Anna: 一个可以任意扩展的KVS database Wu et al., ICDE’18
Anna的主要结构和特性:
使用Anna v0作为内存存储引擎,我们着手解决上面描述的云存储问题。我们的目标是将云计算中速度最快的KVS也发展成最具适应性和成本效益的KVS。我们在Anna中添加了3个关键机制:垂直分层、水平弹性和选择性复制。
Anna v11中的核心组件是一个监视系统和策略引擎,它共同支持工作负载响应性和适应性。为了满足用户定义的性能(请求延迟)和成本目标,监控服务跟踪并调整资源以适应工作负载的变化。每个存储服务器都收集有关其服务的请求、存储的数据等的统计信息。监控系统会定期收集和咀嚼这些数据,策略引擎使用这些统计信息通过上面列出的三种机制之一采取行动。每个操作的触发器很简单:
- 弹性:为了使系统适应不断变化的工作负载,系统必须能够自动上下缩放以匹配它看到的请求量。当一个层的计算或存储容量饱和时,我们将节点添加到集群中,当资源未充分利用时,它们将被释放以节省成本。
- 选择性复制:在实际的工作负载中,通常有一组热键,这些热键的复制应该超出容错要求,以提高性能。这会增加核心和网络带宽,以满足常见的请求。Anna v0启用了key的多主复制,但对所有key都有一个固定的复制因子。你可以想象,那是不合理的昂贵。在Anna v1中,监视引擎选择访问次数最多的key,并专门增加这些key的副本数量,而不必为复制冷数据支付额外费用。
- 升级和降级:与传统的内存层次结构一样,云存储系统应将热数据存储在高性能、内存速度层中以实现高效访问,而冷数据应存储在较慢的层中以节省成本。我们的监控引擎根据访问模式在层之间自动移动数据。
