学习型索引结构的案例 Kraska et al., arXiv Dec. 2017
昨天,我们研究了使用学习模型代替手工编码算法来选择系统软件组件的大思想,重点放在分析数据库中的索引。今天我们将更深入地研究使用这种方法构建的范围、点和存在性索引。即使使用基于CPU的实现,结果也令人印象深刻。例如,对于整数数据集:
可以看出,学习型索引在几乎所有配置中都占据了B-树索引的主导地位,它的速度高达3倍,并且小了一个数量级。
当我们昨天离开时,朴素(CDF)学习指数慢了2-3倍!让我们看看是什么改变了,得到了这些结果。
学习范围索引
回想一下,一个学习过的CDF很难精确地建模数据分布的精细结构。不过,仅仅替换B树的前两层,即使使用简单的模型也更容易实现。一旦我们处理数据集中的一小部分,学习它的精细结构就变得容易得多。因此,总体解决方案是在递归回归模型中分层模型:
…我们建立了一个模型层次结构,在每个阶段,模型都将键作为输入,并基于它选择另一个模型,直到最后阶段预测位置。
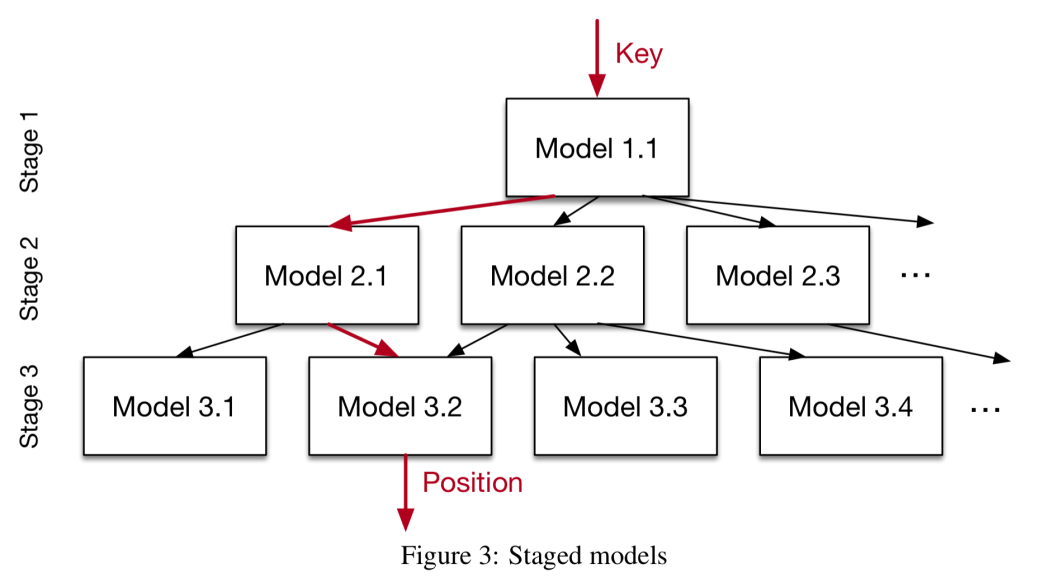
不过,递归模型不是树——同一阶段的不同模型可能映射到下一阶段的相同模型。模型也不一定一致地划分Key空间。更像是“挑选对某些关键点有更深入了解的专家”
请注意,我们还可以在不同阶段使用不同的模型:
例如,在顶层,一个小的ReLU神经网络可能是最好的选择,因为它们通常能够学习大量复杂的数据分布,而在底层的模型可能是数千个简单的线性回归模型,因为它们在空间和执行时间上都很便宜。
整个索引(所有阶段)可以表示为TPU/GPU的稀疏矩阵乘法,并且可以端到端地进行训练(参见本文第3.3节中的算法1)。
这个递归模型索引(RMI)的输出是一个页面。在不知道数据分布的情况下,传统上二进制搜索或扫描(对于较小的页面大小)被证明是最快的策略。
同样,学习的索引在这里也有一个优势:模型实际上预测了键的位置,这可能更接近于记录的实际位置,而最小和最大错误可能更大。
在此基础上,作者提出了一种新的有偏四元搜索策略。在四元搜索中,不必像二元搜索那样选择一个新的中间点进行测试,而是选择三个新的测试点(从而将数据集分成四分之一,而不是两半)。四元搜索的三个初始中间点设置为pos-\sigma、pos和pos+\sigma,其中pos是预测位置。“那就是我们猜测,我们的大多数预测都是准确的,我们的注意力首先集中在位置估计上,然后继续传统的四元搜索。”
为了进行评估,在3个真实数据集(最多200行)上创建了4个二级索引,并创建了一个用于执行重尾分布的合成数据集。对于所有的数据集,使用不同的页面大小,在非常有竞争力的B树实现和具有不同第二阶段大小(10K、50K、100K和200K)的两阶段RMI模型之间进行比较。训练一个完整的RMI模型只需要几秒钟。
