论文地址:规模的长尾效应——Dean和Barroso,2013年
我们都已经熟悉了容错的重要性以及可以用来实现它的技术。不太为人所知的是尾部公差的概念。一个响应不够快的系统会给用户带来笨拙的感觉,并且会对网站/服务的可用性产生严重的负面影响,最终会产生连锁反应。根据Jeff Dean和巴罗佐的说法,谷歌的响应系统目标是100毫秒。
正如容错计算的目标是用不太可靠的部分创建一个可靠的整体一样,大型在线服务需要用不太可预测的部分创建一个可预测的响应整体;我们将这类系统称为“延迟尾容”,或者简单地称为“尾容”
有很多原因可以解释为什么一个请求时不时会花费比预期更长的时间(本文给出了八个例子)。我们需要多好才能达到应对目标?如果99%的响应时间在我们的目标范围内,那就足够了吗?
考虑一个系统,其中每个服务器通常在10毫秒内响应,但第99个百分位的延迟为1秒。如果一个用户请求只在一个这样的服务器上处理,那么100个用户请求中的一个将是慢的(1秒)。
Latency Numbers Every Programmer Should Know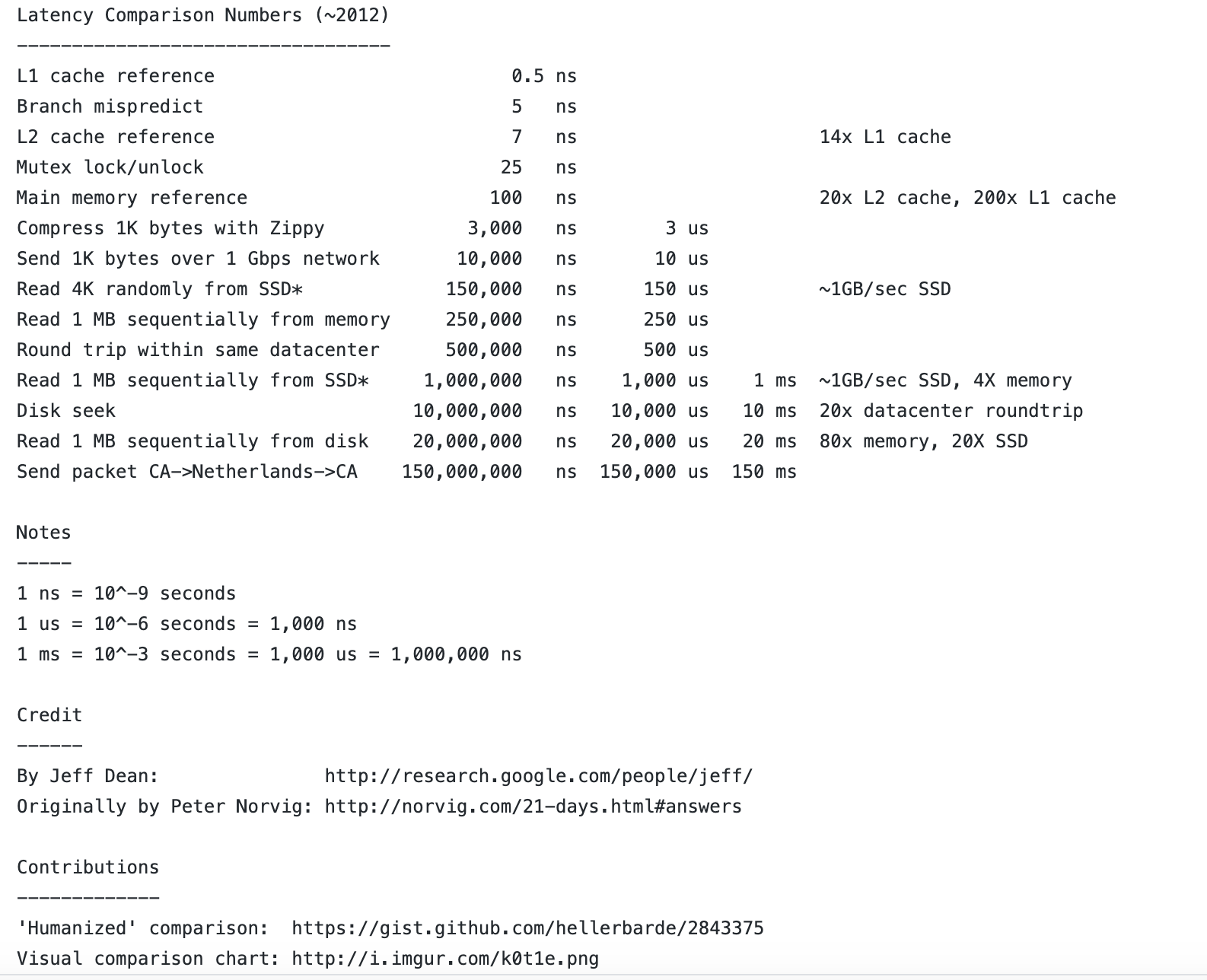
有很多原因可以解释为什么一个请求时不时会花费比预期更长的时间(本文给出了八个例子)。我们需要多好才能达到应对目标?如果99%的响应时间在我们的目标范围内,那就足够了吗?