为了实现这些机制,我们必须对Anna的设计做两个重大的改变。首先,我们将存储引擎部署在多个存储介质上—当前为RAM和闪存磁盘。这些存储层中的每一层都代表了不同的成本-性能权衡,类似于传统的内存层次结构。我们还实现了一个路由服务,将用户请求发送到正确层中的正确服务器。这为用户提供了一个统一的API,而不管数据存储在哪里。这些层中的每一层都有从Anna的第一个版本继承来的相同的富一致性模型,因此开发人员可以处理单个(广泛可参数化的)一致性模型。
这项工作出自伯克利RISE的项目。以下是Joe Hellerstein在他的博客中介绍这项工作的方式:
作为研究人员,我们提出了一个反文化的问题:要建立一个能够跨越多个数量级的关键价值存储,从单个多核盒子到全球云,需要什么?事实证明,这种好奇心会导致一个具有相当有趣的实际意义的系统。回答我们问题的关键设计点集中在我的研究小组多年来正在进行的一个主题上:设计避免协调的分布式系统。我们已经发展了基本理论(CALM定理)、语言设计(Bloom)、程序检查(Blazes)和事务协议(HATs、不变汇合定理)。但直到现在,我们还没有展示这些原则在多核和云环境中可以实现的性能和规模。想想类似多米诺骨牌倒塌了。
在它的核心中Anna使用无协调的actors。每个参与者都是一个执行线程,并映射到一个内核(参见我们最近看到的FFWD)。无协调部分来自于管理基于晶格的复合数据结构(如Bloom和CRDTs)中的所有状态。参与者之间的通信发生在每个epoch的末尾(epoch决定GET操作的过时限制),但这是异步gossip,不在请求处理的关键路径上。

