论文地址: 对RocksDB键值工作负载进行特征化,建模和基准测试
如果您想设计一个能够在现实世界中提供出色性能的系统,那么拥有能准确代表现实世界工作负载的基准非常有用。在本文中,Facebook分析了他们在现实世界中的三个RocksDB工作负载,并发现它们看上去完全不同。更有趣的是,这些实际工作负载的行为方式与由古老的YCSB基准生成的工作负载之间存在重要差异。
因此,使用YCSB的基准测试结果作为生产指导可能会导致一些误导性的结果……为了解决此问题,我们提出了一个基于键范围的建模并开发了一个可以更好地模拟实际键值存储工作量的基准。该基准可以综合生成更精确的键值查询,这些查询表示键值存储对基础存储系统的读取和写入。
为这项工作而开发的跟踪,重播和分析工具已作为最新rocksdb发行版的一部分以开源形式发布,并且新的基准现在已成为db_bench基准工具的一部分。
TL;DR:YCSB工作负载的生成未考虑key空间内热键位置的分布。如果您的商店读取(多键)块中的数据,那将很重要。对热键的键范围分布进行建模会产生更实际的综合工作负载。
RocksDB要点
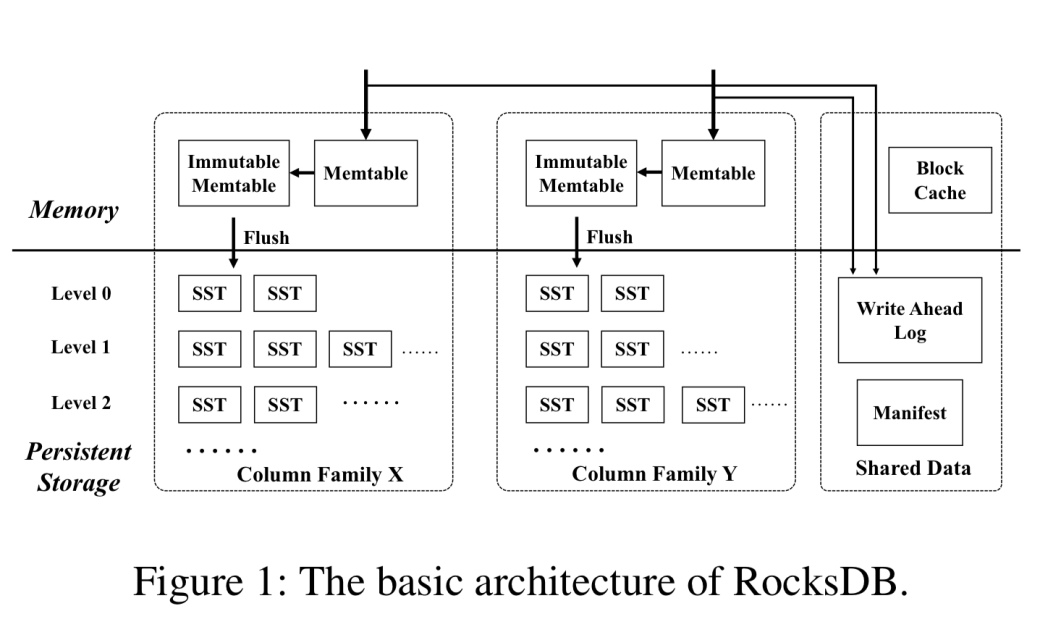