考虑一个系统,其中每个服务器通常在10毫秒内响应,但第99个百分位的延迟为1秒。如果一个用户请求只在一个这样的服务器上处理,那么100个用户请求中的一个将是慢的(1秒)。
也许没关系。但是,当不只是一个服务器参与服务请求,而是100个服务器时,请注意会发生什么。例如,扇出查询或大量微服务导致了结果:
如果一个用户请求必须同时从100个这样的服务器收集响应,那么63%的用户请求将花费超过1秒的时间。即使对于只有万分之一请求在单服务器级别经历超过1秒延迟的服务,具有2000个这样的服务器的服务也将看到几乎五分之一的用户请求占用超过1秒的时间。
在这种情况下,即使您的99.99%的百分位响应时间是正常的,20%的用户看到一个糟糕的响应时间!!很容易计算出你自己场景的总和:只需取你可接受的延迟百分比(例如0.999),并将其提高到参与响应的服务器数量的能力。
对于一个真正的Google系统,任何一个请求的延迟都是10ms,99%的延迟是140ms,95%的延迟是70ms。
…这意味着,等待最慢的5%的请求完成将导致99%的总延迟的一半。专注于这些缓慢离群值的技术可以显著降低总体服务性能。
希望现在你能确信,当涉及到反应时间时,长尾效应真的凸显出来。我们如何设计系统来容忍尾部延迟,并且总体上仍然具有响应性?
首先,您可以尝试降低响应时间的可变性,方法是对交互请求进行优先级排序,将大的工作单元分解为更小的部分以允许交错(也称为减少线前阻塞),并仔细管理后台活动。在某种程度上,与直觉相反的是,最好同步后台任务,使其同时在所有计算机上运行,而不是随着时间的推移将其分散开来。思考一下尾巴的含义会揭示出为什么…
这种同步在每台机器上同时执行一个短暂的活动突发,只会减慢在后台活动的短暂时间内处理的交互请求。相反,如果没有同步,一些机器总是执行一些后台活动,从而推掉所有请求的延迟尾部。
不过,到最后,你永远无法完全限制延迟的可变性,所以你需要考虑能够容忍它的设计模式。以下是7种增强尾部公差的模式:
1) 对冲请求:将相同的请求发送到多个服务器,并使用最先返回的任何响应。不过,为了避免计算量增加一倍或三倍,不要直接发送套期保值请求:
延迟发送次要请求,直到第一个请求的未完成时间超过此类请求的95%预期延迟。这种方法将附加负载限制在5%左右,同时大大缩短了尾部延迟。
2) 绑定请求:不是在发送对冲请求之前延迟,而是在多个服务器上模拟排队请求,但将它们绑定在一起,但告诉每个服务器还有哪些服务器在其队列中。当第一个服务器处理请求时,它告诉其他服务器从其队列中取消该请求。由于取消消息通过网络…
…客户端在发送第一个请求和发送第二个请求之间引入两倍于平均nework消息延迟(在现代数据中心网络中为1毫秒或更少)的小延迟是有用的。
在一个真正的Google系统中,这种绑定请求机制将平均延迟减少了16%,并在99.9%时减少了40%。
3) 微分区:比服务器有更多的分区来帮助解决不平衡。
假设平均每台机器20个分区,系统可以以5%的增量和1/20的时间减少负载,如果系统只是简单地将分区映射到机器。
4) 有选择地增加复制因子:增加检测到或预测将很热的分区的复制因子。负载平衡器可以帮助分散负载。
Google的主要Web搜索系统使用这种方法,在多个微分区中对流行的和重要的文档进行额外的拷贝。
5) 将慢的机器脱离当前运行作业分区。当检测到慢速机器时,将其暂时排除在操作之外(断路器)。由于慢行的来源通常是暂时的,请监视何时使受影响的系统重新联机:
继续向这些排除的服务器发出影子请求,收集它们的延迟统计信息,以便在问题减轻时将它们重新合并到服务中。
6) 考虑“足够好”的服务响应。一旦所有服务器中有足够的一部分做出响应,就可以通过给用户提供不完整的结果来换取更好的端到端延迟,从而为用户提供最好的服务。另请参阅调光开关的相关概念。
7) 使用金丝雀请求。
在扇出率非常高的系统中可能出现的另一个问题是,某个特定的请求执行未经测试的代码路径,同时在数千台服务器上造成崩溃或极长的延迟。为了防止这种相关的崩溃场景,Google的一些IR系统采用了一种称为“canary请求”的技术;根服务器不是最初向数千个叶服务器发送请求,而是先向一个或两个叶服务器发送请求。只有当根用户在一段合理的时间内从金丝雀获得成功的响应时,才会查询其余的服务器。

若有收获,就点个赞吧
0 人点赞
