论文地址:互联网规模的数据来源:架构、经验和未来之路Chen等人,CIDR 2017
单一数据库中的数据溯源已经得到了相当好的研究。然而,在本文中,Chen等人探索了在分布式环境和更大范围内追踪出处时会发生什么。他们工作的背景是计算机网络的起源,但是许多课程更广泛地应用于一般的分布式系统。
溯源是什么?Chen等人。提供一个好的定义,我们可以使用:
溯源在本质上是一种回答有关计算的“为什么”问题的方法。它通过将每个效果(如计算值)与其直接原因(如相应的输入和对其执行的操作)相关联来工作。因此,可以递归地“解释”一个特定的结果,方法是显示它的直接原因,然后是它们自己的原因,等等,直到达到一组基本输入。这个解释就是结果的来源:它是一棵树,其顶点表示计算或数据,其边缘表示直接的因果关系。
请注意,跟踪来源意味着能够同时跟踪原始输入和处理它们的操作(即某种形式的代码或其他形式的代码)。所以我们回到了我们昨天在Ground上看到的那种带有代码和数据版本控制信息的巨型分布式图。
这里有一个有趣的并列:这是一篇2017年的研究论文,研究在分布式环境中解释计算结果可能需要什么。GDPR,这在2018年5月成为欧盟的法律,使得当输入与人有关,并且要解释的计算值是影响他们的某个决定时,能够这样做成为一项法律要求。
作者探索的将出处扩展到分布式环境的一些关键挑战和机遇包括:
**
- 跨节点划分出处信息
- 添加时间信息以便可以询问有关过去状态的问题
- 保护来源信息免受攻击(否则可用于帮助诊断和防御)
- 扩展出处以覆盖数据和代码
- 用出处问“为什么不?”?’问题(预期的事情没有发生)
- 利用正确输出和错误输出之间的来源差异帮助确定原因
ExSPAN系统的基本架构如下: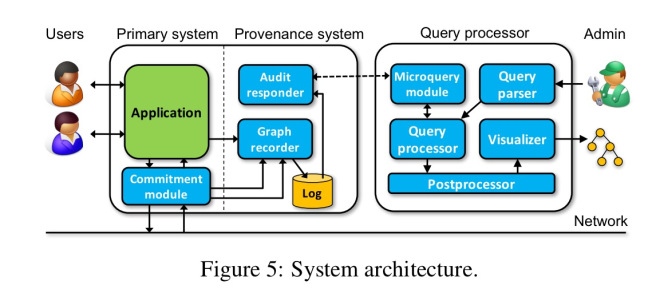
图记录器从在给定节点上运行的应用程序捕获出处,并将其记录在本地日志中。(可选)承诺模块将加密承诺添加到传出消息,并验证传入消息。当需要对查询作出响应时,审核响应程序会将日志中的摘录发送到查询处理器。请注意,这种体系结构似乎依赖于一组相当静态的节点,以及它们本地日志的可靠持久性,正如我们可以想象的那样,用一种独立于任何一个节点而生存的更复杂的分布式存储机制来取代它。
图记录器本身有三个用于提取出处信息的选项:在幸运的情况下,应用程序是用声明性语言(例如NDlog)编写的,该语言允许通过运行时直接提取出处。有了源代码可用性,应用程序可以被检测到调用记录器,如果只有二进制文件可用,“仍然可以通过外部规范提取出处”。我可以想到另外两种选择:应用程序也可以发出记录器订阅的来源事件,一些来源可以通过exhaust 日志恢复,就像在The Mystery Machine或lprof中一样。
溯源图
**
ExSPAN是为计算机网络中的数据源而构建的,因此它的核心是表示网络事件和规则的顶点,以及它们之间的边,以显示数据包的流。这个图被分割并分布在许多节点上。ExSPAN对源位置信息使用了增量视图维护技术,以提高查询效率。
扩展具有时间信息的起源图以能够回答历史问题需要图移动到仅附加模型,并添加几个新的顶点类型(存在、插入、删除、出现、消失、导出和下位)。这些顶点的意义和用法在前面的一篇文章中有充分的解释。在这一点上,出处信息开始在数量上扩大。为了保持这一点,一个选项是只记录输入和不确定的事件,在查询时派生其他所有事件。然后可以使用熟悉的记录快照状态的方法(从事件日志重建状态时可能会这样做)来加速此重建。
