论文地址: 跨时间源调试分布式系统 Whittaker et al., SoCC’18
这里的值是17,但其不应该是。为什么get请求返回17?
有时候最简单的问题可能是最难回答的。正如本文开篇所述:
调试分布式系统很困难。
为什么我们对这篇论文感兴趣的问题是出处问题。产生这种输出的原因是什么?起源已经在关系型数据库和数据流系统的上下文中进行了研究,但是这里我们对一般的分布式系统感兴趣。(严格地说,每个节点的行为都可以由确定性状态机建模:不确定性行为留给将来处理)。
为什么数据源不起作用
**
关系数据库有其数据源,表面上听起来和我们正在寻找的完全一样。
给定一个关系数据库、一个针对该数据库发出的查询以及查询输出中的元组,数据源为何解释了为什么生成输出元组。也就是说,why-provence生成的输入元组如果通过查询的关系运算符传递,将生成有问题的输出元组。
在我们的分布式系统设置中不起作用的一个原因是,系统的状态不是关系的,而且操作可能比源使用的定义良好的关系运算符集复杂得多,任意性也更强。
还有第二个更深层的原因为什么数据源出处在这里不起作用:
为什么数据来源会做出一个关键的假设,即底层关系数据库是静态的。它不能处理有状态分布式系统的时变特性。
为什么因果历史掩埋了具体原因
我们的分布式系统工具箱中有一个工具可以处理状态随时间变化的问题。事实上,它被明确地设计来处理潜在的原因:发生在关系和因果关系之前。这里的困难在于,一个事件的因果历史是一个粗略的过度近似,包含了以前所看到的一切。它告诉我们哪些事件可能导致了这个原因,但不是哪些事件真正导致了这个原因。在尝试调试分布式系统时,可能要处理很多无关的噪声。
我们该怎么做呢?
……因果关系缺乏数据依赖的概念,数据出处缺乏时间的概念。在这篇文章中,我们提出了wat起源(为什么跨时间起源):一种新的数据来源形式,将两者的思想结合起来。Wat-provenance将起源从针对静态数据库发出的关系查询领域推广到分布式系统中任意时变状态机领域。
将分布式系统中的服务器视为一个确定性状态机,它反复接收请求,相应地更新其状态,并发送响应。wat的来源是根据这样一个系统的痕迹来定义的。
系统的trace T是状态机接收的有序输入序列
T的子种族T’是T的保序子序列(但子序列中的事件不必是连续的)。
给定T的一个子trace T’,则T的超迹是T的一个子trace,它包含T的每个元素。
例如: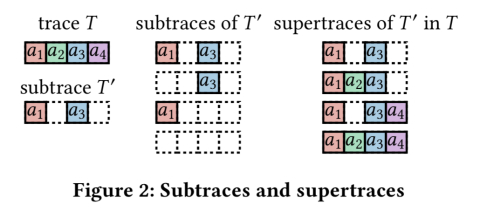
Wat-provenance的目的是将状态机M在给定输入i时产生输出o的直观概念形式化。
由于状态机是确定性的,我们可以从这样一个概念开始,即某些输出o的原因必须包含在输入的子种族中。E、 g.如果我们有一个KVS节点,trace T=set(x,1);set(y,2)和一个请求i=get(x),那么子trace T’=set(x,1)就足以解释输出1。这样的潜台词被称为o的证人。
在这个特定的例子中,T和T’都是o的见证者,但是注意T包含一些不需要解释输出的额外输入(集合(y,2))。所以我们需要一个最小的子竞赛。
如果我们不小心漏掉了什么,我们最终会制造假证人。假设一个服务器维护一组布尔值变量,这些变量都初始化为false。我们有一个trace T=set(a);set(b);set(c)和一个产生输出的请求(a&!b) | | c.输出为真的原因是c为真。所以set(c)是一个真正的证人。但是如果我们只考虑子种族集合(a)(所以我们处于a=true,b=c=false的状态),那么集合(a)也会看起来是证人,即使不是。为了避免虚假证人,我们增加了T’in T的每个超迹也必须是o的见证的规则。在这种情况下,我们说o的见证T’在T的超迹下是闭合的。由于超迹集(a);集(b);不是o的见证,我们通过这个规则排除了子迹集(a)。
