论文地址:Naiad:实时的数据流系统——Murray等人。2013年
许多数据处理任务需要对结果的低延迟交互访问、迭代子计算和一致的中间输出,以便子计算可以嵌套和组合。(例如,一种)对实时数据流执行迭代处理,并支持对结果的新的、一致的视图进行交互式查询的应用程序。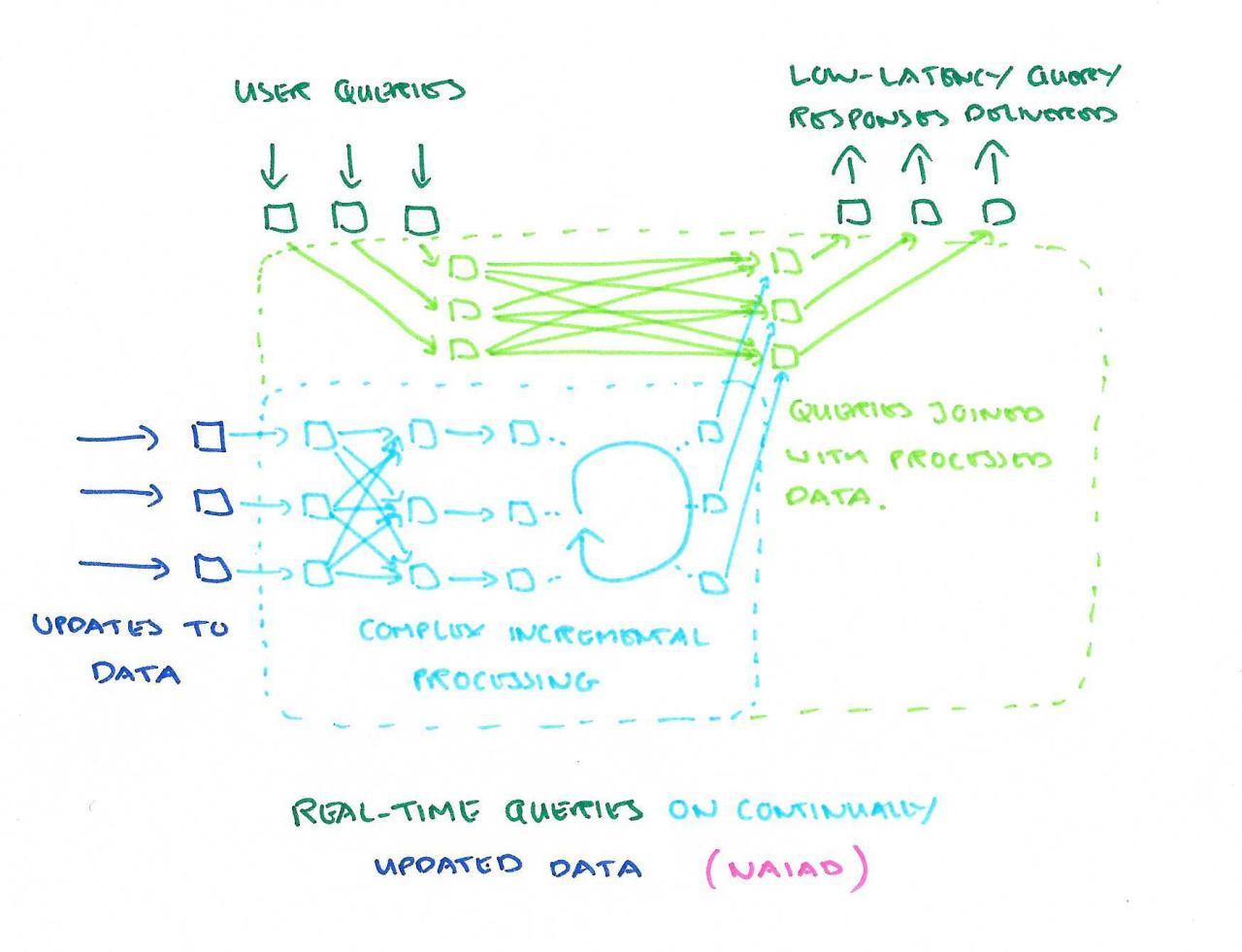
您可以通过将流处理器、批处理系统和触发器连接在一起来构建它,但是“在单个平台上构建的应用程序通常效率更高、更简洁、更易于维护。”
我们的目标是开发一个通用系统,满足所有这些需求并支持各种高级编程模型,同时实现与专用系统相同的性能。
该系统是Naiad,其核心是一个新的计算模型,称为及时数据流。在这项工作中,我真正喜欢的是,及时的数据流抽象支持在顶层构建更高级别的编程模型——同时保留在需要时下拉到较低级别进行更细粒度控制的能力。
我们设计了Naiad,以便将常见的及时数据流模式收集到库中,允许用户在满足需求时从这些库中提取数据,并在不满足需求时构建新的及时数据流顶点,所有这些都在同一程序中…。这种库代码与系统代码的分离使用户可以很容易地从现有模式中提取、创建自己的模式并适应其他模式,而无需访问私有api。公共可重用的低级编程抽象将Naiad与其他一些数据并行系统区分开来,这些数据并行系统强制使用单个高级编程模型,并在私有系统代码中隐藏该模型与低级原语之间的边界。
更高级别的库包括增量类LINQ操作符、Bloom框架的子集(它与其他LINQ操作符组成)和Pregel批量同步并行模型的一个版本。Naiad中PageRank、强连接组件、弱连接组件和近似最短路径算法的实现分别需要30、161、49和70行非库代码。PageRank的一个版本也建立在PowerGraph的Gather,Apply,Scatter模型之上,带有顶点切割——这需要547行代码“其中许多代码可以被GAS模型中的其他程序重用”
为了展示批量迭代处理的能力,该团队在Naiad重建了Vowpal-Wabbit的logistic回归管道的一部分。这需要大约300行代码,而且…
实验表明,Naiad在分布式机器学习的定制实现方面具有竞争力,并且使用Naiad的API为现有的应用程序构建通信库非常简单。
对于流式非循环计算,实现了Kineograph的k-曝光度量。
我们使用Distinct、Join和Count的标准数据并行运算符在26行代码中实现k-exposure。与Kineograph在同一Twitter流上运行时,使用32台计算机,每台计算机接收1000条tweets,5次运行的平均吞吐量为482988 t/s(无容错)、322439 t/s(每100个检查点)、273741 t/s(连续记录)。
(Kineograph本身在同一硬件上的速度为185000 t/s)。
作为将所有这些结合在一起的一个例子,团队编写了一个应用程序,它接收不断到来的推文流,提取标签并提到其他用户,计算提到其他用户的用户图中每个连接组件中最流行的标签,并提供对用户连接的组件中的顶级标签的交互式访问。程序的逻辑,不包括标准运算符和连接组件的实现,需要27行代码
Naiad的性能和表现力表明,及时数据流是一种强大的通用低级编程抽象,用于迭代和流计算。我们的方法与许多最近的数据处理项目的方法不同,后者将新的高级编程模式与专门的系统设计联系起来。我们已经证明,Naiad可以实现许多这些专用系统的特性,具有同等的性能,并且可以作为一个平台,用于没有现有系统支持的复杂应用程序。