我们还需要安全的取证,因为今天的网络和计算机是恶意攻击的目标。在对抗性环境中,受损节点可以篡改其本地数据和/或欺骗其他节点……因此,在执行取证时,验证出处数据的完整性非常重要。
为了满足这一需要,将发送、接收和信任顶点类型添加到图中。当一个节点从另一个节点接收到一个元组时,会添加相信元组,记录在另一个节点上确实看到该元组的信念。它们存储在防篡改日志中,这样节点就可以始终证明其过去交互的详细信息。该模型(同样,在前面的一篇文章中有详细描述)提供了两个保证:
a) 如果至少有一个正确的节点可以观察到任何行为,则该行为的起源将是正确的,并且b)如果正确的节点检测到错误的行为,则它可以分辨出受影响的起源的哪一部分,并将错误的行为归因于至少一个错误的节点。我们的原型表明,该模型在BGP路由、Chord DHT和Hadoop MapReduce应用程序中运行良好。
为了能够回答为什么一些好的事情没有发生,图可以进一步扩展为负顶点,从而支持反事实推理。这种方法让我想起了Molly:
在较高的水平上,消极出处发现了失踪事件可能发生的所有可能方式,以及每一种情况没有发生的原因。因此,此增强为每种顶点类型(除了“相信”之外)创建一个“负孪生”。
下面是跟踪丢失的HTTP请求的来源图示例:
差异种源
通过推理工作实例和非工作实例的起源树之间的差异,可以更容易地确定问题的根本原因。这个团队称这种方法为差异起源。
网络中的一个挑战是,一个很小的初始差异可能会导致随后的网络执行大不相同——例如,不同的路由决策可能会将数据包发送到完全不同的路径。因此,工作种源树和非工作种源树之间的差异可能远远大于人们的预期。差异源采用反事实的方法解决这个问题:它将网络执行“回滚”到源树开始发散的点;然后,它将非工作源树上不匹配的元组更改为正确的版本,并将执行“回滚”到两棵树对齐为止。
原始种源
软件定义的网络意味着你可以在软件和硬件上都有漏洞!因此,您可能希望不仅包括数据,还包括源代码图中的代码。我认为代码和数据一样是源代码的第一类部分,但在ExSPAN中,对程序代码的reason的扩展名是“meta-provenance”
元起源有一组元元组,它们表示程序本身的语法元素,还有一组元规则,它们描述程序语言的操作语义。
我猜这里有“meta”前缀,因为这些规则描述了如何生成/操作常规数据元组。
作者给出的元起源的用例是自动网络修复,在这种情况下,可以自动探索对程序和/或配置数据的更改,以找到实现期望结果所需的条件。当然,这需要您的程序用一种合适的语言来表达……“我们已经通过为用NDlog、Trema和Pyretic编写的中等复杂的SDN程序找到高质量的修复来验证了这种方法。”
出处和隐私
在保护隐私的同时收集出处信息仍然是一个开放的问题!
使用provence诊断跨越多个信任域的网络问题仍然是一个开放的问题。在单个信任域中(例如,在集中数据库或企业网络中)更容易收集出处;但在提供强大的隐私保证的同时收集和分析出处似乎是一个具有挑战性的问题,例如,在多租户云中执行诊断时。
难题的可能部分可能包括差异隐私、安全多方计算和/或可信硬件平台。

若有收获,就点个赞吧
0 人点赞