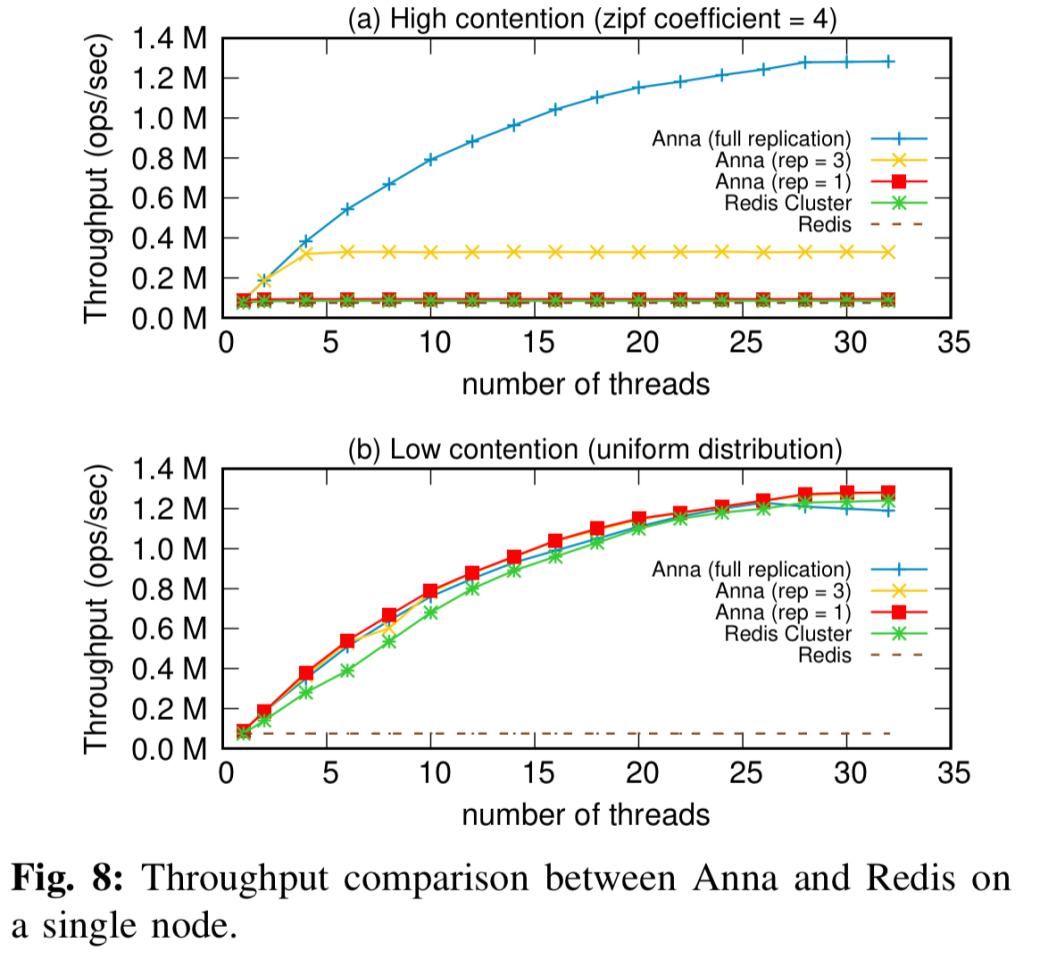
下面的结果显示了该设计在跨数量级扩展方面的成功,其中Anna在单个节点上的性能优于Redis(和Redis Cluster):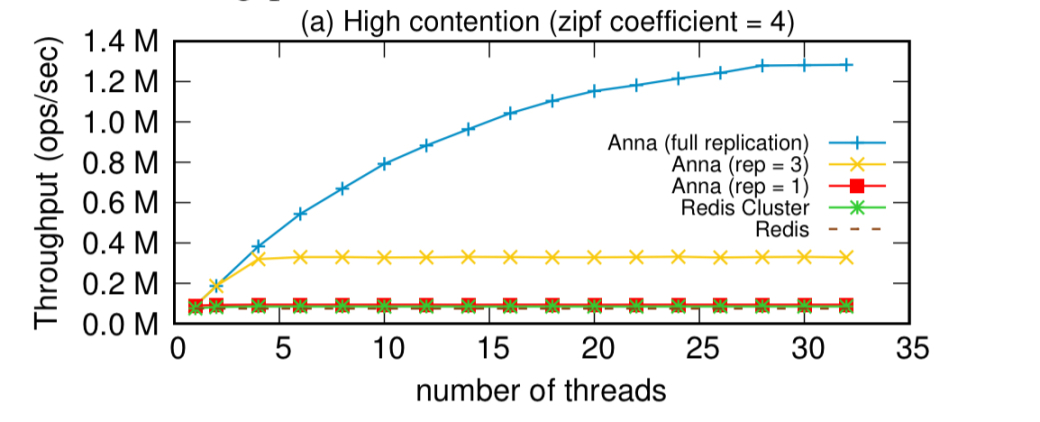
在分布式环境下,它的表现也优于Cassandra:
但其有获取一个相关的办法直接解决KV的问题。
Anna的设计目标
**
Anna的高级目标是在单个多核机器上提供出色的性能,同时还能够灵活地扩展到地理分布的云部署。系统应支持一系列一致性语义,以满足应用程序的需要。由此产生了四个设计要求:
- 需要对key空间进行分区,不仅在分布时跨节点,而且跨节点内的核心。
- 扩展工作负载(特别是那些分布高度倾斜的工作负载,aka)。“热键”)系统应该使用多主复制并发地为来自多个线程的一个键提供PUT和GET服务。
- 为了获得最大的硬件利用率和性能,系统应该具有无等待执行,这样一个线程就不会在其他线程上被阻塞。这排除了锁定、一致性协议,甚至“无锁”重试。
- 为了在不影响其他目标的情况下支持广泛的应用程序语义,系统应该具有广泛的无协调一致性模型的统一实现。
也许这项工作的主要教训是,我们的可伸缩性目标引导我们必须遵循良好的软件工程规程。
Lattices
