论文地址: 甘道夫:一个智能的端到端分析服务,用于在云规模的基础设施中安全部署 Li et al., NSDI’20
大规模的现代软件系统是极其复杂的不断变化的环境。尽管您可能会使用所有的部署前测试,但这使得很难自信地更改它们。因此,通常使用某种形式的分阶段发布,在运行过程中监视进度,如果看起来是导致问题的,则可以回滚更改。到目前为止还不错,但是观察一个问题然后将其连接回给定的部署可能远不是那么简单。本文描述了过去18个多月微软Azure生产中的软件部署监控器Gandalf。甘道夫每天分析超过20TB的数据:平均270K个平台事件(峰值770K),6亿个API调用,2000多个不同故障类型的数据。如果Gandalf不喜欢这些数据告诉它的内容,它将暂停一个发布,并向开发团队发送一个警告。
自推出以来,甘道夫大大缩短了部署时间,将整个生产车队的部署时间减少了一半。随着团队对甘道夫有了更多的经验,并看到它如何能够检测出即使是人类专家也可能漏掉的复杂故障,他们最初对自动化系统的不信任彻底扭转了局面:
对于许多团队来说,部署政策已经变成,除非甘道夫批准,否则部署不会继续到下一个区域。
甘道夫对其所有决定的透明度,提供了对所有支持证据的充分互动访问,在获得信任方面发挥了重要作用。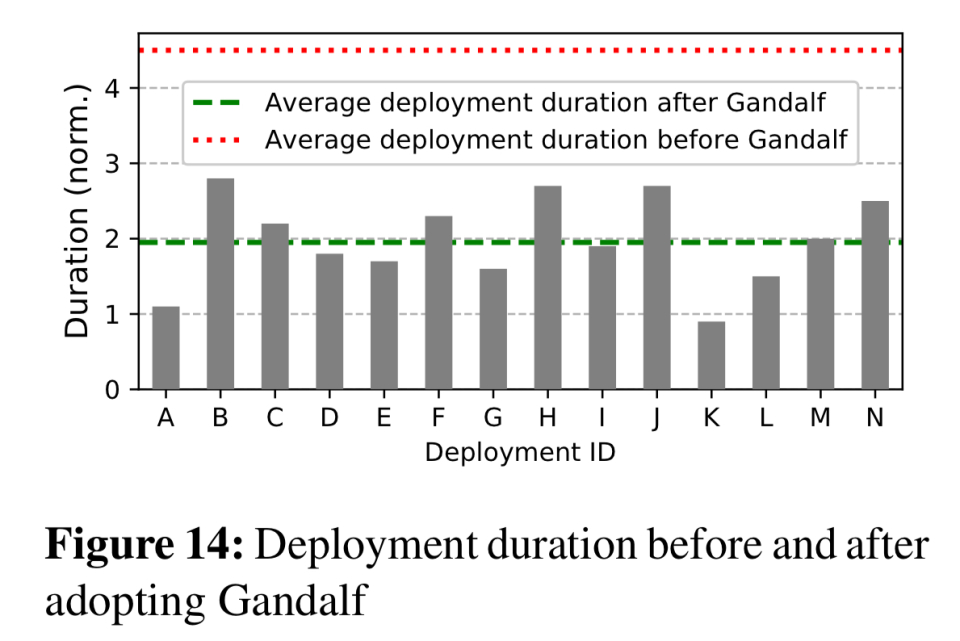
为什么很难发现一个糟糕的首次展示?
