论文地址: 固定因果一致性——Bailis等人。2013年
“可能没问题”似乎反映了主流应用程序开发人员对使用最终一致的存储的态度。多亏了Bailis等人的工作。在PBS上,我们现在可以量化“可能”。乍一看,它看起来相当不错,在很短的时间内就可以达到99%以上的概率。但是,处理的事务量越大,这对您的影响就越大:(a)事务之间的窗口越短,增加了过时的可能性,以及(b)您在更大的绝对数中所占的百分比。假设每天有100万笔交易,在正常情况下有99.99%的可能性出现紧急情况,即每天有100次过期读取。可以吗?当然,这取决于您的应用程序语义。经过一年的运作,你将有36500个陈旧的阅读-它可能会没事?!
假设您使用最终一致的存储是因为可用性、低延迟、分区容忍度和可伸缩性(而不是因为偶尔出现异常是有趣的;)。研究表明,通过升级到最终一致性(称为因果一致性)可以实现所有这些属性。因果一致性表示,如果A可能导致B(A发生在B之前),那么如果你阅读B,你肯定会看到A(或者A的更新并发更新)。典型的例子是一个注释线程——你不会看到对注释的回复,同时也会看到被回复的注释。因果一致性非常符合人类对系统行为的期望。
不幸的是,大多数程序提供最终一致性或严格一致性(丢失ALPS属性)的选择,尽管我们希望使用因果一致性。在协议世界中,我们已经习惯了在更一般的协议之上再加上更强大的保证。我们有TCP/IP,那么为什么不使用CC/EC(因果一致性在最终一致性之上分层)?在“螺栓连接因果一致性”中,Bailis等人。在最终一致的底层存储(如Cassandra)上构建一个确切的分层,展示如何为客户实现因果一致性。这是一个非常有趣的想法,评估结果表明它实际上可以加快请求处理速度,而不是减慢处理速度。谁不希望更快的结果加上更有力的保障?不过,据我所知,这个想法还没有流行起来。这让我怀疑,“名字里有什么?”. 文中所用的语言充满了“插销”和“垫片”,在我的脑海中,这种语言给人的印象是,这一切都有点老生常谈,胡说八道,胡说八道…。但事实并非如此。当你读这篇文章时,试着用“分层一致性”来代替“螺栓连接”,用“代理”来代替“填充”。然后我们得到的是通过局部无共享代理的分层因果一致性。看,你已经更喜欢了;)。
让我们回到最终一致性下的注释线程示例。想象一下,你的任务是写一个将要进行讨论的客户。“把评论搞得乱七八糟有什么大不了的?“你可能在想。这似乎很简单:当您得到一个新的注释时,只要看看它的“inResponseTo”字段,如果您还没有父注释,那么它是响应的,您可以在本地缓冲此注释,直到您收到父注释,或者显式关闭并获取它。当然,如果这个评论是“inResponseTo”,那么在你回到根目录或者你已经拥有的东西之前,你不需要重复这个过程。
恭喜,你刚刚发现了因果链的概念!让我们概括一下:可能您正在读取的数据项没有“inResponseTo”字段,因此我们无法使用延迟或获取策略-我们可以通过将元数据中的“inResponseTo”信息与数据项放在一起来解决这个问题。也许最近的那篇文章不仅仅是对因果链中的一个父项的回应——也许我以前读过三个不同的条目,它们都在某种程度上促成了我刚才的写作。因此,我们将保留一个集合,而不是在因果链中保留一个单亲。
因果一致性的实现通常有两个组件:依赖跟踪和本地存储。附加到每个写操作的依赖关系跟踪元数据用于记录有关其因果历史的信息,从而确定写操作发生在关系之前。进程保留键和值的本地副本,称为本地存储,保证(通过设计)始终具有因果一致性。进程提供本地存储的读取,并使用依赖项跟踪确定何时用更新的写入更新本地存储(应用它们)。