RocksDB是Facebook派生自LevelDB的键值(KV)存储,并针对SSD进行了优化。 Facebook,阿里巴巴,雅虎,LinkedIn等都使用它。它具有通常的get,put和delete操作,以及用于从给定的开始键扫描一系列连续KV对的Iterator操作,用于删除一系列键的DeleteRange操作以及用于读取-修改的Merge操作。 -写。合并存储在RocksDB中写入增量,这些增量可以堆叠或组合。要获取密钥,需要使用用户提供的合并功能来合并所有先前存储的增量。
内部RocksDB使用日志结构化的合并树来维护KV对。 ColumnFamilies具有自己的内存中写缓冲区,当写缓冲区满时将刷新到文件系统并存储为_Sorted Sequence Table(SST)文件。 SST文件有多个级别,当一个级别达到其容量限制时,将向下合并。
三种工作量
本文研究了Facebook上RocksDB的三种不同用途:
- UDB,MySQL数据库的基础存储引擎,用于存储社交图数据。所有缓存读取未命中和所有写入均通过UDB服务器进行,SQL查询被转换为RocksDB查询。对于一台代表性的UDB服务器,在14天之内处理了约102亿个查询。 Gets和Puts主导工作量。
- ZippyDB是使用RocksDB作为存储节点的分布式KV存储,用于在对象存储中存储照片和其他对象的元数据。 ZippyDB中的上层查询直接映射到RocksDB。这是一项读取密集型工作负载,每天在代表节点上处理约4.2亿个查询。