首先,有很多!所以,你并不是在试图评估一个变化对稳定基础的影响。取而代之的是,在任何时间点,the fleet都会出现多轮变革浪潮。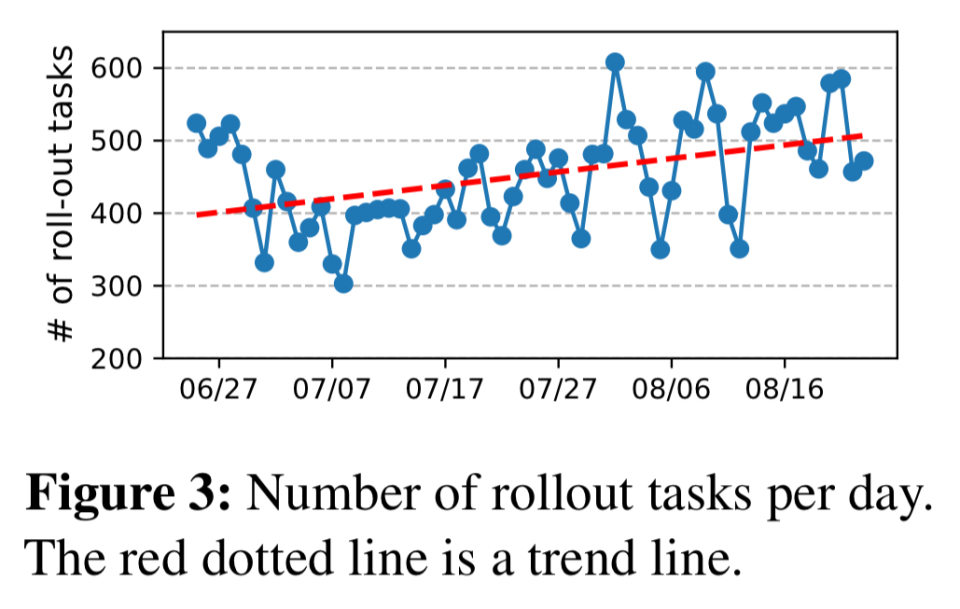
每一个变化都将经历一个阶段部署,通常由阶段、金丝雀、轻区域、重区域、半区域对和另一半区域对组成。超过70%的卷展面向多个群集。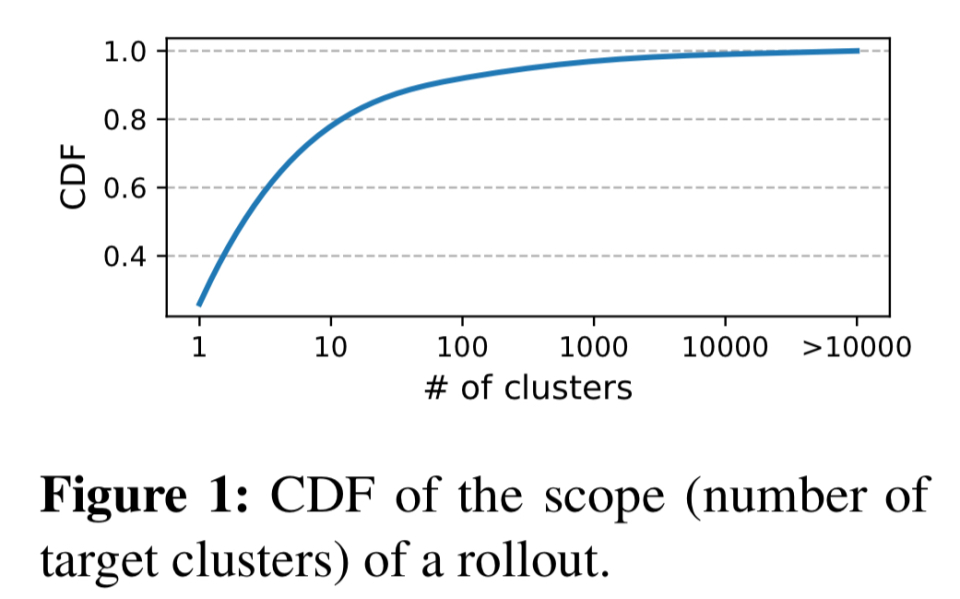
超过20%的发布持续时间超过1000分钟。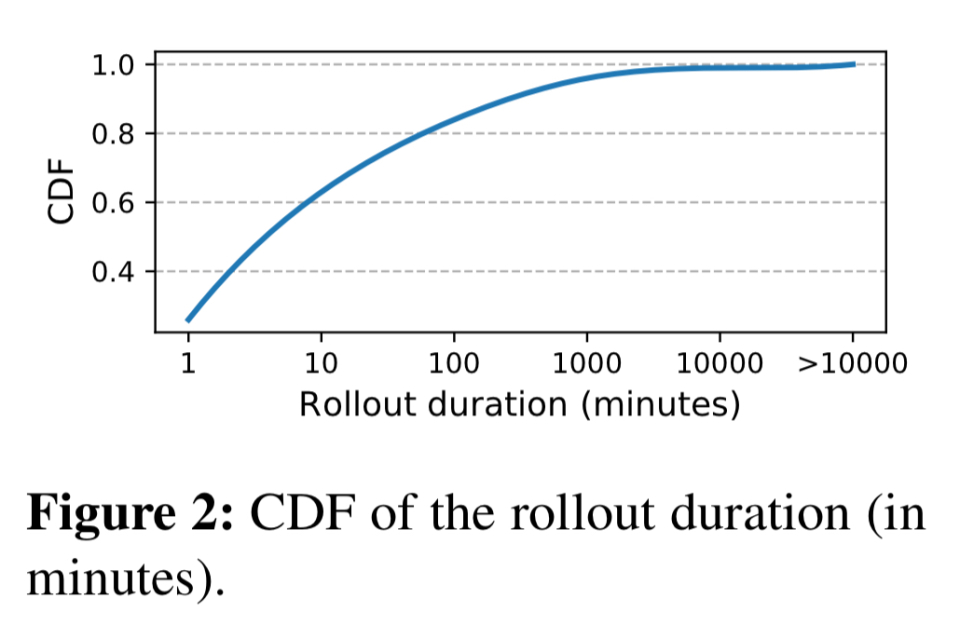
在我们深入分析一些令人困惑的因素之前:错误总是在发生,而不是所有的错误都是由软件发布引起的(我们不希望出现错误的警报);在发布和出现问题之间可能会有很大的延迟(例如,内存泄漏需要几个小时才能形成问题);并且可能会有仅在特定用户、硬件或软件配置中出现的问题。
所有这些都意味着甘道夫在理解所有这些数据方面面临四大挑战:
甘道夫需要能够应对系统和信号的不断变化:新的部件出现,现有的部件进化,改变故障模式和遥测信号。
由硬件故障、网络超时和灰色故障等引起的环境故障一直在发生,其中许多故障与部署无关。甘道夫因此在一个非常嘈杂的环境中工作。