坚持使用布尔服务器,假设我们有一个更简单的场景,我生成的输出o等于(a&d)|(b&c)。在这种情况下,跟踪T=set(a);set(b);set(c);set(d)包含两个子种族,这两个子种族都可能是真正输出的原因:set(a);set(d)和set(b);set(c)。因此,我们注意到一个输出的原因可以是一组证人。
所以我们得出:
- [出处]由o的每个见证T’组成,使得(1)T’在T的超迹下闭合,并且
- (2)T’的任何适当的子族也不是满足(1)的o的见证。
在计算wat来源时,首先计算T中超迹下闭合的证人集,然后去掉非最小元素是很重要的。如果首先尝试删除非最小元素,则可能会过度修剪。(参见本文第3.5节中的示例)。
Wat-provenance细化了因果关系,并包含了出处的原因。
黑匣子与简单界面
自动计算任意分布式系统组件的wat来源,我们称之为黑匣子,通常是棘手的,有时是不可能的…。(但是)…我们可以利用这样一个事实:现实世界中的许多黑匣子远非武断。许多黑盒有复杂的实现,但设计有非常简单的接口。
我们可以直接从接口指定它,而不是通过检查实现来推断wat的来源。wat provenance规范是一个函数,它给定一个trace T和一个请求i,返回一个建模为状态机M的黑盒的wat provenance wat(M,T,i)。
例如,对于Redis(~50K LOC),对key的get请求的wat-provenance规范只需要考虑该key的最新设置,以及所有后续的修改操作(例如incr、derc)。为真实系统的子集编写这些wat来源规范所需的代码行数少得惊人:

但并不是所有的制度都是如此的顺从。作者以实现某种机器学习模型的状态机为例,通过该状态机,客户可以提交训练数据(用于在线模型更新)或提交输入进行分类。在这里,wat来源规范可能和系统本身一样复杂。
西瓜测试框架
西瓜是一个原型调试框架,使用wat-provenance和wat-provenance规范。它充当代理,拦截与服务的所有通信并在关系数据库中记录跟踪。当在西瓜进程之间发送消息时,西瓜可以连接发送和接收,这样多个黑匣子就可以集成到同一个西瓜系统中。
有了代理填充程序,开发人员可以用SQL或Python编写wat源代码规范。
为了找到特定黑盒输出的原因,我们调用黑盒的wat来源规范。规范返回导致输出的见证集。然后,我们可以将见证中的请求跟踪回发送请求的黑盒,并重复该过程,调用发送者的wat provenance规范来获取新的见证集。
评估
评估是目前论文中最薄弱的部分。Wat起源规范是为20个真实世界的api编写的,这些api跨越Redis、POSIX文件系统、Amazon S3和Zookeeper(见上面的表1)。然后根据printf语句和SPADE(一个从各种源(包括OS审计日志、网络工件、LLVM检测等)收集出处信息的框架)对调试的易用性进行定性评估。这将导致下表:
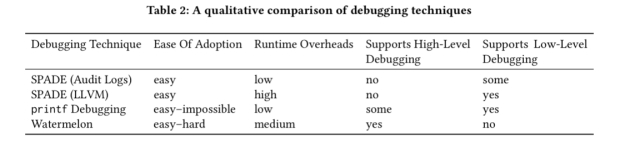
很高兴看到的是对使用wat provenance调试实际问题的评估。也许是将来的工作?
Wat-logs
我的最后一个想法是,服务器进程记录传入的请求及其响应是非常常见的(如果不是,请求也不是不合理的)。在这种情况下,如果有一个合适的测试系统,就应该可以直接询问wat-logs的出处问题。这将非常适合现有的故障排除工作流程,这些工作流程通常以日志中看起来不太正确的内容开始,并从中探究原因。

若有收获,就点个赞吧
0 人点赞