- UP2X是一个分布式键值存储,旨在支持AI / ML预测和推理中使用的计数器和其他统计信息(例如,用户活动计数)。 UP2X大量使用“合并”操作进行更新。它在Merge主导的代表性节点上每天处理约1.11亿个查询。
在显微镜下观察
鉴于这些用例有何不同,不必担心它们会以不同的方式强调RocksDB。 作者在以下方面比较了工作量:
- 查询组合(例如,gets,puts,merges,iterators…)
- 查询量(qps)
- 键的大小及其值
- 按键访问频率分布(热键)
- 热键的按键范围分布
这些中最有趣的是热键的键范围分布。 让我们先浏览其他维度,然后再回到这一点。
查询组合
Get是UDB和ZippyDB最常用的查询类型,其中以Merge为主的UP2X查询(超过90%)。 在同一应用程序中,查询组合可能因列族而异。
查询量
每台服务器每天平均对UDB的查询超过7亿次,对ZippyDB的查询为4.2亿次,对于UP2X的查询为1.11亿次。 UDB中的某些列族显示出很强的昼夜模式,而ZippyDB和UP2X的访问模式仅表现出很小的变化。
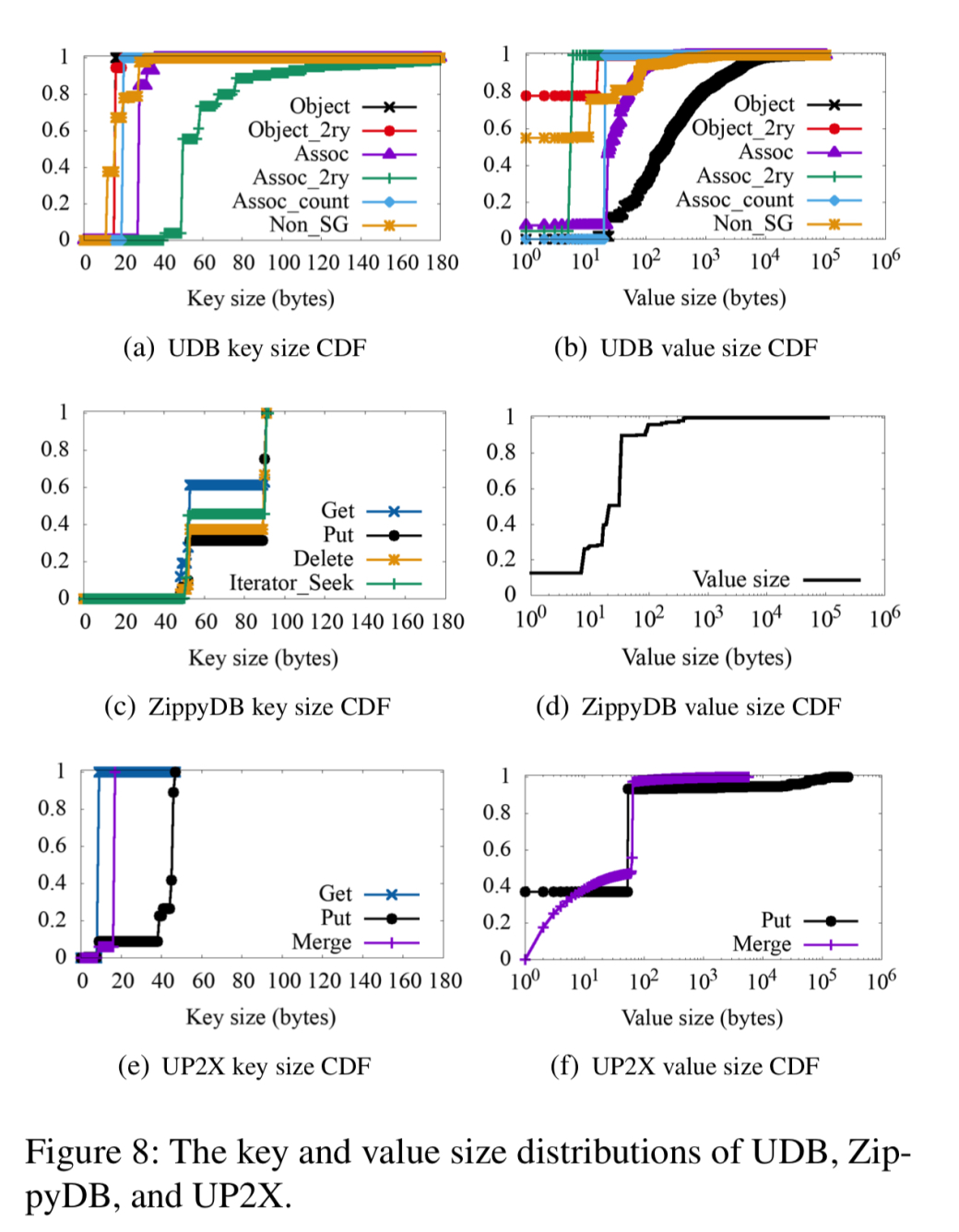
键和值的大小
key大小通常较小,分布较窄。 值大小具有较大的标准偏差,其中最大的值大小出现在UDB应用程序中。
