原文地址:Abstracting Definitional Interpreters: Functional Pearl
摘要
在这个“函数式语言的珍珠”中,我们研究定义解释器作为高阶编程语言抽象解释的基础的使用。事实证明,定义解释器,特别是那些以一元形式书写的解释器,可以为各种各样的收集语义、抽象解释、符号执行及其混合提供良好的基础。
但这个故事的真正意义在于重演了雷诺德里程碑式的论文《高阶编程语言的定义解释器》(Definitional Interpreters for Higher Order Programming Languages)中的一个观点,他观察到定义解释器使定义语言能够继承定义语言的属性。对于定义性抽象解释器,我们也证明了这一点。值得注意的是,我们发现抽象定义解释器可以继承所谓的“下推控制流”属性,其中函数调用和返回在抽象语义中精确匹配,只需借助定义语言的函数调用机制。
在过去的十年中,第一种实现高阶语言这一特性的方法出现了,并成为许多论文的主题。这些方法从状态机语义出发,统一地涉及到恢复下推控制流精度的重要技术工程。相反,从定义解释器开始,下推控制流属性是元语言固有的,不需要进一步的技术机制来实现。
1简介
抽象解释器旨在可靠有效地计算与具体解释器的过度近似。对于高阶语言,这些具体的口译员往往被表述为状态机(例如Jagannathan和Weeks(1995);Jagannathan等人。(1998年);赖特和贾甘纳森(1998年);迈特和索沃斯(2006a);米德加德和詹森(2008年);米德加德和詹森(2009年);迈特和范霍恩(2011年);谢尔盖等人。(2013年)。这种选择有几个原因:它们使用在类似的简单数据结构上定义的简单传递函数进行操作,它们使计算状态的所有方面都显式化,并且在可到达状态集中计算不动点是简单的。基于状态机的方法的本质是由Van Horn和May在他们的“抽象机器”(AAM)技术中提炼出来的,该技术为从CEK或Krivine等标准抽象机器(Van Horn和May 2010)构建抽象解释器提供了一种系统方法。想为自己的语言构建抽象解释器和程序分析工具的语言设计者,现在至少原则上可以先构建一个状态机解释器,然后转动曲柄来构造近似的抽象解释器。
从过去的工作中产生的一个自然问题是:是否可以为编写的解释器执行类似于AAM的系统抽象技术,而不是作为状态机,而是作为高级定义解释器(即递归的、组合的求值器)?这个函数性语言的珍珠回答是肯定的,并证明了这样做的一些有趣的结果。
从过去的工作中产生的一个自然问题是:是否可以为编写的解释器执行类似于AAM的系统抽象技术,而不是作为状态机,而是作为高级定义解释器(即递归的、组合的求值器)?这个“函数语言的珍珠”回答是肯定的,并证明了这样做的一些有趣的结果。
首先,我们证明了AAM方法只需对原方法稍加修改就可以应用于定义性口译员。这个新设置中的主要技术挑战是以一种既合理又总是终止的方式处理解释器固定点—固定点的原始抽象将是合理的,但并不总是终止的,而固定点缓存的原始使用将保证终止,但本质上是不合理的。我们通过一个缓存定点查找算法来解决这个技术难题,该算法既合理又保证在提取任意定义的解释器时终止。
第二,我们认为抽象定义解释视角在两个方面是卓有成效的。第一个是毫不奇怪的:高级抽象解释器在可重用性和可扩展性方面提供了其具体对应者通常的有益特性。特别地,我们证明了利用monad变形金刚可以构造抽象的解释器,并取得了良好的效果。第二个方面更令人惊讶,我们认为它的观察是这颗珍珠的主要贡献。
定义解释器,与抽象机器相比,可以保留计算的隐式方面,依赖定义语言的语义来定义定义语言的语义,这是Reynolds(1972)在其里程碑式的论文《高阶编程语言的定义解释器》中所作的观察。例如,Reynolds表明可以编写一个定义解释器,以便在按值调用元语言时定义按值调用语言,并在按名称调用元语言时定义按名称调用语言。受雷诺兹的启发,我们证明抽象定义的解释者同样可以继承元语言的性质。特别是,我们构造了一个抽象的定义解释器,其中没有连续性或调用堆栈的显式表示。相反,解释器是以简单的递归方式编写的,调用堆栈由metalangauge隐式处理。从这个结构中产生的是一个完全抽象的评估函数,它完全近似于给定程序的所有可能的具体执行。但值得注意的是,由于抽象求值器依赖于元语言隐式地管理调用堆栈,因此很容易观察到它在调用和返回的匹配中没有引入近似值,因此实现了“下推”分析(Earl等人。2010年;Vardoulakis and Shivers 2011),所有这些都不需要任何明确的机制。
大纲
在本珍珠的其余部分,我们提出了一个调整的AAM方法,以设置递归定义,组成评价函数,即定义口译员。我们首先简要回顾AAM配方中的基本成分(从机器到成分评估器),然后定义我们的定义解释程序(定义解释程序)。解释器在很大程度上是标准的,但它是以一元和可扩展的风格编写的,以便对我们研究的各种形式的语义可重用。AAM技术通过存储分配绑定和合理地定义堆,以一种简单明了的方式应用。但是当天真地运行时,解释器并不总是终止。为了解决这个问题,我们引入了一个缓存策略和一个简单的定点计算来确保解释器终止(缓存和查找定点)。正是在这一点上,我们观察到我们构建的解释器享有“pushdown”属性,它继承自解释器的定义语言,不需要显式机制(pushdown a la Reynolds)。
在确定了主要结果之后,我们接着在简短的小插曲中探索一些变化,展示了我们定义抽象解释器方法的灵活性。首先,我们考虑广泛使用的所谓“商店扩展”技术,它通过对抽象存储进行全局建模而不是局部建模(扩展存储),以精确性换取效率。多亏了解释器的一元公式,这是通过简单地重新排序一元转换器堆栈来实现的。我们还探索了一些可选的抽象,显示出由于可扩展的结构,很容易为抽象解释器试验可选组件。特别是,我们定义了对原语操作的另一种解释,这种解释在存储中的连接强制引入近似(另一种抽象)之前保持完全精确。作为另一个变体,我们将探讨作为解释器的另一个实例(符号执行)来计算符号执行的形式。最后,我们将展示如何合并所谓的“抽象垃圾收集”(abstract garbage collection),这是一种通过清除无法到达的存储位置来提高抽象解释精度的著名技术,从而避免将来的连接导致不精确(垃圾收集)。最后一个变化非常重要,因为它表明,即使我们没有堆栈的显式表示,也可以计算通常需要此类显式表示的分析,以便计算垃圾收集的根集。
最后,我们将我们的工作放在高阶抽象解释(相关工作)文献的背景下,并得出一些结论(结论)。
风格
为了尽可能具体地表达本文的思想,我们提出了实现定义抽象解释器及其所有变体的代码。作为元语言,我们使用Racket的一个应用子集(Flatt和PLT 2010),一种Scheme方言。这种选择在很大程度上是无关紧要的:任何函数式语言都可以。然而,为了辅助可扩展性,我们使用Racket的单元系统(Flatt和Felleisen 1998)来编写可以链接在一起的程序组件。
所有的代码在这个珍珠运行;这个文件是一个识字球拍程序。我们还实现了一个小型DSL,用于轻松地编写和实验这些解释器。以下网址提供了源代码、文档和简要教程:
https://github.com/plum-umd/abstracting-definitional-interpreters
2从机器到成分评估器
近年来,以抽象机器一阶转换系统为语义基础的高阶语言抽象翻译系统的构建已经取得了很大的进展。所谓的抽象机器(AAM)抽象解释方法(Van Horn和2010年5月)是将机器语义转换为易于抽象的形式的诀窍。转化包括以下成分:
在存储里分配连续性;
在存储中分配变量绑定;
使用将地址映射到值集的存储;
将存储更新解释为联接;以及
将存储解除引用解释为不确定的选择。
由于原始机器和派生机器在锁步对应中操作,这些转换是语义保持的。以这种方式转换语义后,可计算的抽象解释器通过以下方式实现:
将存储分配限定为有限地址集;以及将基值扩展到某个抽象域。
在执行这些转换之后,生成的抽象解释器的可靠性和可计算性就不言而喻了,并且很容易得到证明。
AAM方法已经被应用于多种语言和应用程序中,考虑到该方法的成功,人们自然会怀疑它使用低级机器的必要性。对于语义的更高层次的表达,比如在表达式的语法上递归定义的组合求值函数,是否可以采用类似的方法,这一点还不清楚。
本文表明AAM方法的本质可以应用于高层语义基础。我们证明,用一元风格编写的构图评价器可以表达与AAM相似的抽象,并且与AAM一样,设计保持了系统性。此外,我们还表明,高级语义提供了许多机器模型无法获得的好处。
关于可扩展解释器的工具和技术有大量的工作(Jaskelioff 2009;Kiselyov 2012;Liang等人。所有这些都适用于高级语义。通过将高阶语言的抽象解释放在高层次语义的基础上,我们可以将这些结果应用到可扩展抽象解释程序的构建中。
3定义转义
我们首先为一种小型但有代表性的高阶函数式语言构造一个定义解释程序。语言的抽象语法如下所示;它包括变量、数字、对数字的二进制操作、条件、递归表达式、函数和应用程序。

