论文地址:灰色故障:云级系统的致命弱点 Huang等人,HotOS’17
所有这些在降级模式下停顿式地前进,尽最大努力掩盖问题,结果证明是导致云规模系统的主要可用性故障和性能异常的关键原因之一。今天HotOS的17篇文章是一篇短文,讨论了微软Azure在这种灰色失败中的经历。
云实践者经常受到灰色故障的挑战:组件故障的表现相当微妙,因此难以快速而明确地检测。灰色故障的例子有严重的性能下降、随机数据包丢失、片状I/O、内存抖动、容量压力和非致命异常。
就像所有其他类型的失败一样,规模越大,常见的灰色失败就越多。确实很常见:
我们在生产云系统方面的第一手经验表明,大多数云事件背后都是灰色故障。
灰色失效的定义
首先我们要了解敌人。灰色失败的轶事已经知道很多年了,但是这个词仍然缺乏一个精确的定义。
我们认为建模和定义灰色失效是解决该问题的先决条件。
作者提出的模型是对Azure云服务中真实事件的广泛研究的结果。这都是一个视角问题。
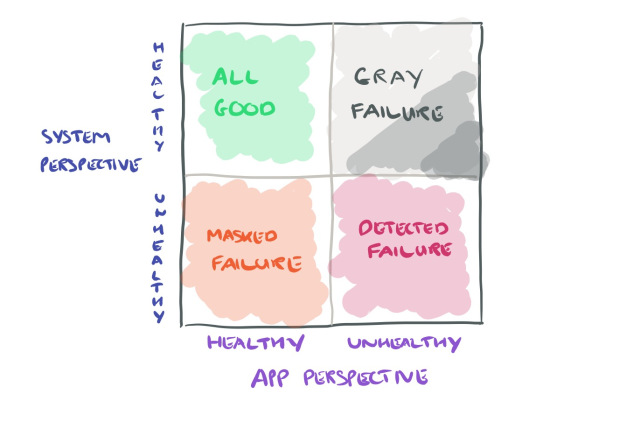
假设某个系统被故障检测器(上图中的观察者)监控。如果观察者检测到故障,反应堆就会采取行动(例如,重启部件)。同时,还有各种各样的客户端(上图中的应用程序)在使用该系统。通过与之交互,这些应用程序可以自己观察系统的运行状况(响应速度慢、报告错误等)。云系统可以同时被许多不同类型的应用程序使用,每种应用程序都有自己对系统健康状况的看法。
我们将灰色失效定义为微分可观测性的一种形式。更准确地说,当至少一个应用程序观察到系统不健康,而观察者观察到系统健康时,系统被定义为经历灰色故障。
考虑到系统及其客户端应用程序,我们可以绘制以下灰色象限:
这里同时还有一个灰色循环的定义,许多系统都会遵循这个循环:
……最初,系统会经历一些小故障(潜在故障),这些故障往往会被抑制。逐渐地,系统过渡到降级模式(灰色故障),这是外部可见,但观察员看不到。最终,退化可能会导致系统瘫痪(完全失效),此时观察者也意识到问题所在。一个典型的例子是内存泄漏。
在一个间歇性错误行为的灰色故障中,我们可以循环多次。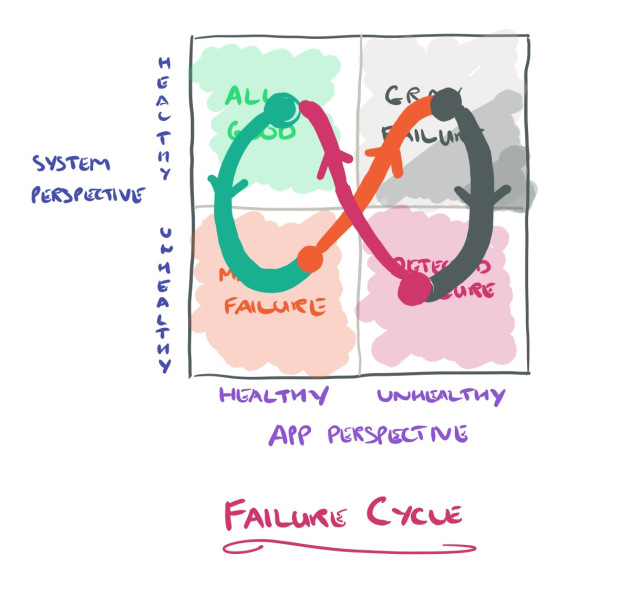
灰色失效实例
让我们看看来自Azure云平台的一些灰色失败示例,让这一切更加具体。
更多冗余=更少可用性!?