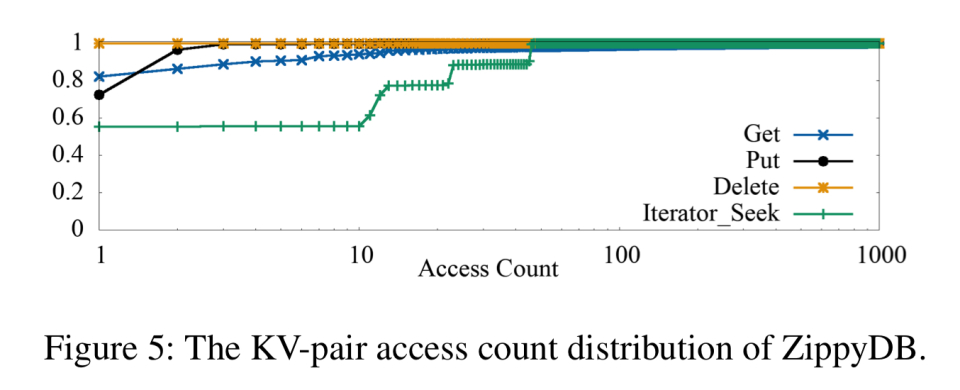
key访问频率分布
对于UDB和ZippyDB,大多数密钥都是冷密钥,而大多数KV对很少更新。 对于UDB,许多对流行数据的读取请求将由较高级的缓存层处理,因此请不要访问RocksDB。 在24小时内,只有不到3%的key被访问。

ZippyDB显示每天平均有15个get操作的键访问次数,而只有1个put或delete操作。
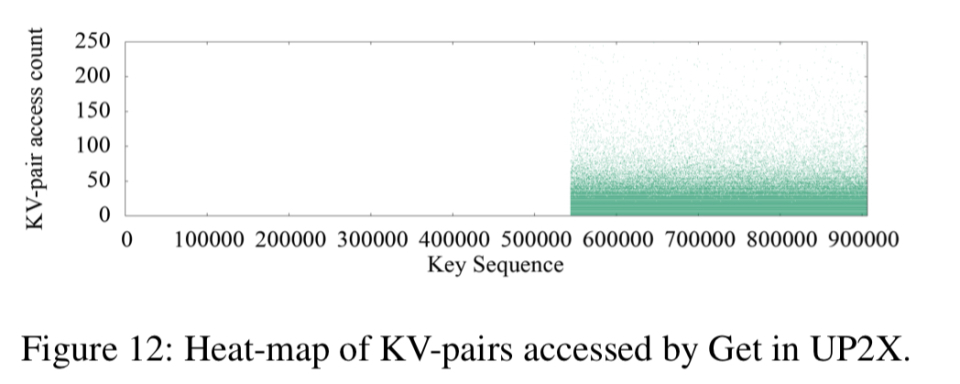
对于UPX,大约50%的Get访问的KV对和25%的Merge访问的KV对是热的。

热键的按键范围分布
事实证明,这是能够生成反映Facebook工作负载的综合YCSB工作负载的最重要因素之一。 这很重要,因为RocksDB会从数据块(例如16KB)的存储中读取数据。 因此,如果工作负载具有良好的关键位置,则需要从存储中读取的数据更少。
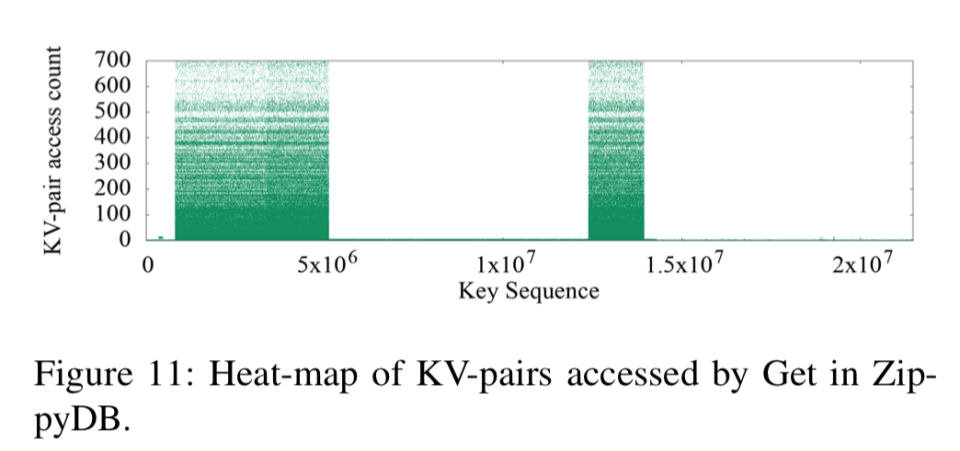
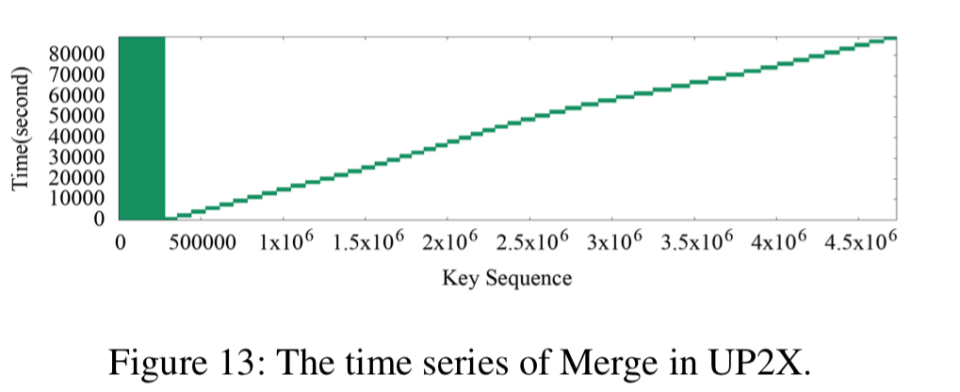
这三个用例的热图显示了很强的键空间局部性。 热KV对紧密位于key空间中。 UDB的Delete和SingleDelete以及UP2X的Merge的时间序列图显示出很强的时间局部性。 对于某些查询类型,可以在短时间内集中访问某些键范围内的KV对。