让我们先看看map、weblog和synthetic log normal数据集的结果,因为它们都使用整数键。
对于地图数据集,将为大约200米的地图要素(道路、博物馆、咖啡馆等)的经度创建索引。下面是B-Tree和RMI模型的处理方式,总的查找时间被分解为模型执行时间(以查找页面)和页面内的搜索时间。与使用128页大小的B树相比,结果是标准化的。
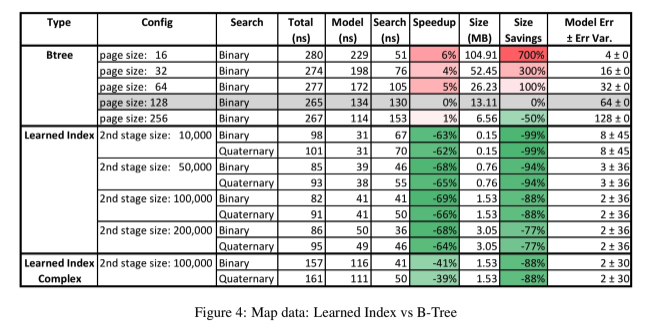
学习型索引占据了B树索引的主导地位:它比B树索引快3倍,占用的空间也大大减少。
weblog数据集包含了几年来对一个主要大学网站的每个请求,并按时间戳进行索引。对于学习模型来说,这是一个具有挑战性的数据集,但是学习索引仍然支配着B-树。
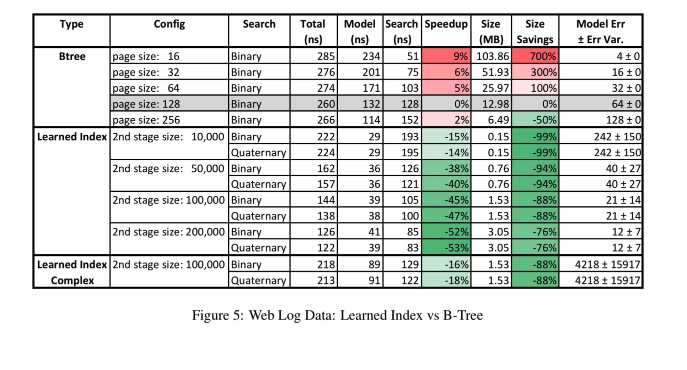
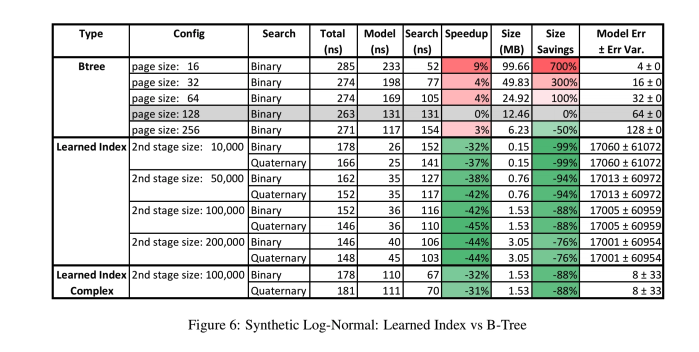
这个故事与合成的对数正态数据集相似。
web文档数据集包含10M个大型web索引的非连续文档id。这里的键是字符串,方法是将每个字符串转换为最大输入长度向量,每个字符一个元素。将来还可以使用其他更复杂的编码,利用RNNs等工具来学习字符之间的交互。在这组结果中包含了一个混合模型,它用一个局部B-树替换错误超过阈值的第二阶段模型。
在这里,学习型索引并没有那么明显地好(尽管它总是能节省很多空间)。使用矢量输入的模型执行成本更高——使用GPU/TPU而不是CPU可以解决这个问题。
即使没有任何意义上的修改,当前的设计对于替换数据仓库中使用的索引结构(可能每天只更新一次)或BigTable(其中B树是作为SStable合并过程的一部分批量创建的)已经很有用。
学习的模型也有可能对某些类型的更新工作负载具有优势,特别是在更新遵循现有数据分布的情况下。如果分布确实发生了变化,一种选择是构建插入的增量索引,并定期将其与主索引合并,包括可能的重新培训。
学习点索引
**
散列映射的关键挑战是防止太多不同的键映射到映射内的同一位置(冲突)。例如,100米记录和100米槽,大约有33%的机会发生冲突。此时,我们必须使用第二种策略(例如扫描链接列表)来搜索槽。
因此,大多数解决方案通常会分配比记录多得多的内存(即插槽)来存储……例如,据报道,Google的密集hashmap的典型开销约为内存的78%。
但是,如果我们能够学习一个模型,该模型将每个键唯一地映射到数组中的一个唯一位置,我们就可以避免冲突。如果有足够的可用内存,就很难比传统hashmaps的性能更好。但是,在较高的入住率(例如,不到20%的管理费用)下,性能开始显著下降,学习的模型可能会做得更好。