数据中心网络可以围绕发生故障的交换机进行路由,但当交换机遇到间歇性故障(如随机和无提示的数据包丢失)时,通常不会重新路由数据包。灰色故障会导致应用程序故障或延迟增加。
因此,我们有时会看到,增加冗余实际上降低了可用性。
与tail延迟一样,在处理给定请求时,遇到这种情况的机会随着扇出因子(所涉及的服务数量)呈指数级增加。如果我们有n个核心交换机(或者实际上是用于处理请求的任何n个资源),那么某个交换机被请求遍历的概率由1-\left(\frac{n-1}{n}\right)^{m}给出,其中m是扇出因子。
当m变大时,这个概率迅速接近100%,这意味着每个这样的请求都有很高的概率涉及到每个核心交换机。因此,任何核心交换机上的灰色故障几乎都会延迟每个前端请求。
您拥有的交换机越多(例如,为了增加冗余),其中至少一个交换机发生灰色故障的可能性就越大!
作者描述了一些事件,其中不健康的VM在内部遇到严重的网络问题,但故障检测器通过使用本地RPC与VM通信的主机代理接收心跳信号。因此,在用户报告问题之前,不会发现问题,也不会进行恢复。这将导致用户影响点和分辨率点之间存在较长的差距。
当治疗的效果比疾病本身更糟糕时
Azure存储数据服务器遇到严重的容量限制,但一个错误导致存储管理器未检测到该情况。当存储管理器向过载的数据服务器发送更多请求时,它最终崩溃并重新启动,这并没有解决底层问题,因此循环重复。
故障检测器确实在连续重新启动时检测到,认为数据服务器不可修复并使其停止服务。这给剩下的健康服务器带来了压力,导致更多的服务器降级并经历同样的最终命运。
当然,这最终导致了灾难性的连锁故障。
(另外,听起来他们需要一个背压机制!)。
黎明前的祸首
vm运行在计算集群中,其虚拟磁盘位于通过网络访问的存储集群中。有时,存储或网络问题意味着虚拟机无法访问其虚拟磁盘,这可能导致崩溃。
如果没有故障检测器检测到存储或网络的潜在问题,则计算群集故障检测器可能会错误地将故障归因于虚拟机中的计算堆栈。因此,这种灰色故障很难诊断
回应。事实上,我们遇到过这样的情况:负责不同子系统的团队因事件而相互指责,因为没有人有明确的证据证明真正的原因。
防止灰色故障
首先要注意的是,标准的分布式系统可用性机制不能很好地处理灰色故障,因为这些故障不属于其故障模型的一部分:
已经提出了许多技术来利用冗余和复制来容忍组件故障,例如主/备份复制、RAID、Paxos和链复制。许多这些技术都假设了一个简单的故障模型:故障停止。与故障停止不同,出现灰色故障的组件看起来仍在工作,但实际上遇到了严重问题。这种差异会对传统技术产生负面影响,并导致容错异常。
接下来我脑子里想的是“难道这不只是不充分的监控吗?“例如,如果你想了解你的网站表现如何,可以向它发送类似于用户将提交的外部请求。在这种假设下,差异可观测性问题是由不充分/不适当的观测引起的,这些观测无法捕捉到对客户真正重要的东西。
尽管通过让系统测量应用程序所观察到的东西来完全消除差分可观测性是理想的,但实际上是不可行的。在支持各种应用程序和不同工作负载的多租户云系统中,系统跟踪所有应用程序如何使用它是不合理的。
这里还隐藏着一个更深层次的问题,这可以追溯到二进制故障停止模型。故障检测器通常会发送一个“it failed”消息,然后启动恢复,但灰色故障并不是这样一个黑白问题。
解决灰色故障的一个自然方法是缩小系统与it服务应用程序之间的观察差距。特别是,系统观察器传统上侧重于可靠地收集有关组件是向上还是向下的信息。但是,灰色的失败使这些不只是简单的黑白判断。因此,我们提倡从单一的故障检测(如心跳)转向多维的健康监测。
另一种增加缩小观测差距机会的方法是从许多不同的有利位置综合观测。
……由于灰色故障通常是由观察者的孤立观察引起的,因此利用大量相互补充的不同组件的观察结果可以帮助快速发现灰色故障。事实上,我们研究的许多灰色故障案例只能以分布式的方式检测,因为每个单独的组件只有整个系统的部分视图(因此灰色故障是固有的)。
究竟如何做到这一点是一个悬而未决的问题。例如,如果观察结果接近系统的核心,他们可能看不到客户看到的内容。但如果靠近应用程序,内置的容错机制可能会掩盖故障并延迟灰色故障的检测。
我们设想一个独立的平面,它在核心系统的边界之外,但仍然与观察者或反应堆相连。
对我来说,这听起来非常像一个典型的集中控制风格的解决方案。我想知道从promise theory的前提出发的解决方案会是什么样的?
最后一项可能有助于灰色失效的技术是通过了解灰色失效周期如何随时间演变而来。如果可以学习这些时间序列模式,那么我们就可以预测更严重的故障并更早地做出反应。因为许多错误确实是良性的,所以必须小心不要弊大于利。
最后总结
随着云系统的不断扩展,被忽视的灰色故障问题成为实现高可用性的一大难题。因此,理解这个问题域是至关重要的……我们认为,要解决这个问题,关键是降低微分可观测性,这是灰色失效的一个关键特征。

若有收获,就点个赞吧
0 人点赞
