论文地址:Rex:使用相关的变更分析来防止大型服务中的错误和配置错误,Mehta等,NSDI’20 和
更改前进行检查:防止服务更新中的相关故障,Zhai等人,NSDI’20
我从NSDI’20中选择了两篇有关相关性的论文。 Rex是在Microsoft中广泛部署的一种工具,用于检查您没有但可能应该具有的关联:它查看提交中已更改的文件,并警告开发人员如果经常更改的文件没有被更改。 另一方面,CloudCanary是关于检测您确实具有但可能不想要的关联的:它查找整个系统中关联故障的潜在原因,并可以针对性地提出建议以提高系统可靠性。
通过关联提高系统可靠性
“如果您更改foo设置,请不要忘记您还需要更新所有客户端…”
大型服务在非常大的代码库和配置存储库的基础上运行。要不间断地运行服务,不仅取决于正确的代码,还取决于正确的网络和安全配置以及合适的部署规范。这导致服务的组件/源之内和之间的各种依赖关系有机地出现。当工程师更改代码或配置的特定区域时,这些依赖性要求他们对其他代码或配置区域进行更改…。缺乏文档或规范的工程师经常错过对代码或配置文件进行必要更改的机会。这可能会延迟部署,增加安全风险,在某些情况下甚至会完全中断服务。由于这种相关性造成的中断异常频繁。
Rex旨在消除这些干扰。它在Microsoft广泛部署,包括Office 365和Azure团队,在14个月内捕获了4,926项更改,其中一些可能导致严重的服务中断。 “ Rex在避免不良部署,服务中断,构建中断和错误提交方面产生了重大影响。”
下表突出显示了一些相关的变更需求示例,以使我们对我们正在谈论的事情有一种感觉:从未能更新javascript测试到数据中心机架配置文件的协调变更等所有内容。
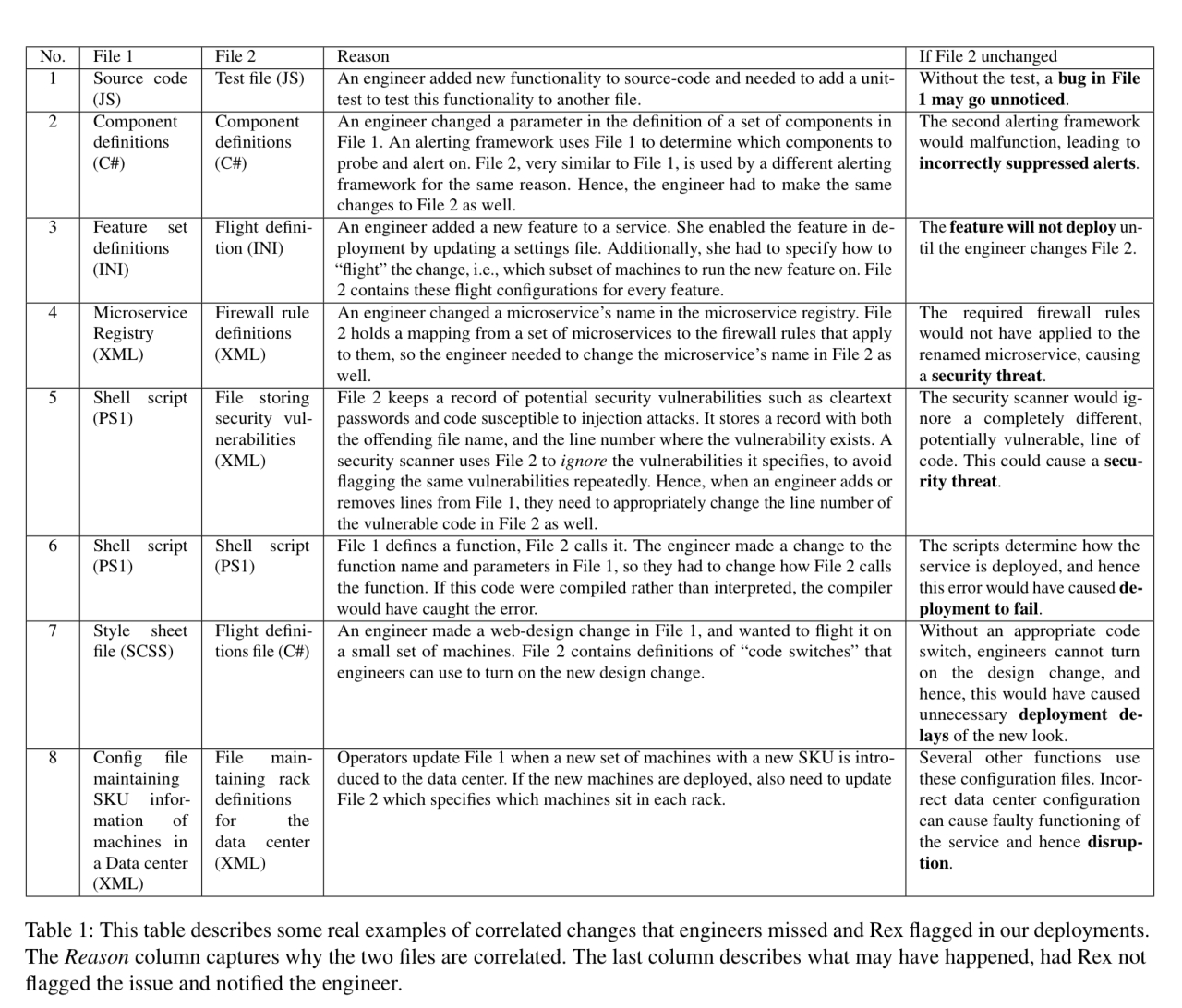
对于开发人员的Rex建议,它作为对请求请求的注释显示,提醒开发人员可能潜在的相关更改,在合并之前可能需要进行调查。