快速发现问题,同时随着时间的推移收集全面的信息以捕获延迟的问题。
一旦发现一个真正的问题,找出哪个变化是可能的原因!
组件和故障之间存在n到m映射关系:一个组件可能导致多种类型的故障,而一种类型的故障可能由多个组件中的问题引起。由于组件行为的复杂性,很难找出哪个组件可能导致哪个故障。
甘道夫系统设计
在高层次上,甘道夫是这样的:
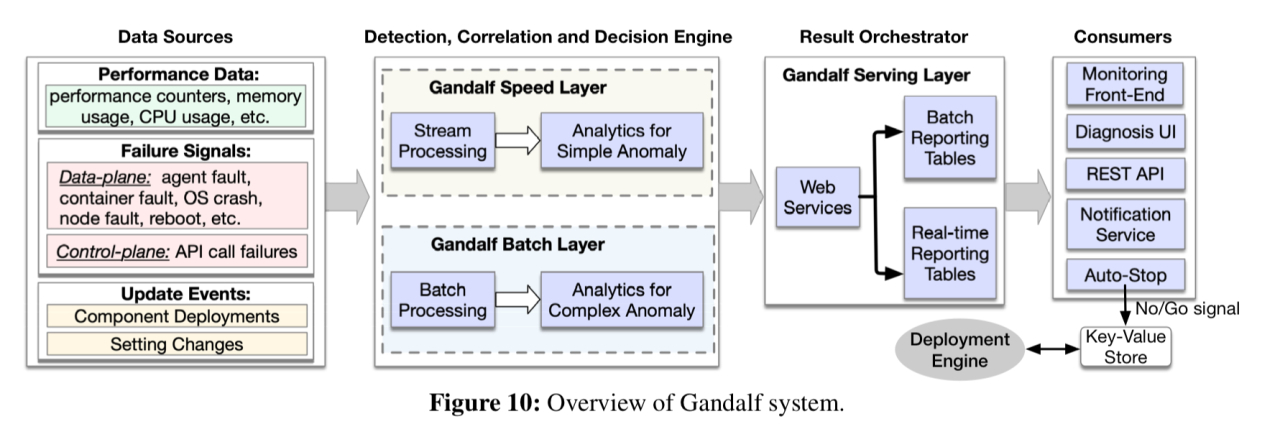
它接收性能数据、故障信号和组件更新事件,并通过快速和慢速路径(lambda体系结构)传递它们。快速路径能够检测简单、即时的问题并提供快速反馈(5分钟内)。批处理层可以检测延迟(潜在)问题,分析更复杂的故障场景,并提供更详细的支持证据。
速度层的分析引擎只考虑每个节点每次部署前1小时和部署后1小时发生的故障信号,并运行轻量级分析算法以提供快速响应。在Azure中,大多数灾难性问题都发生在发布后的1小时内。1小时后发生的潜在故障将在稍后由批处理层捕获。
快速路径和慢速路径的组合输出被输入到Gandalf的系统界面中,前端用于开发人员实时查看推出状态,以及用于诊断问题的UI。Azure部署引擎订阅Gandalf的go/no-go决策,并在发布“no-go”决策时停止部署。