实现无协调过程的关键是使用基于格的合成(严格的有界连接半格)。这样的格在某些域S(可能的状态集)上操作,使用一个二进制“最小上界”运算符sqcup和一个底值perp。最小上界运算符必须是关联的、可交换的和等幂的($\perp(a,a)=a,\ for all a\in S$)。这些统称为ACI属性。这样的晶格也是CRDTs的基础。
格对Anna来说很重要有两个原因。首先,格对合并更新的顺序不敏感。这意味着,即使管理这些副本的参与者以不同的顺序接收更新,它们也可以保证副本之间的一致性…。其次,可以组合简单的格子构建块,以实现一系列无协调一致性级别。
Anna采用Bloom的晶格合成方法,将简单的基于晶格的积木(ACI)如计数器、映射和对组成高阶结构,并通过归纳法检验ACI的性质。如果每个构建块都有ACI属性,并且组合规则保留ACI属性,那么我们就可以验证组合数据结构,而无需直接验证它们。
Anna中每个worker的私有状态都表示为一个格值映射格(map lattice)模板,由其键和值的类型参数化…。用户的PUT请求被合并到MapLattice中。MapLattice的merge操作符接受两个输入散列映射的键集的并集。如果两个输入中都出现一个键,则使用ValueLattice的合并函数合并与该键关联的值。
不同的晶格成分可用于支持不同的稠度级别。例如,下面的格支持因果一致性。矢量时钟本身就是一个映射格,客户机代理ID作为键,版本号作为值。
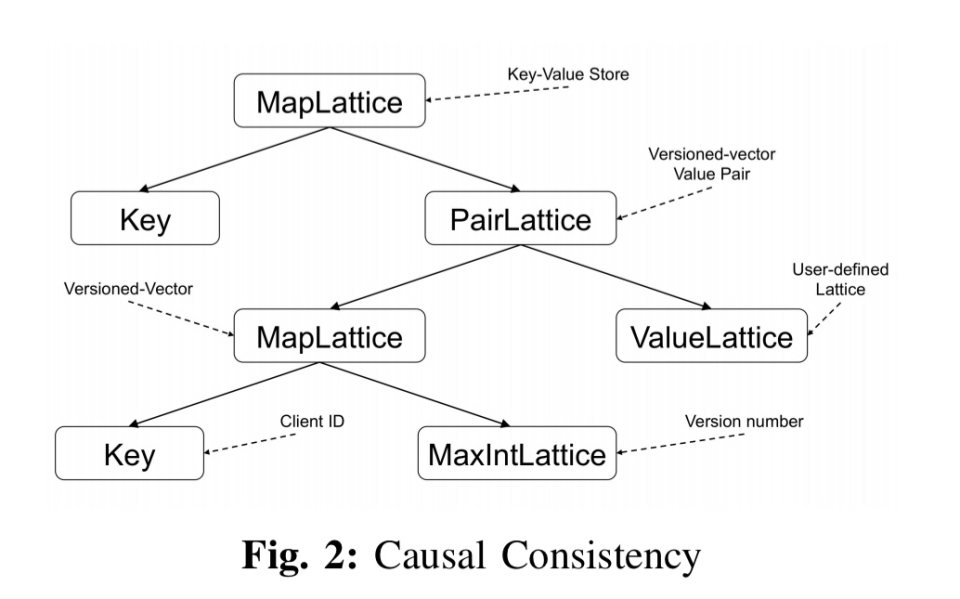
合并操作采用(向量时钟,值)对,并使用最小上界函数合并不可比的并发写入。