这就留下了一个问题:如何首先确定写操作的因果依赖关系,以便我们可以将这些信息保存在依赖关系元数据中。有两种方法。保守的方法(潜在的因果关系)有效地说“应用程序逻辑对我来说是一个黑匣子,我知道客户以前读过x、y和z,因此,我必须假设其中任何一个都有可能是正在写入的值的原因。“另一种方法是显式方法(显式因果关系),在这种方法中,客户告诉我们依赖关系是什么:“我写入这个值是为了响应x和y。”。本文中的分层因果一致性设计使用显式因果关系,这有助于保持我们需要跟踪的元数据的数量合理。
分层一致性方法实现了关注点的清晰分离。较低(最终一致)层负责活跃性、处理复制、持久性和聚合。上层(因果一致)在上层建立安全保证。
如今,系统并没有将安全性和活性特性分开。这使得关于数据一致性的推理变得困难,因为系统通常提供稍有不同的一致性保证。一个附加的体系结构可以跨多种存储系统提供相同的一致性模型。正确的shim实现不应违反底层数据存储保证的属性。例如,如我们所建议的,如果底层存储的任务是提供活动性保证,那么正确的填充程序也应该始终是活动的;错误的填充程序实现可以通过无限期阻塞来违反活动性,但是,如果它是这样做的,就不会是由于底层存储。类似地,如果shim不负责持久性或容错性(这是委托给底层存储的问题),那么shim中包含的信息应该被视为“软状态”,可以从底层存储中重建。如果需要在存在分区的情况下使用shim,则它不应依赖于其他shim进程:可以将shim内部通信用作优化,但不需要用于可用性。
几乎没有假设(这些假设几乎适用于所有最终一致的存储实现),因果一致的层可以构建在任何最终一致的数据存储(ecd)之上。
当我们试图将因果链方法放在ecd之上时,有一个棘手的问题:典型的ecd不像事件存储那样,它保留每个更新(事件),而通常有一个寄存器模型,其中较新的写操作会覆盖以前的值。这意味着垫片可能会漏写,因此因果关系链可能会断开。
把ECDS写传播看作一个不可靠的网络的一种方法是保证每个密钥只传递一条消息。我们可以使用N2密钥在N个shim进程之间建立一个可靠的网络,但这是低效的。或者,我们可以通过为每次写入存储一个新的数据项来避免完全覆盖,但这需要在执行的写入次数上保持线性存储。这些解决方案都很昂贵。
相反,作者引入了因果削减的概念
为了理解何时应用write是安全的,我们将因果一致性的正确性标准重新定义为一个更通用的声明性规范,它受到(操作)隔离级别定义的声明性翻译所提供的清晰性的启发…。因果剪切中每个写操作的依赖项应该是i.)在剪切中,ii.)在写入已在剪切中的同一密钥之前发生,或者iii.)与写入已在剪切中的同一密钥同时发生。这意味着一个切割包含每个键的“最新”版本,沿着沿着切割边界的历史的至少一个并发分支结束。因果一致系统保持了每个局部存储是因果割的不变量。
鉴于历史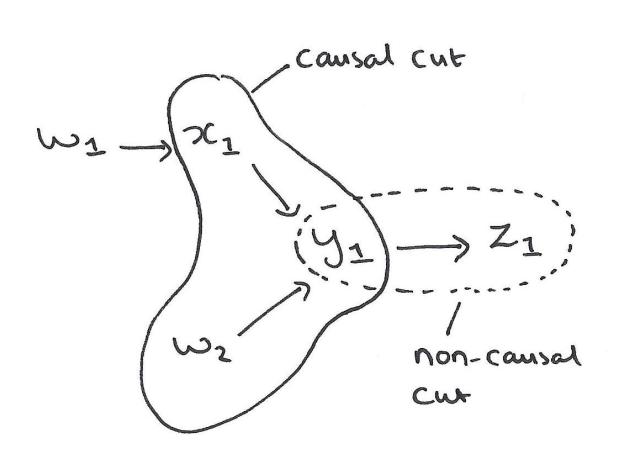
那么{w1,x1,y1},{x1,w2,y1},{w1,x1,y1,z1},{w2,x1,y1,z1},{w1},{w2},{w1,x1}和{w2,x1}都是因果割的例子,但是{w1,z1},{x1,z1}和{y1,z1}不是。
给出了因果割的定义…
bolt-on因果一致性的基本前提很简单:在向客户揭示write w之前,shim需要确保w及其本地存储L(即{w}∪L)中的一组write是因果切割(w由L覆盖)。如果是这样,它可以将w应用于L。ecd的写传播意味着在执行此检查时需要注意垫片…。
我们需要一种跟踪写入依赖项的方法:
为了计算因果覆盖,我们需要知道每个写操作的依赖关系,并能够对它们进行比较。在重写历史记录的情况下,我们必须在每次写入时存储依赖集。我们不需要存储整个历史,但是依赖集的预期大小是因果历史中键的唯一数目(而不是唯一版本或写入的数目)。依赖集中的每个写操作都需要有关写操作的元数据,这些元数据可以由一个向量时钟表示(需要与历史记录中写操作的键数成比例的空间)。