从信号到决定
在设计Gandalf算法时,我们考虑了监督学习、异常检测和相关分析的现有方案,但发现每种方案都有很大的局限性。
监督学习与底层系统中信号和故障模式的不断变化作斗争。异常检测是不够的,因为有许多卷展同时发生,它无法区分它们。基于皮尔逊相关的相关分析无法捕捉到复杂的因果关系。
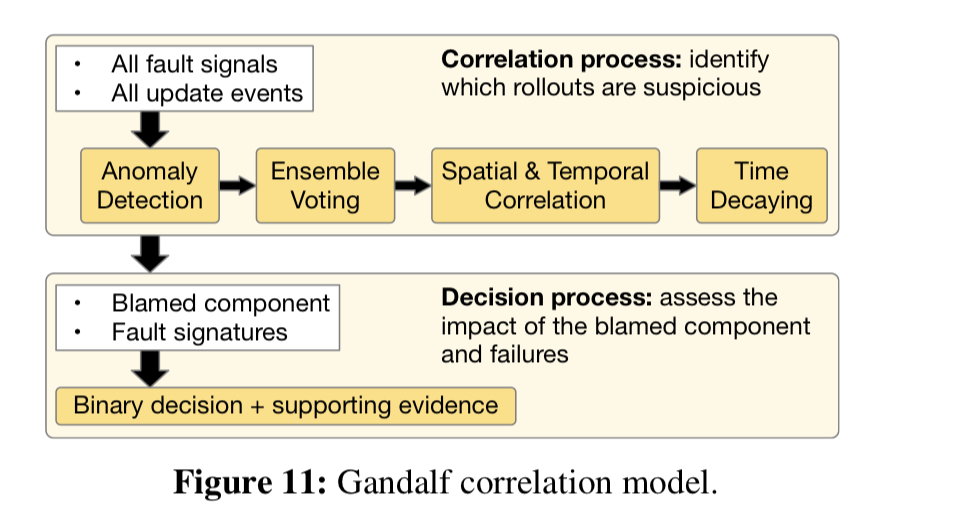
最终得到了一个三相分析流程:异常检测、相关分析,然后是一个决策引擎。
**
Gandalf在日志消息周围进行文本聚类以生成故障特征,然后根据每个特征的出现情况应用异常检测。考虑到工作负载和系统本身的变化性质,简单的阈值是不够的,因此甘道夫使用霍尔特温特斯预测来估计基线,使用前30天的数据和一个小时的步长间隔。
相关分析阶段的工作是试图找出哪个组件可能对检测到的异常(如果有的话)负责。相关性是基于集体投票和否决。对于在时间t时部署在某个节点上的组件更改,在t将该组件更改投票作为可能的原因之后发生的故障。在t否决组件更改之前发生的故障是可能的原因。“before”和“after”使用四个不同的时间窗口(1小时、1天、3天…)。每个时间段的投票和否决都是加权的(指数衰减),因此较小的时间间隔贡献更多。