只需几行代码就可以更改实现以支持其他一致性模型。从简单的最终一致性开始,下表显示了实现各种协调一致性一致性级别所需的附加C++ LOC的数量。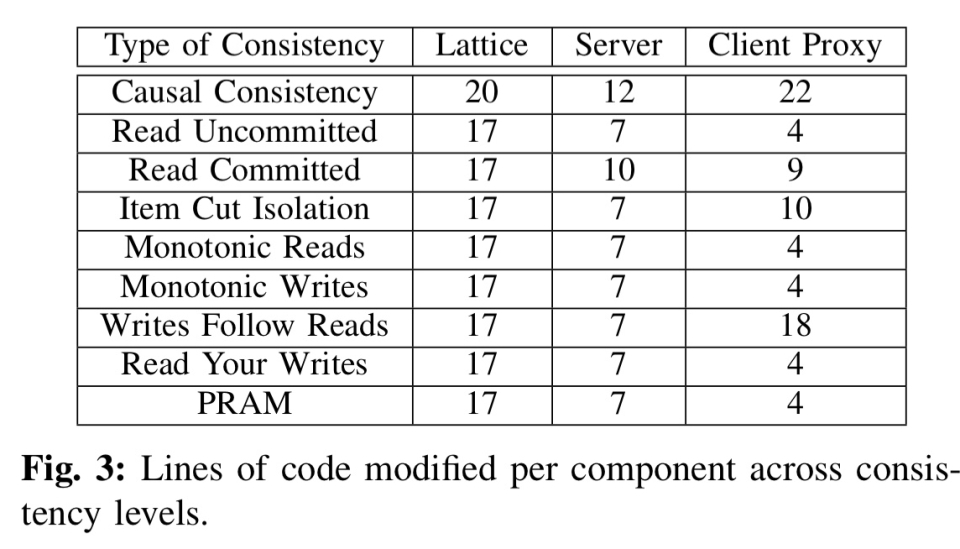
设计与实现
在给定的节点上,Anna服务器由一组独立的线程组成,每个线程运行无协调的actor模型。每个参与者的状态保持在基于格的数据结构中。在1:1的通信中,每个参与者/线程被固定到一个唯一的CPU核心。没有共享的键值状态:一致的散列用于跨参与者划分键空间。多主复制用于跨参与者复制数据分区。
处理发生在基于时间的多播时段(例如100ms)。在Epoch期间,对参与者拥有的键值对的任何更新都将添加到本地变更集。在Epoch结束时,使用格的merge操作符合并变更集中的本地更新,然后将这些key多播到相关的主节点。参与者还检查来自其他参与者的传入多播消息,并将来自这些参与者的key值更新合并到自己的本地状态。GET响应的陈旧性受(可配置的)多播周期的限制。
参与者之间的通信使用ZeroMQ完成。在一个节点内,它将通过进程内传输,在进程间,它将通过tcp传输上的协议缓冲区。
Actors可以动态地加入和离开。详见本文第七章C节。
整个代码库,除了第三方库(例如ZeroMQ),但包括格库、支持所有一致性级别和客户端代理代码,都是2000行C++。
评价
从单个节点上的性能开始,当在所有参与者之间使用完全复制时,Anna的性能在高争用工作负载下非常出色,并且将绝大多数时间实际用于处理请求(而不是等待)。
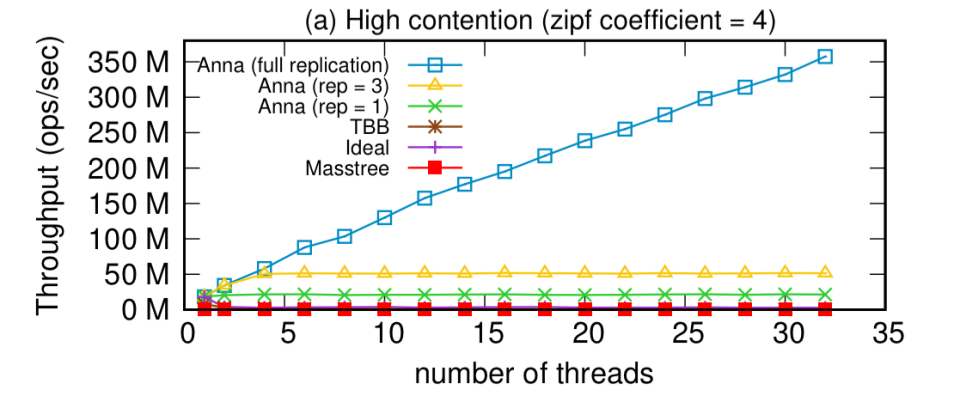
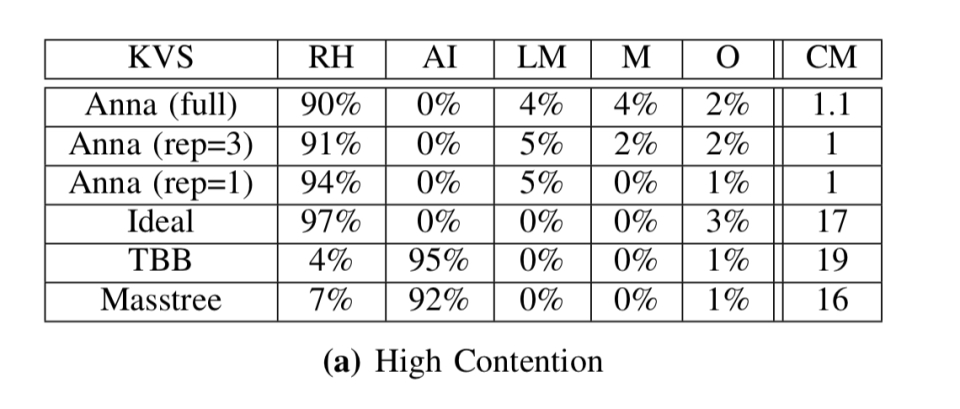