该语言的解释器如图1所示。乍一看,它有许多传统的方面:它是由表达式语法上的结构递归组合定义的;它定义了按值调用函数语言,它将函数值表示为一个闭包数据结构,将lambda项与求值环境配对;它是单点结构的,使用单点操作与环境交互并存储;它依赖于辅助函数δ来解释原始操作。

有几个表面的方面值得注意:环境ρ是有限映射,语法(ρx)表示ρ(x),而(ρx a)表示ρ[x↦a]。递归表达式(rec f e)将f绑定到在e本身范围内对e求值的结果;如果求值e₀需要对f求值,则这是一个运行时错误。do符号只是bind的简写,与通常一样:

最后,有两个非常规方面值得注意。
首先,解释器是以一种开放的递归方式编写的;求值器不递归地调用自己,而是将一个隐藏正在定义的函数ev的名称的函数ev作为参数,并且调用ev(参数)而不是自递归。这是无递归绑定的设置中递归函数的标准编码。这取决于一个外部函数,比如Y-组合子,来关闭递归循环。这种开放的递归形式非常重要,因为它允许截取递归调用来执行解释器的“深层”检测。
第二,代码显然不完整。有许多自由变量,以斜体字排版,实现以下功能:
解释器的底层monad:return和bind;
原语的一种解释:δ和零?;
环境操作:请求env检索环境,本地env安装环境;
存储操作:用于更新存储和查找解引用位置的ext;以及
分配新存储位置的操作。
接下来,我们经常使用涉及自由变量的定义,并将这些定义的集合称为组件。我们假设组件可以命名(在本例中,我们命名了组件ev@,由右上角的框表示)并链接在一起以消除自由变量。我们在实现中使用Racket units(Flatt和Felleisen 1998)来建模组件。
接下来,我们检查一组完成定义解释器的组件,如图2所示。第一个组件monad@使用宏define monad,它基于monad transformer堆栈生成一组绑定。我们使用一个失败的monad来建模除以零的错误,使用一个状态monad来建模存储,使用一个读卡器monad来建模环境。define monad表单生成用于return、bind、ask env、local env、get store和update store的绑定;它们的定义是标准的(Liang et al。1995年)。
我们还定义了一元计算的运行,从空环境开始并存储:

虽然define monad表单隐藏了一些细节,但该组件可能已被显式写出。例如,返回和绑定可以定义为:
到目前为止,我们使用monad transformers仅仅是为了方便,但是monad抽象对于以后轻松地导出新的分析来说将是必不可少的。
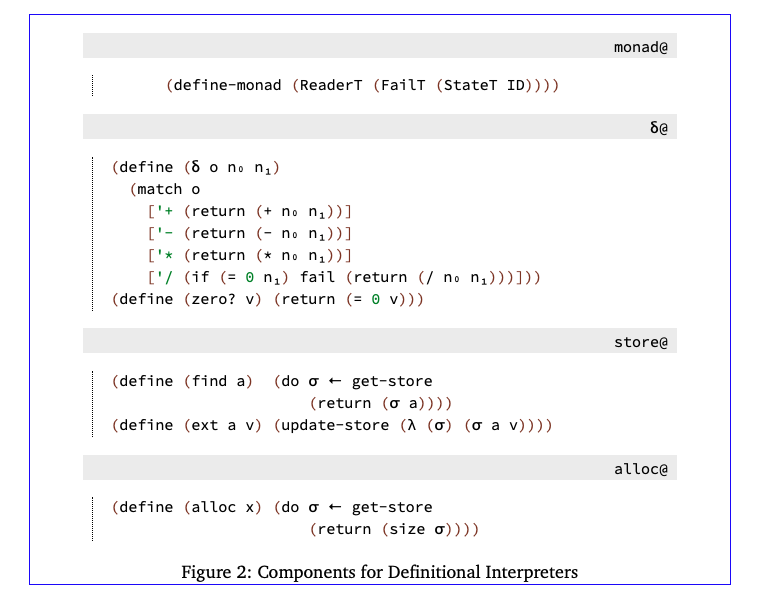
δ@component定义了原语的解释,它是根据底层monad给出的。alloc@component提供alloc,alloc获取存储并使用其大小返回一个新地址,假设不变(∈aσ)⇔(<a(sizeσ))。alloc函数接受一个参数,它是正在分配其绑定的变量的名称。目前,它被忽略,但在抽象闭包(抽象闭包)时会变得相关。store@component定义了find和ext,用于查找和扩展存储中的值。
唯一剩下的拼图部分是一个定点组合器和解释器的主要入口点,它们很容易定义:
利用Racket的语言作为库的特色(Tobin Hochstadt等人。2011),我们构建了与这个解释器交互的REPLs。下面的几个评估示例演示了使用简洁具体语法的解释器。下面是空环境上与空存储配对的闭包,以及非空环境上与非空存储配对的闭包:
下面是对非空环境和存储的闭包:
源语作业按照预期的方式工作:
除零错误将导致作业失败:
因为我们的monad堆栈将FailT放在StateT之上,所以答案包括错误点的(空)存储。如果我们将monad@更改为使用(ReaderT(StateT(FailT ID)),则失败将不包括存储:
在这一点上,我们定义了一个简单的定义解释器,尽管涉及一元操作和开放递归的可扩展组件将允许我们实例化同一个解释器,以实现各种有用的抽象解释。
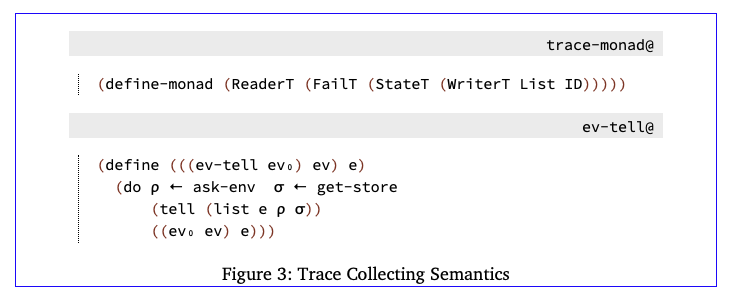
3.1收集变更
抽象解释的形式化发展通常从所谓的“非标准集合语义”开始,集合语义的一种常见形式是跟踪语义,它收集解释器所达到的状态流。图3显示了跟踪解释器的monad堆栈和求值器的“mix-in”。monad堆栈添加WriterT List,它提供了一个新的操作tell,用于将项列表写入到达的状态流。ev tell函数是底层ev₀unfixed求值器的包装器,它通过告诉求值器的当前状态(当前表达式、环境和存储)在每个递归调用之间插入自己。最顶层的评价函数是:

现在,当一个表达式被求值时,我们得到一个答案和求值器看到的所有状态的列表,按照它们被看到的顺序。例如:
| > (* (+ 3 4) 9) | |
|---|---|
| ‘((63 . ()) | |
| —- | |
| ((* (+ 3 4) 9) () ()) | |
| ((+ 3 4) () ()) | |
| (3 () ()) | |
| (4 () ()) | |
| (9 () ())) |
|
如果我们将List与monad堆栈中的Set交换,我们将获得一个可达状态语义(reachable state semantics),这是收集语义的另一种常见形式,它会丢失状态的顺序和重复。
作为另一个收集语义变体,我们展示了如何收集程序中的死代码。在这里,我们使用一个monad堆栈,它有一个附加的状态组件(带有名为put dead和get dead的操作),用于存储dead表达式集。最初,它将包含程序的所有子表达式。当解释器对表达式求值时,它会将它们从死集中移除。
图4定义了不可达代码收集语义的monad堆栈和ev dead@component,这是ev₀evaluator在循环之前移除给定子表达式的另一个混入。由于计算不可达代码需要一个外部包装器,它将死代码的初始集合设置为程序中的所有子表达式,因此我们定义eval dead@,它使用一个封闭的求值器,即某种形式(fix ev)。将这些部分放在一起,定义不可达代码收集语义:
(define(eval e)(mrun((eval dead(fix(ev dead ev)))e)))
使用不可达代码解释器运行程序会生成一个答案和一组在程序运行期间未计算的表达式:
| > (if0 0 1 2) |
|---|
| (cons ‘(1 . ()) (set 2)) |
| > (λ (x) x) |
| (cons ‘(((λ (x) x) . ()) . ()) (set ‘x)) |
| > (if0 (/ 1 0) 2 3) |
| (cons ‘(failure . ()) (set 3 2)) |
我们的设置不仅使表达具体的解释器变得容易,而且还使这些有用的收集语义的形式变得容易。
3.2对基本值的抽象
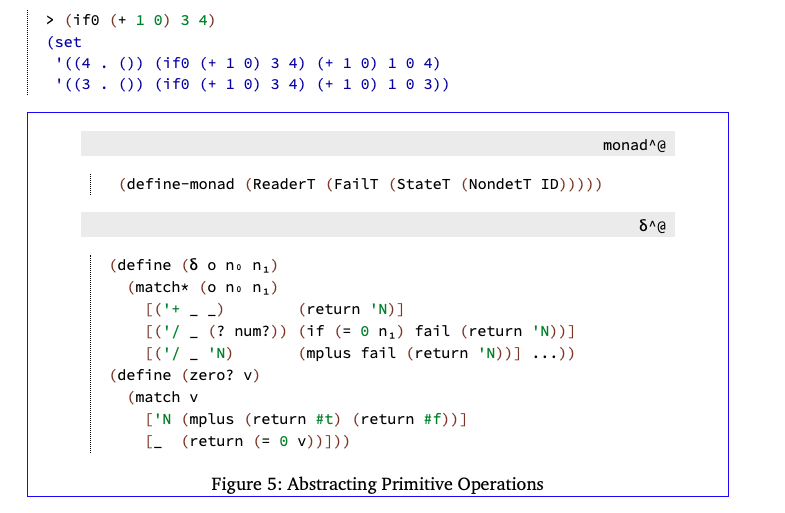
我们的解释器在被认为是一种分析之前必须是可判定的,而实现可判定性的第一步是将语言的基本类型抽象成有限的东西。为此,我们引入了一个新的抽象数,写为N,表示所有数字的集合。抽象数是由原语操作的另一种解释引入的,如图5所示,它在所有情况下都只产生’N。
在抽象“/”时必须小心。如果分母是抽象数“N”,则程序可能因被零除而失败,因为0包含在对“N”的解释中。因此,当分母是“N”时,有两个可能的答案:“N”和“failure”。这两个答案都是通过在monad堆栈中引入非决定论NondetT而返回的。添加非确定性提供了用于组合多个答案的mplus操作。非决定论也用于零?,在N上返回true和false。
通过将δ^@和具有非确定性的monad堆栈连接起来,我们得到了一个求值器,它产生一组结果:
| > (* (+ 3 4) 9) |
|---|
| ‘((N . ())) |
| > (/ 5 (+ 1 2)) |
| ‘((failure . ()) (N . ())) |
| > (if0 (+ 1 0) 3 4) |
| ‘((4 . ()) (3 . ())) |
如果我们将δ^@与跟踪单子堆栈加上非确定性联系起来:
很明显,解释器将只看到有限的一组数字(包括’N),因为δ的参数将只包括出现在程序文本中的数字或以前使用δ的结果(仅为’N)。但是,解释器停止所有输入肯定不是真的。首先,仍然可以生成无限个闭包。其次,解释器无法检测何时看到循环。要使一个终止的抽象解释器同时处理这两个问题。接下来我们看抽象闭包。
3.3抽象闭包
闭包由一个lambda项和一个环境(从变量到地址的有限映射)组成。由于lambda项和变量集受程序文本的限制,通过对地址集进行限定就可以对闭包进行限定。遵循AAM方法,我们通过修改分配函数来生成从有限集提取的元素。为了保持语义的可靠性,我们修改了存储以将地址映射到值集,将模型存储更新为联接,将模型取消引用作为非确定性选择。
任何产生有限集合的分配函数的抽象都可以(没有办法做出不合理的选择),但是抽象的选择将决定结果分析的精度。一个简单的选择是使用变量名作为其地址来分配变量。这给出了一个单变量或类似于0CFA的抽象。

图6显示了实现单态分配的组件alloc^@和实现find和ext的组件store nd@,后者与存储映射到值集交互。for/monad+表单便于将一组计算与mplu结合使用,因此find返回给定地址处存储区中的所有值。ext函数在已分配地址时连接,否则它将地址映射到单例集。通过将这些组件与以前的同一个monad堆栈链接,我们获得了一个解释器,每当变量绑定到多个值时,它就会失去精度。例如,此程序将x绑定到1和2,并在运行时生成两个答案:
我们的抽象解释器现在有一个真正有限的域;下一步是在状态空间中检测循环以实现终止。
4缓存和查找固定点
此时,通过将monad^@、δ^@、alloc^@和store nd@组件链接在一起获得的解释器将只访问给定程序的有限数量的配置。构型(ς)由表达式(e)、环境(ρ)和存储(σ)组成。这种配置是有限的,因为:表达式在给定的程序中是有限的;环境是从变量(在程序中也是有限的)到地址的映射;地址是有限的,这要归功于alloc^;存储将地址映射到值集;基值通过δ^抽象到有限集;闭包由表达式和环境组成,它们都是有限的。
尽管解释器只能看到有限的输入,但它并不知道。一个简单的循环将导致解释器发散:
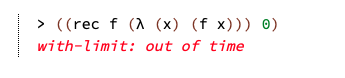
为了解决这个问题,我们引入了一个cache($in)作为算法的输入,它从配置(ς)映射到值集和存储对(v×σ)。当第二次到达配置时,不是重新计算表达式并进入无限循环,而是从充当oracle的$in中查找结果。缓存必须以高效的方式使用,这一点很重要:只有先取得一些进展,才能安全地用作oracle。
然后,求值的结果存储在输出缓存($out)中,在求值结束后,输出缓存比输入缓存($in)更“定义”,再次遵循共归纳参数。将oracle$转换为in并输出更明确的oracle$racket[out]的评估器的最小固定点$+,是程序的声音近似值,因为它过度近似于未固定评估器的所有有限展开。
共归纳缓存算法如图7所示,还有monad transformer stack monad cache@它有两个新组件:ReaderT用于输入缓存$in,StateT+用于输出缓存$out。我们在输出缓存中使用StateT+而不是WriterT monad transformer,因此它可以双重跟踪所看到的状态集。in StateT+表示多个不确定分支的缓存将自动合并,生成一组结果和一个缓存,而不是一组与单个缓存配对的结果。