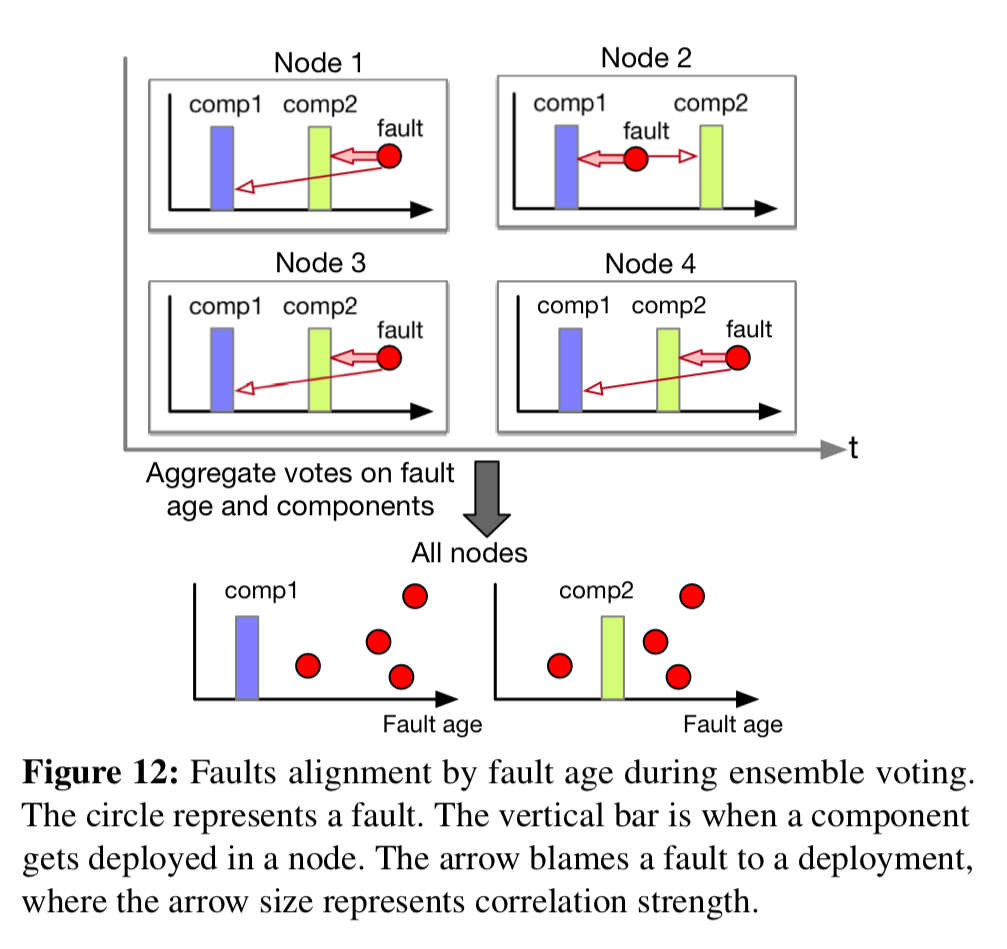
为了产生最终的责怪分数,第二个指数时间衰减因子被纳入其中,为最近的发布提供了更多的权重。
给出一个组成部分和一个责备分数,是时候做出一个去/不去的决定了。
我们通过评估部署的影响范围(如受影响集群的数量、受影响节点的数量、受影响客户的数量等)来为组件c_j做出通过/不通过的决策。。不必为每个特征设置静态阈值,而是使用高斯判别分类器动态训练决策准则。培训数据由历史部署案例生成,并由组件团队提供反馈。
甘道夫框架运行模式
甘道夫在大约5分钟内,在快速通道上,在大约3小时内,在批处理层上,进行端到端的决策。在8个月的时间窗口中,甘道夫在数据飞机推出的早期阶段捕获了155个关键故障,准确率达到92.4%和100%(没有高影响事件超过甘道夫)。在控制飞机上,甘道夫报告了39起事故,其中两起误报。准确率为94.9%,召回率为99.8%。
甘道夫发现的最常见的问题是兼容性问题和违约问题。在具有最新硬件或软件堆栈的环境中测试更新时出现的兼容性问题,但部署的节点可能具有不同的硬件sku或操作系统或库版本。当组件不遵守其API规范并中断依赖组件时,就会出现契约中断问题。

若有收获,就点个赞吧
0 人点赞