不过,在低争用工作负载下,使用较低的复制因子(例如,每个key 3个主节点)效率更高:

从这个实验中得到的教训是,对于支持多主复制的系统,在低争用工作负载下具有高复制因子可能会损害性能。相反,我们希望动态监视数据的争用级别,并有选择地跨线程复制高度满足的key。
作为另一个参考点,下面是在高争用和低争用工作负载下与Redis的单节点比较:

当在多个服务器上添加线程时,Anna的伸缩性很好(下表中第33个线程的略微下降是因为这是驻留在第二个节点上的第一个线程,触发了网络上的分布式多播):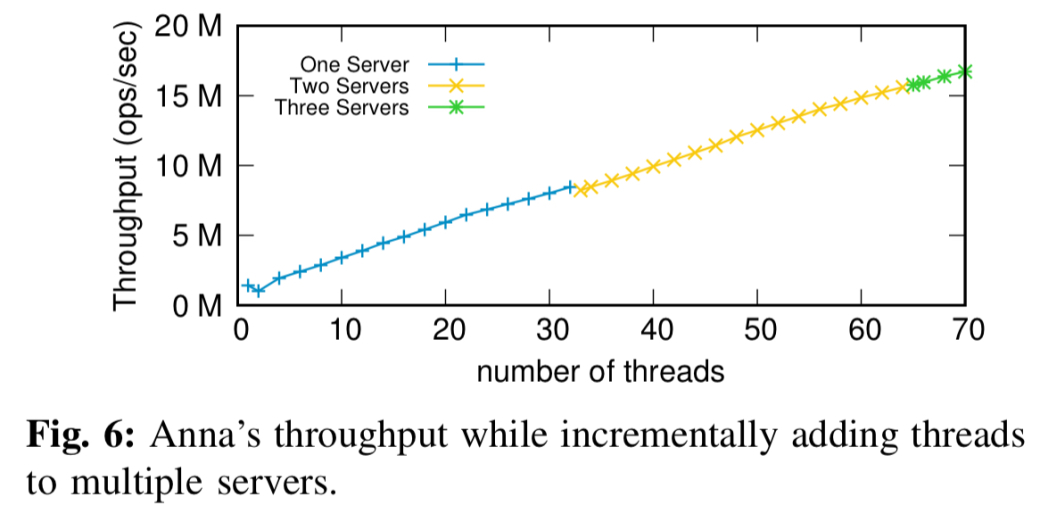
正如我们之前看到的,在分布式环境中,安娜与Cassandra相比非常有利: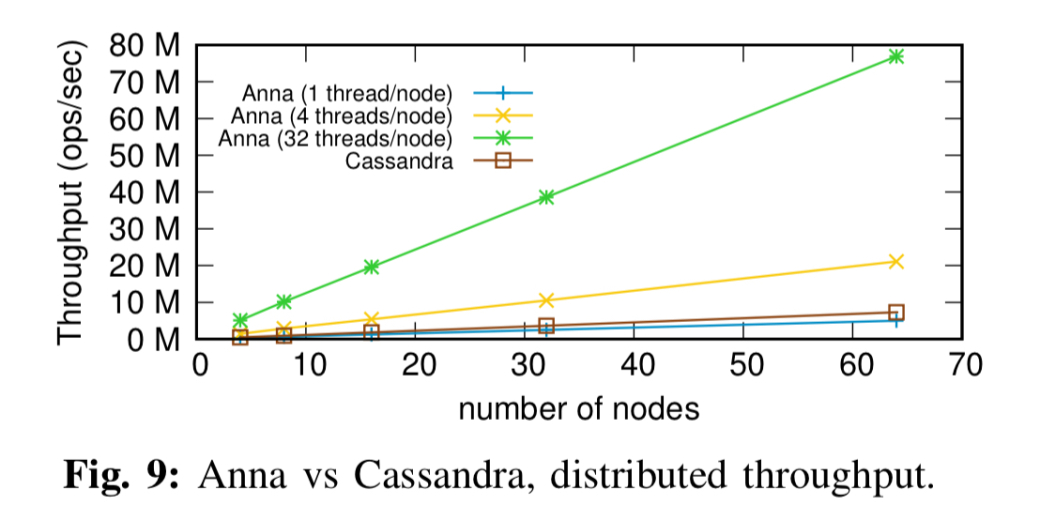
总而言之:
Anna通过在高争用情况下复制热键,可以显著优于Redis集群。
Anna可以在低竞争下与Redis集群的性能相匹配。
如果允许在每个节点上使用所有32个可用内核,Anna的性能可以比Cassandra高出10倍。
最后一句话
我要把最后一句话留给乔·海勒斯坦,他在博客中写道:
Anna是个原型,我们学了很多。我认为,我们所做的经验教训远远超出了KV数据库,适用于任何管理基本上所有内部状态的分布式系统。我们现在正在积极开发一个扩展系统,代号基岩,基于Anna。基岩将在云中提供这种设计的免提、经济高效的版本,我们将开放源代码并更积极地支持它。注意这个地方!

若有收获,就点个赞吧
0 人点赞
