应的通用元数据对象。
Ground的存储引擎必须足够灵活,以便有效地存储和检索丰富的元数据,包括版本管理信息、模型图和沿袭存储。元数据特征提取和元数据存储都是当前研究的热点。
在接收、丰富和存储元数据之后,我们可能还应该有某种搜索或查询接口来利用它。元数据用例将需要搜索样式索引(例如,查询标签)、支持分析工作负载(例如,过度使用aka exhaust data)和支持传递闭包的图形样式查询等的组合。
……各种开源解决方案可以在一定程度上解决这些工作负载,但这里有大量的研究机会。
G也表示图
每种上下文数据(应用程序、行为和更改)都由不同的图爬取。(注意,正如我们上周看到的依赖驱动分析一样,图表似乎是位于组织中所有数据之上的元数据层最自然的结构。这是图形数据库未来扩展的一个主要用例)。
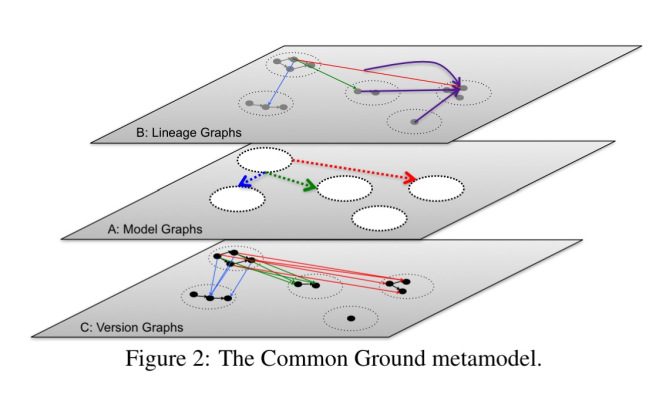
应用程序上下文由模型图表示,模型图捕获实体及其之间的关系。
变更上下文由构成模型基础的版本图表示,并捕获上面所有内容的版本。有一个很可爱的“Schródinger”版本的定义,用于像Google Docs这样的项目,这些项目的元数据是在Ground之外管理的——每次通过Ground的api访问元数据时,Ground都会获取外部对象并生成一个新的外部版本,因此,“每次我们观察到一个外部版本时,它都会发生变化。”使用这种策略,Ground可以跟踪外部对象的历史,就像地面应用程序所感知的那样。
行为上下文由关联主体(可以处理用户、组和角色等数据的参与者)的沿袭图和表示可以调用以处理数据的事物的工作流表示。地面捕捉血统作为版本之间的关系。使用数据通常可以通过分析日志文件生成。2015年10月,我们研究了一些从日志文件中提取因果链的系统(例如,The Mystery Machine和lprof)。
给出了一个“Grit”地上服务的例子,该服务跟踪git存储库、它们的提交和提交消息、其中的文件及其版本、用户和它们执行的操作。Grit很好地表明了在捕获与组织内任何涉及数据的事物相关的所有元数据时,对地面的远见的广度。
构建Ground系统
Ground的一个初始版本叫做GroundZero,主要是作为一个探索平台,来看看今天的技术构建块对于创建这样一个系统有多适合。试图将元模型信息存储在关系数据库中(在本例中是PostgreSQL),团队无法在图形处理系统的数量级内获得查询性能。使用JGraphT在Cassandra之上构建了一个内存中的图(构建图的时间不包括在下面的图中),并且性能更好。用Neo4j建模简单,查询速度快。然而,jgraft和Neo4j都只能扩展到单个节点。TitanDB扩展图在分析中没有表现出竞争力。
在日志或图形处理中没有明确的可伸缩的开源“赢家”。领先的测井处理解决方案,如Splunk和SumoLogic是封闭源,该领域的研究还不够深入。[艾克:那麋鹿堆呢?]. 有许多关于图形数据库的研究论文和活跃的研讨会,但我们发现缺乏领先的系统。
接下来呢?
Ground工程才刚刚开始。今后的工作包括:
- 数据上下文数据存储和查询的进一步研究(以及可能的新设计)
- 模式和实体提取技术的集成,包括知识库提取和系统,如DeepDive
- 从以数据为中心的工具(争用和集成)捕获消耗
- 使用用户、应用程序和数据集之间发现的使用关系来深入了解组织的运作方式
- 改善治理(见下文)
- 并将常用的建模框架(如sci-kit-learn和TensorFlow)连接到Ground
对于跨多个站点和子组织部署复杂软件网络的组织来说,强制访问控制或审核使用等简单保证变得极其复杂。这对于善意的组织来说是困难的,而对于更广泛的社区来说则是不透明的。在各方面都欢迎改善这种做法。首先,上下文信息需要易于在公共基础设施中捕获。Ground是一项努力,以实现这一开始,但在捕获和验证足够的数据血统以用于治理方面,无论是在遗留系统还是从头开始的系统中,仍有许多工作要做。

若有收获,就点个赞吧
0 人点赞