当客户机执行写操作时,填充程序会更新本地存储,并将更新和依赖关系元数据一起发送到未配置的ecd。与本地存储一起写入必须形成因果切割,因为客户端只允许读取本地存储中的值。
对于读取,如果填充程序已经在其本地存储中包含该数据项,则可以安全地返回该数据项。因此,所有读取都可以在本地完成,本地存储中的数据项可以通过解析器异步更新。没有假设底层ecd支持通知,所以这是通过轮询完成的。
假设解析器从ecd读取w。如果我们希望保持本地存储L始终是写入的因果割的不变量,那么解析器需要检查w的依赖项。解析器进程遍历w的每个依赖项,并确保本地存储包含依赖项本身、稍后(发生在之后)对依赖项的键的写操作或对依赖项的键的并发写操作。如果缺少依赖项,解析器可以尝试从ecd中读取依赖项(如在实现中),或者推迟进一步的检查并转到下一个键。
在一个悲观的替代策略中,写操作与之前一样进行,但是对于读操作,垫片尝试从ECDS读取最新值并覆盖它。这需要同步检查请求路径。
这里的取舍-我们在以前的文献中没有观察到的是在价值观的陈旧性(活跃性)和阅读操作速度之间的取舍。可以使用多种策略来调整这种权衡(例如,将同步ecd读取的数量限制为某个常量),但是,在本文中,我们关注两个极端:具有所有本地读取的bolt-on因果一致性和悲观的bolt-on因果一致性,其中,从ecd读取时,垫片同步跟踪整个依赖链。
整个算法易于理解,评估实现只需2000行Java代码。
shim模型有两个很好的特性:命运共享意味着shim不需要保持任何持久状态;并且该模型很容易扩展到因果事务。
如果填充程序崩溃,其客户端也将崩溃(第3.2节),因此丢失填充程序状态是安全的。ECDS处理所有传播,垫片不需要(也不需要)通信以确保安全或活性…。
而且,
最近的工作引入了因果只读和只读事务的概念[34,35]。一个螺栓垫片可以提供这些交易的高可用性,只需稍作修改。为了执行只读的“get transaction”,并返回一组因果一致的写操作,shim需要从本地存储区读取指定键之间的因果切分(注意,因果切分定义再次简化了操作的语义)。这很容易通过使用支持“快照”读取的本地存储来实现,它相当于快照隔离、可重复读取隔离或更强的隔离[3]。类似地,因果的只写事务可以通过事务性地将相关更新组应用到本地存储来完成。
评估是使用Yahoo!云服务基准,而Cassandra作为底层ecd。
我们使用shim实现和生产准备最终一致的数据存储来评估螺栓连接因果一致性的性能。我们发现,为多个在线服务跟踪提供明确的因果关系很容易扩展到每秒数万个操作。因果一致性的局部读取属性允许螺栓连接的因果一致性优于最终一致性,而悲观螺栓连接的因果一致性通常在最终一致性峰值的25%到50%之间-
放。
对2000点来说还不错!生成的系统在提供更强的一致性保证的同时性能更好。
主要考虑的似乎是存储额外元数据的成本:
我们发现,通常情况下,附加策略的效率取决于元数据开销。对于许多数据集,开销小于500B,但是对于emetafilter这样的数据集,开销可能超过19KB。因此,典型的元数据管理费用是便宜的,但是,对于长期的历史,因果关系的成本必须与最终用户的利益相权衡。
作者的结论是:
根据我们的经验,我们相信,数据存储的附加和分层方法可以提供一种有用的、模块化的替代方案,而不是通常单一的现有数据存储基础设施。在这项工作中,我们采取了一种相当严格的方法,着眼于互操作性和广泛的适用性;覆盖历史和解决方案所需的元数据开销的关键挑战是这一决定的产物。然而,一组限制较少的假设(在未来的数据存储系统中是合理的)提供了更和谐的跨层协调的可能性。特别是,我们认为,重新审视数据存储接口及其与更高层数据管理功能的交互的机会特别成熟。

若有收获,就点个赞吧
0 人点赞