在算法中,当第一次遇到配置ς时,我们在输出缓存映射ςto($Inς)中放置一个条目,这是“oracle”结果。此外,每当我们计算完对配置进行求值的结果v×σ′时,我们都会将一个条目放在输出缓存映射到v×σ′中。最后,每当我们到达输出缓存中存在映射的配置ς时,我们立即使用它,使用for/monad+迭代器返回每个结果。因此,对$out的每一次“缓存命中”都处于两种可能的状态之一:1)我们已经看到了配置,结果是所需的oracle结果;或2)我们已经计算了“改进”结果(w.r.t.oracle),无需重新计算它。
为了计算evaluator ev缓存的最小固定点$+,我们从缓存的底部元素空映射开始执行标准Kleene固定点迭代,如图8所示。

该算法从初始环境和存储中迭代给定程序e上的缓存求值器eval。一元最小定点查找器mlfp使用空缓存和改进的oracle$计算程序。缓存求值在其求值时填充缓存,包括在已知先前迭代中的配置时来自oracle的结果,并返回缓存以在下一次迭代中用作改进的oracle。在找到oracle的最小不动点后,提取并返回初始配置的最终值和存储区。
最小不动点的终止由求值器的单调性(它总是返回一个“改进的”oracle)和缓存的有限域来证明,缓存的有限域将抽象配置映射到值对和存储,所有这些都是有限的。
有了这些部件,我们就可以构建一个完整的解释程序:
(define(eval e)(mrun((fix cache(fix(ev cache ev)))e)))
当与δ^和alloc ^连接时,这个抽象解释器是健全的,可计算的,如以下示例所示:
形式的健全与终结
在这颗明珠中,我们关注的是代码及其直观性,而不是严格地建立抽象解释器的通常形式属性,但这只是一个表示问题:解释器确实被证明是可靠和可计算的。我们已经在本文附带的补充材料中形式化了这个共归纳缓存算法,在这里我们证明了它总是终止的,并且它计算了一个声音过近似的具体评估。这里,我们对我们的元理论方法做一个简短的总结。
在形式化该缓存算法的可靠性时,我们将标准的大步求值语义扩展为大步可达性语义,该语义描述了在单个表达式求值与其最终结果之间看到的所有中间配置。这两个概念的评估,其中涉及表达式充分评估的结果,和可达性的特点,中间配置状态始终不同的形式主义。
在对具体的评价指定了评价和可达性之后,我们开发了一个集合语义,它对任何抽象解释器都给出了精确的描述,并开发了一个抽象语义,它部分地指定了一个声音的、过近似算法w.r.t.的集合语义。
最后一步是为抽象评估关系计算一个oracle,它将各个配置映射到它们评估的值的抽象。为了构造这个缓存,我们相互计算求值关系和可达性关系的最小不动点:基于所求值的内容,发现可到达的新内容,并基于可到达的内容,发现求值的新结果。本节中开发的缓存算法是解决相互不动点的一种略为有效的策略,它通过深入探索可达性关系(直到两次看到相同的配置)而不是仅仅应用一个推理规则。
5下推 à la Reynolds
将基值和闭包的有限抽象与基于终止保证cache的定点算法相结合,得到了一个终止抽象解释器。但是我们得到了什么样的抽象解释呢?我们遵循了AAM的基本配方,但它适应于成分评估器,而不是抽象的机器。但是,我们确实跳过了AAM方法中的一个关键步骤:我们从不存储分配的连续性。事实上,根本没有延续!
传统的语义抽象机公式将对象级堆栈显式地建模为归纳定义的数据结构。因为堆栈可能是任意大的,所以它们必须像基值和闭包一样被定义,并且像闭包一样,AAM的诀窍是将它们穿过存储区,而存储区本身必须是有限的。但在本文的定义解释器方法中,栈的模型是隐式的,只是从元语言中继承过来的。
但这里有一件值得注意的事情:由于堆栈是从元语言继承来的,所以抽象解释器继承了元语言的“调用返回匹配”,也就是说在控制堆栈的分析中不存在精度损失。这是一个性质,通常需要付出相当大的努力和工程在公式的高阶流动分析,模型堆栈显式。所谓的高阶“下推”分析一直是多个出版物和两篇论文的主题(Earl 2014;Earl et al。2010年;Earl等人。2012年;Girlay等人。2016年;Johnson等人。2014年;Johnson and Van Horn 2014年;Van Horn and May 2012年;Vardoulakis 2012年;Vardoulakis and Shivers 2011年)。然而,当以定义解释器的形式表示时,pushdown属性不需要任何机制,只是从元语言继承而来。
Reynolds在他著名的论文《高阶编程语言的定义解释器》(Reynolds 1972)中首次发现,当编程语言的语义作为定义解释器呈现时,定义语言可以继承定义元语言的语义属性。我们现在已经证明,这个观察也可以扩展到抽象解释,即在下推性质的重要情况下。
在本文的剩余部分中,我们将探讨到目前为止我们所建立的基本下推抽象解释器的一些自然扩展和变体。
6拓展存储
在本节中,我们将展示如何恢复众所周知的存储扩展技术,并在此过程中演示如何轻松地构造现有的抽象设计选择。
到目前为止,我们构造的抽象解释器使用的是每程序状态的存储抽象,这种抽象非常精确,但代价高昂。对付这一成本的一个常见方法是使用一个全球“加宽”存储(2007年5月;Shivers 1991),它超过了当前设置中每个单独存储的近似值。这种改变很容易在单子设置中通过重新排序单子堆栈来实现,这是Darais等人提出的一种技术。(2015年)。而在使用monad cache@之前,我们将StateT的顺序替换为store和NondetT:
(ReaderT(FailT(NondetT(StateT+(ReaderT(StateT+ID)))))
我们得到了一个扩展存储的抽象解释器变体。因为存储的StateT出现在undeterminism下面,所以它将自动加宽。我们写StateT+是为了表示状态单元支持这种扩展。
7另一种替换抽象
在这一节中,我们演示了通过交换组件来尝试其他抽象策略是多么容易。特别是,我们研究了原始操作和存储连接的另一种抽象,这种抽象的结果在我们所知的范围内还没有在文献中进行过探索。这个例子展示了使用我们的方法快速原型化新抽象的潜力。
图9定义了两个新组件:精确-δ@和存储挤压@。第一种是对原始操作的另一种解释,即保持精度。与δ^@不同,它不引入抽象,而只是传播抽象。当两个具体数字相加时,结果将是一个具体数字,但如果其中一个数字是抽象的,则结果是抽象的。
这种对原始运算的解释显然并没有将有限抽象强加给它自己,因为具体数字的状态空间是无限的。如果精确的-δ@与存储的存储nd@实现相关联,则不保证终止。
store-crush@操作旨在通过在将多个具体值连接到存储中时执行加宽操作来处理精确的-δ@。这种抽象提供了高精度;例如,常数算术表达式是以全精度计算的:

即使是线性绑定和算术也能保持精度: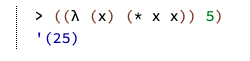
只有当绑定结构的近似值与基值接近时,我们才能看到精度的损失:
这种精确-δ@和store-crush@的结合允许终止大多数程序,但仍然不是全部。在下面的示例中,id最终应用于加宽的参数’N,这使得两个条件分支都可以访问。函数在基本情况下返回0,然后将其传播到递归调用并添加到1,从而生成具体的答案1。这将导致一个循环,当应用于1、2、3等时,中间和返回2、3、4。
为了确保终止所有程序,我们假设对基元操作的所有引用都是η-expanded的,因此存储分配也发生在基元应用程序上,从而确保在重复绑定时扩展。实际上,所有程序在使用precise-δ@、store-crush@和η-expanded原语时都会终止,这意味着我们已经实现了一个可计算且唯一精确的抽象解释器。
这里我们看到了抽象解释器的可扩展定义方法的一个优点。附加精度和加权的结合是很自然的编码。相比之下,很难想象这样的结合是如何形成的,比如说,一个基于约束的流分析。
8符号执行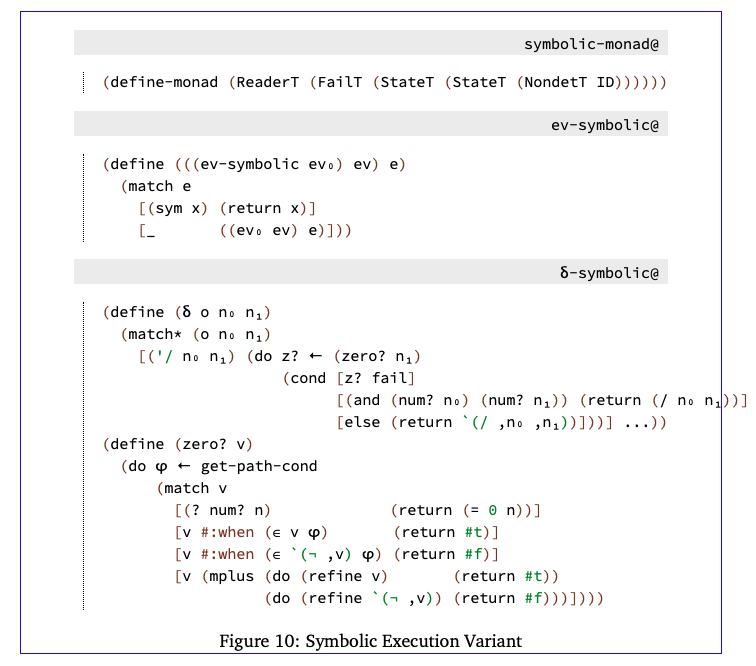

在本节中,我们将执行另一个本次更为复杂的示例,该示例演示如何实例化我们的定义抽象解释器,以获得执行声音程序验证的符号执行引擎。这有助于展示方法的范围,捕获通常被认为相当不同的分析形式。
首先,我们描述了实现符号执行器的monad堆栈和元函数(King 1976),然后我们展示了如何将前面章节中讨论的抽象应用于强制终止,将传统符号执行转换为路径敏感的验证引擎。
为了支持符号执行,语言的语法被扩展为包括符号数字:
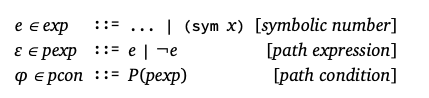
图11显示了将现有解释器转换为符号执行器所需的单元。像’/这样的原语现在也可以作为输入并返回符号值。作为标准,符号执行使用路径条件来累积在每个分支上所做的假设,从而允许消除可证明的不可行路径并构建测试用例。我们将路径条件φ表示为一组符号值或它们的否定。如果e在φ中,则假定e的值为0;如果-e在φ中,则假定e的值为非0。此集合是StateT在monad transformer堆栈中提供的另一个状态组件。一元操作获取路径条件并优化引用并更新路径条件。元函数零?工作原理与具体的对应项类似,但也使用路径条件来证明某些符号数肯定是0或非0。在不确定的情况下,0?返回两个答案,而不是使用所做的假设来优化路径条件。
在以下示例中,符号执行器认识到结果3和除以0错误不可行:

一个扩展的符号执行器可以实现零?通过向SMT解算器调用以获得关于算术的更有趣的推理,或者使用符号函数和责怪语义来扩展语言以获得更高阶的符号执行,本质上是重新创建Nguyễn等人的下推变体。(Nguyễn等人。2014年;Nguyễn和Van Horn 2015年;Tobin Hochstadt和Van Horn 2012年)。
传统的符号执行器的目标是查找错误,而不提供终止保证。但是,如果我们对这个符号执行器应用前面部分的有限抽象和缓存(抽象基值、缓存和查找固定点),我们就可以将其转换为一个健全的、路径敏感的验证引擎。
有一个问题是,对符号值的操作在状态空间中引入了一个新的无界源,因为符号值的空间不是有限的。确保终止的一个简单策略是,当一个符号值与另一个数字共享一个地址时,将其扩展到抽象数字’N,类似于从另一个抽象中保留精度的抽象。图11显示了δ和零的扩展?在N的存在下,对N和符号值的不同处理澄清了抽象值不是符号值:前者代表一组多个值,而后者代表一个单一的未知值。对抽象数N的测试并不能加强路径条件;积累关于N的任何假设是不合理的。
9垃圾收集
作为一系列示例的结尾,我们将展示如何将垃圾收集合并到定义抽象解释器中。
这个示例与存储区扩展类似,是对一种众所周知的技术的重新创建:抽象垃圾收集(may and Shivers 2006b)模拟回收无法到达的堆地址的过程,就像垃圾收集具体解释器中所做的那样。虽然垃圾回收在很大程度上可以被认为是一个不影响计算结果的实现细节(内存消耗的模实用主义问题),但在抽象语义上,它可以显著提高分析结果的精度。这是因为在抽象语义中,存储位置中介连接,因此不精确。如果一个地址可以被收集,它就避免了在没有垃圾收集的情况下遇到的稍后的连接。
在有限状态机模型中,抽象垃圾收集相当简单,并且紧跟具体的公式(may and Shivers 2006b;Van Horn and may 2010)。然而,结合下推控制流和抽象垃圾收集已经被证明是相当复杂的,并且需要新的技术(Earl等人。2012年;Johnson等人。2014年)。下推机模型本质上使用的抽象模型是下推自动机,其关键困难在于垃圾收集的通常方法是对调用堆栈进行爬网以计算可到达地址的根集(Morrisett et al。1995年)。然而,遍历堆栈并不是可以用下推自动机来表示的。定义性解释器方法与不具体化要遍历的堆栈的元语言(Racket)结合,在一定程度上加剧了这一困难!然而,正如我们所展示的,要获得一个下推的、垃圾收集的抽象解释器,这个挑战是可以克服的。这样做表明,定义抽象解释器方法也可以扩展到处理所谓的内省下推分析,这种分析需要对堆栈进行某种程度的内省(Earl等人。2012年;Johnson等人。2014年)。
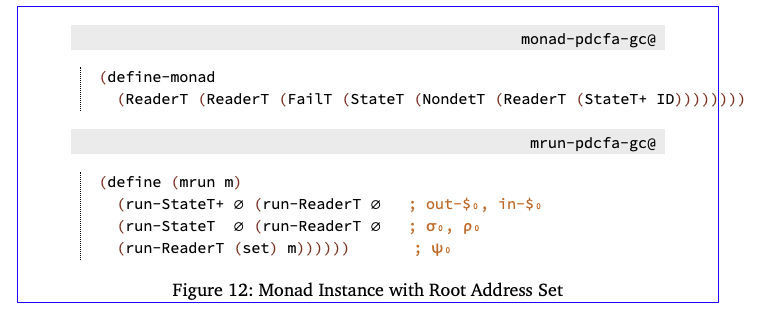
解决抽象垃圾收集问题可以归结为回答以下问题:当调用堆栈由metalanguage隐式定义时,我们如何跟踪调用堆栈上的根地址?答案相当简单:我们用一组根地址扩展monad。在计算复合表达式时,我们会为上下文计算适当的根集。实际上,我们只显式地呈现调用上下文的地址,而仍然依赖元语言来隐式地处理其余的内容。
图12定义了适当的monad实例。所有的改变都是添加了一个reader组件,它将被用来为上下文的当前根集建模。使用这个添加的组件需要更改缓存和定点计算,即我们必须将根集作为配置的一部分包括在内。与缓存和查找固定点的ev cache@组件相比,我们对前几行进行了简单的调整,以缓存根集和其余配置:

如同, for fix-cache@:
| (define ((fix-cache eval) e) |
|---|
| (do ρ ← ask-env σ ← get-store ψ ← ask-roots |
| ς ≔ (list e ρ σ ψ) |
| …)) |
我们现在可以编写一个收集垃圾的ev collect@component:它请求上下文中的当前根,将表达式求值为一个值,然后在从上下文和值的根收集所有无法访问的地址后更新存储:

这里,gc和roots-v是helper函数,它们分别执行垃圾收集和计算值中的根地址集。
剩下的就是定义一个组件,该组件将根集从复合表达式适当地传播到其组件。图13给出了ev根@component,这正是它的作用。最后,将这些片段与以下内容缝合在一起,以获得一个下推、垃圾收集定义的抽象解释器:
要观察由于GC而增加的精度,请考虑以下示例,使用pushdown a la Reynolds的(非垃圾收集)pushdown抽象解释器运行:

此示例将f绑定到标识函数,并将f应用于两个参数1和2。因为当第二个绑定到2时,x到1的第一个绑定仍在存储区中,所以结果被联接。这导致第二次应用f产生1和2。如果使用的是垃圾收集变量,则在对f的两次调用之间存在一个收集,该调用在x的第一次绑定之后,但在第二次绑定之前。此时,x是无法到达和收集的。当f再次被应用时,x在一个新的位置被绑定到2,并且整体结果反映了这个更精确的事实:

10相关工作
这项工作借鉴并再现了高阶语言抽象解释文献(Midtgaard 2012)中的许多观点。特别是,它紧跟抽象机器(Van Horn和2010年5月,2012年)的方法,从一个小步机器中派生出抽象解释器。这里的关键区别在于,我们在一元定义解释器的设置中操作,而不是在抽象机器中操作。在转到这个新设置时,我们开发了一种新的缓存机制和定点算法,但在其他方面遵循了相同的方法。值得注意的是,在定义解释器的设置中,分析的下推属性只是从元语言继承而来,而不需要显式地插入到抽象解释器中。
Jones和Nielson(1995)首先探讨了高阶语言的组合定义的抽象解释函数,该函数引入了将高阶对象语言直接解释为元语言中的术语来执行抽象解释的技术。虽然他们的工作奠定了这一思想的基础,但它并不考虑域中的固定点抽象,因此,尽管它们的抽象解释器是健全的,但它们一般不是可计算的。他们提出了一个简单的解决方案,将句法不动点的解释截断到一定的深度,但是这个解决方案并不通用,也不考虑具体领域中底的非句法出现(例如通过Y组合)。我们的工作是使用定点缓存算法为具体的表示不动点开发这样的抽象,从而为任意定义的解释器生成一般的可计算抽象。
也许最密切相关的工作是Friedman和Medhekar(2003)的一个未出版的研究生级教程,它提出了一个“抽象的”解释器,参数化了对(抽象的)语义域的解释,并以开放的递归风格编写,然后使用非标准的缓存固定点操作符关闭,以确保终止。解释器非常类似于定义解释器的定义解释器,而缓存定点运算符类似于缓存和查找定点运算符。相反,他们的解释器并不是以一元的方式编写的,而是使用变异来对缓存建模,并在抽象解释过程中传递更新。后者使人们很难对算法进行推理。虽然这两个注释都是隐含的,但它们并没有说明是否正确或终止。值得注意的是,解释器似乎没有包含闭包的抽象,而是依赖于缓存来防止在看到以前遇到的闭包时不终止。不幸的是,该策略似乎是不合理的计算,涉及教堂数字风格的迭代产生“⊥”,但不发散时,具体运行。尽管如此,本教程在精神上与目前的工作非常接近。
使用monad和monad transformers来制作可扩展(具体)的解释器是一个众所周知的想法(Liang等人。1995年;Moggi 1989年;Steele 1994年),我们已经扩展到为合成抽象翻译工作。Sergey等人以前曾探讨过在基于机器的抽象解释器公式中使用monad和monad转换器。(2013)和Darais等人。(2015年),并鼓励我们采纳这些想法。达赖还表明,某些单子变形金刚也是伽罗瓦变形金刚,即他们组成的单子,运输伽罗瓦连接。这一想法可能为以本文所述方式获得抽象解释器的合成代码和证明铺平了道路。
用于确保抽象解释器终止的缓存机制与Johnson和Van Horn(2014)使用的机制类似。它们在基于机器的解释器中使用本地和元记忆表,以确保下推抽象解释器的终止。这一机制反过来又让人想起Glück(2013)在双向非确定性下推自动机的解释程序中使用记忆。
缓存递归的、不确定的函数是函数逻辑编程界在“tabling”(Bol and Degerstedt 1993;Chen and Warren 1996;Swift and Warren 2012;Tamaki and Sato 1986)的标题下研究得很好的一个问题,并已被有效地应用于程序验证和分析(Dawson et al。1996年;Janssens和Sagonas 1998年)。与这些系统不同,我们的方法使用缓存的非确定性的浅嵌入,可以应用于通用函数语言。自Hinze推出回溯单子变形金刚(Fischer等人。2011年;Hinze 2000年;Kiselyov等人。以及最近的研究(Ploeg和Kiselyov 2014;Vandenbroucke等人。2016)指出了可以应用于我们相对幼稚的迭代策略的潜在优化和专门化。
Vardoulakis是第一个开发用于高阶流分析的下推抽象概念的人(Vardoulakis and Shivers 2011),他使用CPS模型将CFA2形式化,这在精神上类似于基于机器的模型。然而,在他的论文(Vardoulakis 2012)中,他描绘了一个被称为“大CFA2”的替代表示,这是一个很大的步骤,用于进行下推分析,其精神与本文提出的方法非常相似。一个关键的区别是,大CFA2修复了基值和闭包的一个特定的粗略抽象,例如,条件的两个分支总是被求值的。因此,它只使用抽象求值函数的一次迭代,避免了基于缓存的定点缓存和定点查找的需要。我们相信前面提到的大CFA2是合理的,但是如果底层的抽象被收紧,那么它可能需要一个更复杂的定点查找算法,就像我们开发的算法一样。
我们的下推抽象解释器公式计算了一个类似于下推流分析的许多现有变体的抽象(Earl等人。2010年;Earl等人。2012年;Girlay等人。2016年;Johnson等人。2014年;Johnson and Van Horn 2014年;Van Horn and May 2012年;Vardoulakis 2012年;Vardoulakis and Shivers 2011年)。
符号执行和抽象解释的混合在精神上类似于强权的逻辑流分析(2007b年5月),尽管是在下推的背景下,并且带有更强的否定概念;一般来说,我们的表述更像是符号执行的传统表述(King 1976)。我们的符号执行方法只处理符号值的一阶情况,这是很常见的。然而,Nguyễn关于高阶符号执行的研究(Nguyễn和Van Horn 2015)展示了如何扩展到行为符号价值。原则上,在我们的方法中,应该可以通过将Nguyễn的方法应用于成分评估器中的公式来处理这种情况,但这仍有待于执行。
现在我们已经有了抽象机器中的基础和一元口译员中的基础构成的抽象口译员,一个明显的问题是,我们能否获得它们之间的对应关系,类似于它们的具体对应关系之间的功能对应关系(Ager等人。2005年)。未来工作的一个有趣方向是尝试应用通常的工具去功能化、CPS和重新聚焦,看看我们是否可以将这些抽象的语义构件相互派生。
11结论
我们已经证明,AAM方法可以适用于以一元语体书写的定义性口译员。这样做可以捕获各种各样的语义,例如通常的具体语义、集合语义和各种抽象解释。除了从文献中重新创建现有技术(如存储扩展和抽象垃圾收集)之外,我们还可以设计新的抽象,并捕获不同形式的程序分析(如符号执行)。此外,我们的方法可以实现这些技术的新组合。
令我们惊讶的是,我们得到的定义抽象解释器实现了一种下推控制流抽象形式,其中调用和返回总是在抽象语义中正确匹配。与Reynolds的定义风格一样,求值器不涉及实现这一特性的明确机制;它只是从元语言中继承而来。
我们相信这种抽象解释的公式为高阶程序的静态分析和验证提供了一个有前途的新的基础。此外,我们相信定义性的抽象解释器方法是对一个老话题富有成效的新视角。我们不禁要问:还有什么可以从抽象解释器的元语言中获益呢?

若有收获,就点个赞吧
0 人点赞