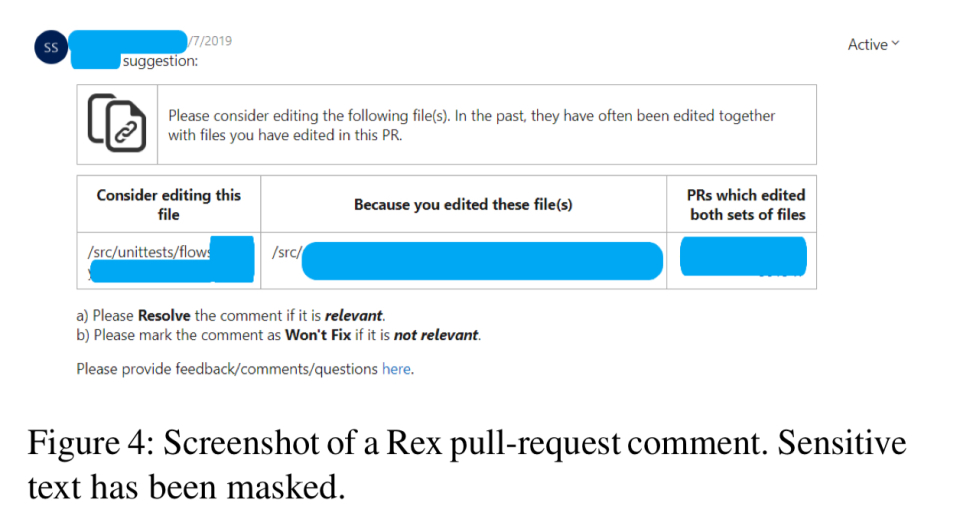
Rex通过挖掘提交日志来查找相关更改(在文件级别)来工作。
在第一阶段,称为变更规则发现,Rex在六个月的提交日志数据中使用关联挖掘:FP-Growth算法用于查找频繁的项目集(经常一起更改的文件集),然后查找这些项目集被变成变更规则。以一个频繁的项目集F为例,该项目集分为X和Y子集。如果对X中的所有文件都进行了更改,则建议添加Y中的文件的规则也应增加,如果该规则的置信度高于阈值。置信度定义为F中所有文件一起更改的次数除以X中所有文件一起更改的次数。
第二阶段完善发现的变更规则。 First Rex会查看在X中引入文件的更改,并以正则表达式(即,捕获集合中所有更改的最特定的正则表达式)创建差异的最具体概括。然后,通过测试差异是否与发现的正则表达式匹配来保护更改规则。
给定存储库的模型每天都会进行微调。开发人员根据Rex的建议采取的行动(即是否对PR进行了修改以包括对建议文件的更改)用于确定建议是对还是对。
Rex当前在360个存储库上运行,并且采用率迅速增加……Rex在避免不良部署,服务中断,构建中断和错误提交方面产生了重大影响。
通过消除相关性来提高系统可靠性
断层图可以对系统中组件之间所有结构上的依赖性进行建模,并且可以用来识别薄弱环节-即图中具有较大爆炸半径的点。
故障图是分层的DAG,表示给定系统内组件故障之间的逻辑关系。故障图中的根节点表示目标服务故障,它指示整个服务的故障。 其余节点是中间故障,它们描述基本故障如何导致更大的服务中断。
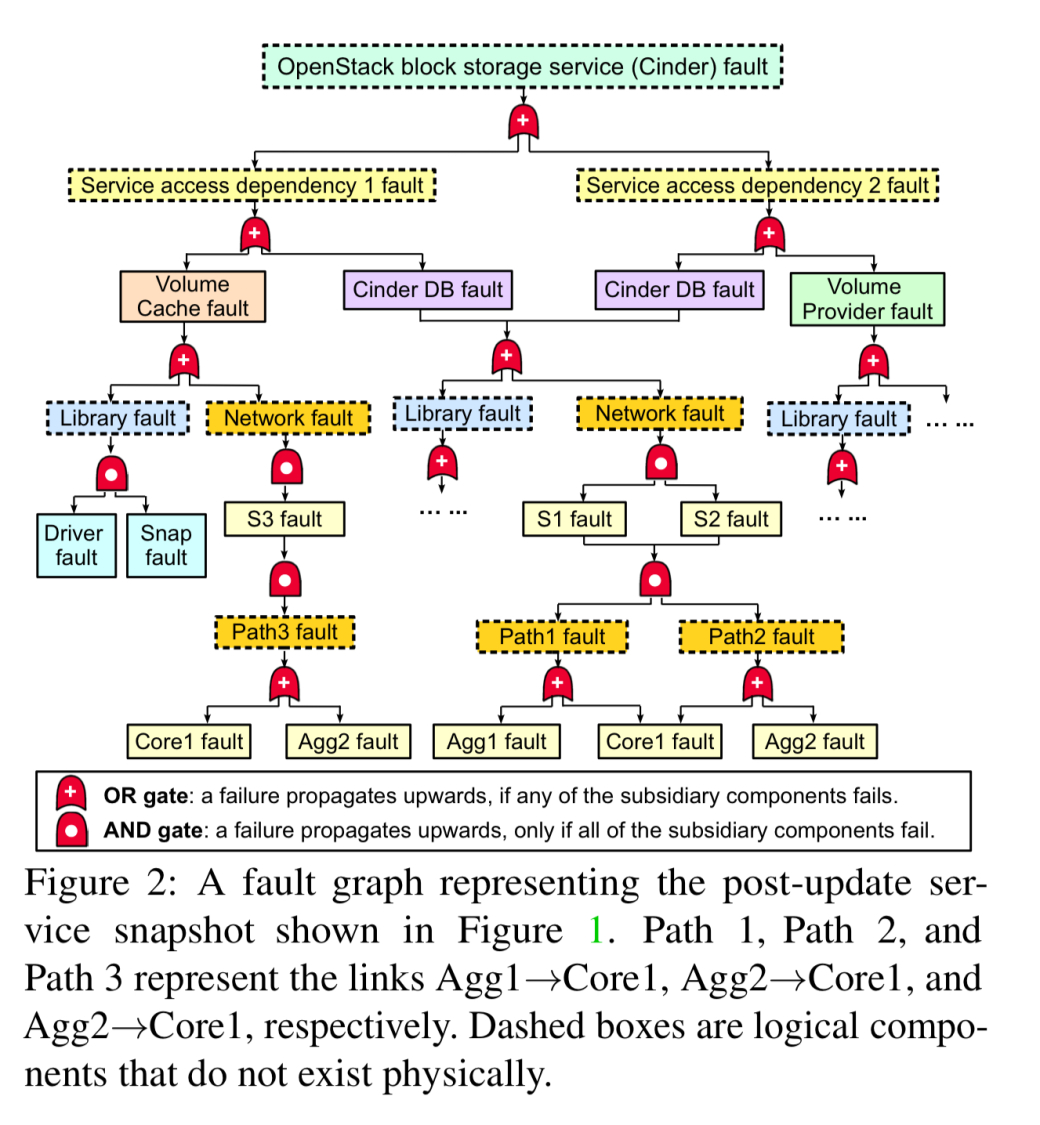
在CloudCanary之前,故障图的最新技术是一站式服务审计:发现和分析故障图太费力了,因此无法在操作期间进行实时审计。 CloudCanary包含两个关键组件:
SnapAudit使用增量审核算法,该算法可识别差异故障图,从而捕获更新后服务的前后状态之间的差异。为了加快分析速度,SnapAudit然后将差分故障图转换为布尔公式,并使用高性能的MinCostSAT求解器。分析的目的是提取最小的风险组。风险组是一组组件,因此,如果它们全部失败,则服务将失败。最小风险组是指从其中删除任何一个组成部分后就不再是风险组的组织。
给定故障图G的前k个风险组是按大小或故障概率排列的最小风险组的排序列表。在故障图中提取最小风险组很困难。
DepBooster允许操作指定可靠性目标,然后生成一组改进计划以使系统满足该目标。可以将可靠性目标指定为风险组大小目标(例如,最小风险组不应包含少于3个项目)和失败概率目标的组合。如果系统当前未满足指定的目标,则DepBooster将生成包括移动和添加副本操作的改进计划。
我们的结果表明,SnapAudit可以在8分钟内识别出1,183,360个组件服务中的相关故障根本原因,比最先进的系统快200倍,而DepBooster可以在数分钟内找到高质量的改进计划。
CloudCanary的评估包括对“从主要服务提供商处收集的真实更新跟踪”的分析。该跟踪包含300多个更新,从软件更新到微服务,再到电源和网络交换机的更改。它为部署这种实时分析提供了令人信服的理由:
CloudCanary在微服务更新中发现了50多个风险组,运营商确认其中96%的风险组可能导致相关的故障。
CloudCanary在电源中发现了10多个风险类别。运营商确认,所有这些因素均可能导致相关的故障,并且过去有30%的故障实际上导致了服务停机。
CloudCanary找到了30多个网络风险组,包括ToR /聚合交换机和共享光纤。所有这些都被运营商确认。
CloudCanary发现的故障图和风险组是弹性工程工具箱中的另一个出色工具,并且是对混乱工程技术的很好补充。

若有收获,就点个赞吧
0 人点赞