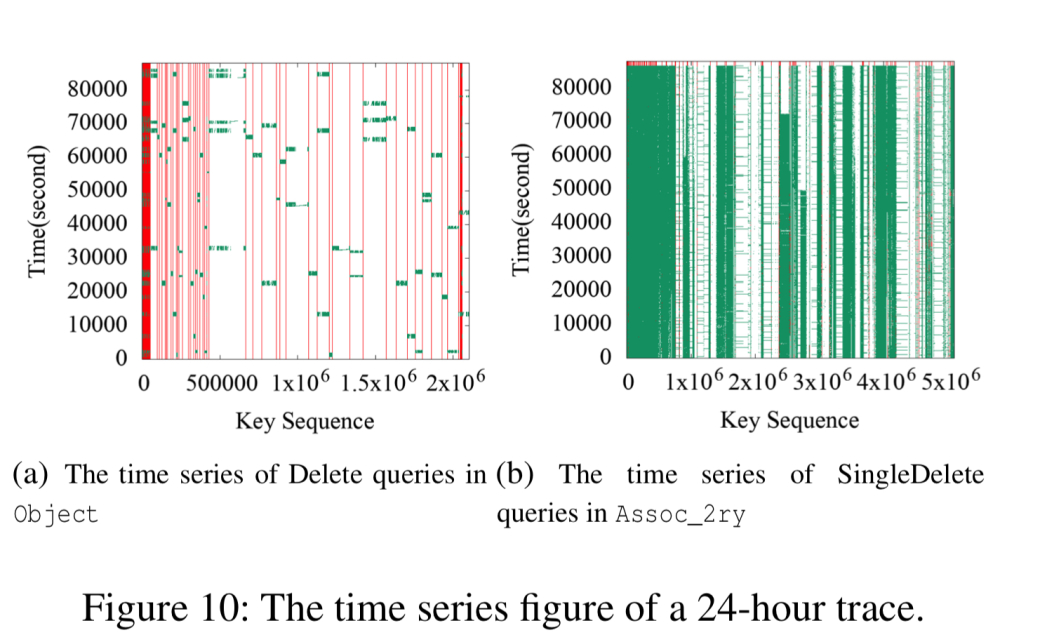
ZippyDB的热键集中在几个键范围内:
在半小时内的UP2X合并期间,会密集调用一小部分KV对:
UP2X的表现在这里很有趣,因为获取的热和冷KV对之间的界限很明确:
更好的基准测试
掌握了这些工作负载的详细跟踪信息后,关键问题是是否可以使用YCSB准确地复制它们:
研究人员通常认为YCSB生成的工作负载接近于实际工作负载。
YCSB使您可以调整查询类型比率,KV对热度分布和值大小分布。但是,它不能让您控制热键的键范围分布。有关系吗作者生成了YCSB工作负载,以使其尽可能接近ZippyDB工作负载的参数(用作典型的分布式KV存储),并测量了所得的存储I / O统计信息,以将其与正在仿真的实际工作负载(例如,块)进行比较。读取,阻止缓存命中,读取字节,写入字节)。
与真正的ZippyDB工作负载相比,YCSB工作负载显示出非常高的读取放大率(7.7x块读取,6.2x字节)。
该评估表明,即使由YCSB生成的总体查询统计信息(例如查询数量,平均值大小和KV对访问分布)与ZippyDB工作负载的统计信息相近,但RocksDB存储I / O统计信息实际上是完全不同的。 db_bench也有类似情况。因此,使用YCSB的基准测试结果作为生产指导可能会导致一些误导性的结果……。导致严重的读取放大和较少的存储麻烦的主要原因是对key空间局部性的无知。