现在是时候看看这个统一的,通用的,高效的抽象,叫做及时的数据流…
实时的数据流抽象
实时数据流支持以下功能:
- 允许数据流中反馈的结构化循环
- 无需全局协调就能生成和使用记录的有状态数据流顶点
- 顶点接收到给定一轮输入或循环迭代的所有记录后的通知。
总之,前两个特性需要以低延迟执行迭代和增量计算。第三个特性使得在流或迭代的情况下,在计算的输出和中间阶段都可以产生一致的结果。
实时的数据流是基于一个有向图的节点和逻辑时间戳消息沿边缘流动。图形可以包含循环。输入顶点从外部生产者接收消息序列,输出顶点向外部消费者发送消息序列。生产者用整数epoch标记每条消息,并在给定epoch内不再发送消息时通知输入顶点。生产者还可以关闭一个输入顶点,这意味着它将不再发送任何消息(在任何纪元)。输出消息同样用epoch标记,当消费者在epoch中不再发送任何消息时,输出顶点信号给消费者。
实时数据流图是有向图,其约束条件是顶点被组织成可能嵌套的循环上下文,并且有三个关联的系统提供的顶点。进入循环上下文的边必须通过入口顶点,离开循环上下文的边必须通过出口顶点。此外,图中的每个循环必须完全包含在某个循环上下文中,并且至少包含一个不嵌套在任何内部循环上下文中的反馈顶点。
该结构支持逻辑时间戳,包括每个遇到的循环的纪元号和循环迭代计数器。为这些时间戳定义了一个顺序,它对应于一个约束,即“稍后”的时间戳消息不可能是较早时间戳消息的原因。也就是说,如果t1<t2,那么t1’发生在t2之前。该模型支持不同阶段和迭代的并发执行。
顶点只实现两个回调:
ONRECV(e:Edge,m:Message,t:Timestamp)
ONNOTIFY(t:Timestamp)
ONRECV用于传递消息,ONNOTIFY通知顶点它已接收到时间戳的所有消息。
一个顶点可以调用SENDBY(e:Edge,m:Message,t:Timestamp)将一条消息沿着一条边发送到另一个顶点,并且在所有带有该时间戳或更早时间戳的消息被发送之后,NOTIFYAT(t:Timestamp)请求通知(通过ONNOTIFY)。(我发现论文中的文章有点难理解,但是查看Vertex类型的在线文档有助于理清问题)。
ONRECV和ONNOTIFY方法可以包含任意代码并修改任意逐顶点状态,但是它们的执行有一个重要的限制:当使用时间戳t调用时,这些方法只能调用SENDBY或NOTIFYAT,时间t′≥t。此规则保证消息不会“向后”发送,并且对于支持通知至关重要。
ONRECV和ONNOTIFY的调用是排队的,并且模型在交付顺序方面具有以下约束:
一个及时的数据流系统必须保证只有在不再调用v.ONRECV(e,m,t′)之后,才会调用v.ONNOTIFY(t),因为t′≤t。v、 ONNOTIFY(t)表示所有v.ONRECV(e、m、t)调用都已传递到顶点,是顶点完成与时间t相关的任何工作的机会。
调度器使用时间戳来确定哪些事件可以安全地传递:
及时数据流系统中的消息仅沿边缘流动,其时间戳由入口、出口和反馈顶点修改。由于事件无法在时间上向后发送消息,因此我们可以使用此(图)结构计算事件可能导致的消息时间戳的下限。通过将此计算应用于未处理的事件集,我们可以识别可能正确传递的顶点通知。
Naiad是一个高性能的分布式实时数据流模型的实现,它由一组主机工作进程来管理每个实时数据流顶点的划分。
工作节点使用共享内存在本地交换消息,并在每对进程之间使用TCP连接进行远程交换。每个进程都参与分布式进程跟踪协议,以协调通知的传递。

若有收获,就点个赞吧
0 人点赞