令人惊讶的是,学习密钥分布的CDF是学习更好的散列函数的一种潜在方法……我们可以通过散列映射的目标大小M和我们h(K)=F(K)*M来缩放CDF,其中密钥K是我们的散列函数。如果模型F完美地学习了CDF,则不存在冲突。
此策略可用于替换任何现有哈希映射实现中的哈希函数。下面是一个评估,比较两阶段RMI模型和第二阶段的100K模型,以及使用3位移位、3个异或和2个乘法的快速散列函数。对于每一个数据集,这两种方法都是通过映射中可用的时隙的数量进行评估的,这些时隙的数量能够适应75%到125%的数据。
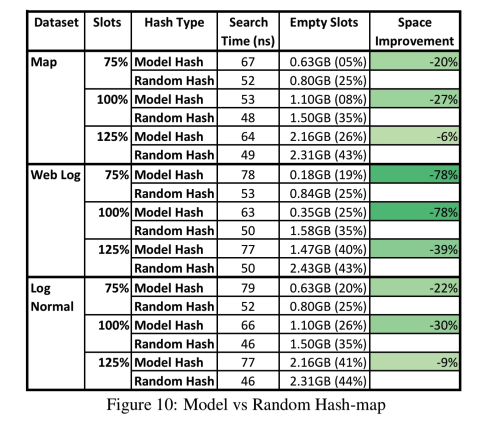
具有模型散列函数的索引总体上具有相似的性能,同时更好地利用了内存。
学习存在性指标
Bloom过滤器用于测试元素是否是集合的成员,通常用于确定例如密钥是否存在于冷库中。Bloom filters保证没有假阴性(如果Bloom filter说密钥不在那里,那么它就不在那里),但是确实有可能出现假阳性。Bloom过滤器具有很高的空间效率,但仍然可以占用相当多的内存。对于目标误报率为0.1%的100M记录,我们需要比记录多大约14倍的比特。再一次…
…如果有某种结构来确定集合内部与外部的关系,这是可以学习的,那么就有可能构造更有效的表示。
从ML的角度来看,我们可以将Bloom过滤器看作一个分类器,它输出给定密钥在数据库中的概率。我们可以设置考虑密钥在集合中的概率阈值tau,以便可以实现任何给定的目标误报率。但与Bloom过滤器不同,我们不能保证没有假阴性。这个问题的解决方案是简洁的:取学习函数f产生的一组假阴性,并仅为这个键子集创建一个Bloom过滤器。现在在查找时,如果f表示密钥存在的概率大于tau,我们可以肯定地回答。如果概率小于此阈值,则在返回最终决策之前,向假阴性Bloom过滤器添加第二个检查。
该方法通过使用170万个唯一的黑名单钓鱼网址数据集和一组无效网址进行测试。训练一个字符级RNN(GRU)作为分类器来预测URL属于哪个集合。与普通的Bloom过滤器相比,在相同的假阳性率(1%)下,模型+溢出Bloom过滤器的大小减少了47%。在0.01%时,空间缩减率为28%。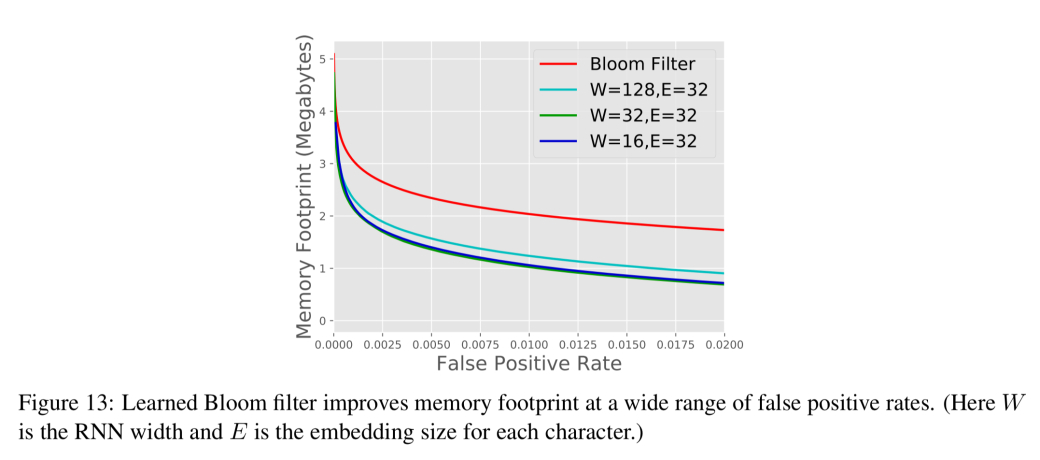
模型越精确,Bloom过滤器的尺寸就越节省。没有什么能阻止模型使用其他特性来提高准确性,例如WHOIS数据或IP信息。
总结
……我们已经证明,机器学习模型比最先进的数据库索引具有显著的优势,我们相信这是未来研究的一个富有成效的方向。

若有收获,就点个赞吧
0 人点赞