因此,显然要做的是在为综合工作负载生成操作时考虑键范围分布。将密钥空间划分为多个范围(使用每个SST的KV对的平均数量作为范围大小),并计算每个key范围的每个KV对的平均访问次数,并以最小拟合标准拟合到分布模型实际工作负载(例如幂,指数,Webull,帕累托,正弦)的误差。该技术已集成到db_bench中。 QPS模型控制两个连续查询之间的时间间隔。生成查询时:
- 查询类型是从查询类型的概率分布中得出的
- key大小和值大小取决于所安装模型的大小
- 根据key范围访问概率选择key范围
- 根据KV对访问次数的分布来选择所选范围内的key
下表显示了所产生的工作负载(Prefix_dist)比任何YCSB生成的工作负载都更接近真实统计信息(规范化线)。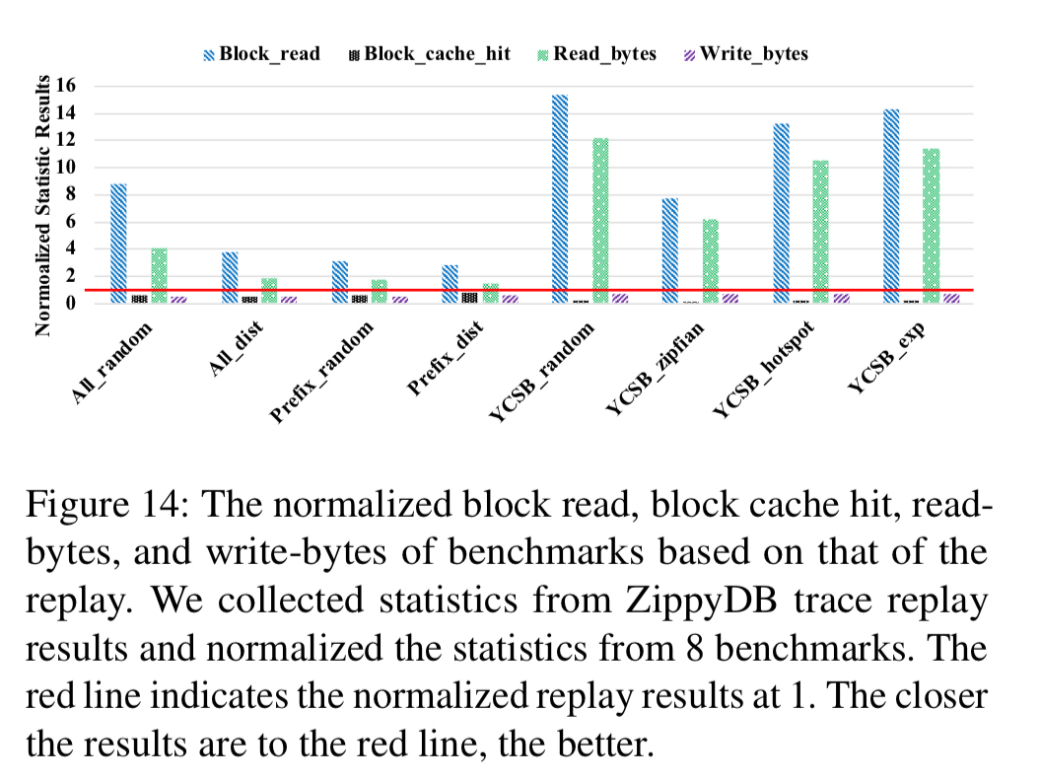
将来,我们将进一步改善YCSB工作负载的生成。 与键范围分布。 此外,我们还将在其他维度上收集,分析和建模工作负载,例如查询之间的相关性,KV对热度和KV对大小之间的相关性,以及其他统计信息,例如查询延迟和缓存状态。

若有收获,就点个赞吧
0 人点赞
