基于分类存储构建弹性查询引擎 Vuppalapati, NSDI’20
本文描述了基于snowflake cloud的数据仓库的设计决策,详细阐述了其究竟有什么特别之处。
当我想到云原生架构时,我想到的是分解(使每种资源类型能够独立扩展)、细粒度的资源分配单元(实现对不断变化的工作负载需求的快速响应,即弹性)和隔离(使租户分离)。通过对客户工作量的研究,我们发现Snowflake cloud在这些方面的得分都很高,但一旦你分析细节,其仍然存在着不同的挑战。
本文介绍了snowflake cloud的设计和实现,并讨论了云基础设施(新兴硬件、细粒度计费等)的最新变化如何改变了指导snowflake系统设计和优化的许多假设。
从无共享到分解存储
**
传统的数据仓库系统主要基于无共享设计:持久数据被划分为一组节点,每个节点负责其本地数据。从云本机设计的角度分析,这提出了一些问题:
- CPU、内存、存储和带宽资源都聚集在每个节点上,无法独立地进行扩展,因此很难在多个维度上有效地适应工作负载。
- 资源分配的单元是粗粒度的(节点),静态分区使弹性变得困难。
- 现代工作负载中越来越多的数据来自不太可预测和高度可变的数据源
- 对于这样的工作负载,无共享架构会导致高成本、不灵活、低性能和低效率,这会损害生产应用程序和集群部署。
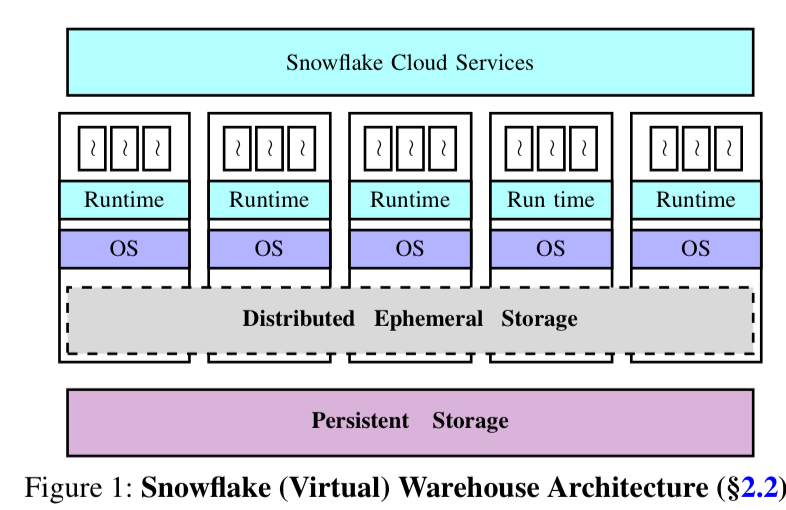
Snowflake是一个数据仓库,旨在克服这些限制,实现这一点的基本机制是计算和存储的分离(分解)。客户数据保存在S3(或在Azure或GCP上运行时的等效服务)中,计算在EC2实例中处理。如果每次都从S3读取所有数据,那么性能就会受到影响,所以Snowflake当然有一个缓存层——一个由仓库中所有节点共享的分布式临时存储服务。缓存用例可能是最熟悉的,但事实上它并不是临时存储服务的主要目的。主要目的是处理查询处理期间由查询运算符(例如联接)生成的(可能是大量)中间数据。租户隔离是通过为每个租户提供单独的虚拟仓库(VW)来实现的。
工作量特征
snowflake的设计受其所需支持的工作负载特性的影响。本文基于14天内执行的约7000万次查询所收集的数据。
- 大约28%的查询是只读的,读取的数据量超过9个数量级。查询工作时间内的卷峰值。
- 大约13%的查询是只写的,数据量的变化超过了8个数量级。
- 其余的是读写查询,读写比在多个数量级上变化
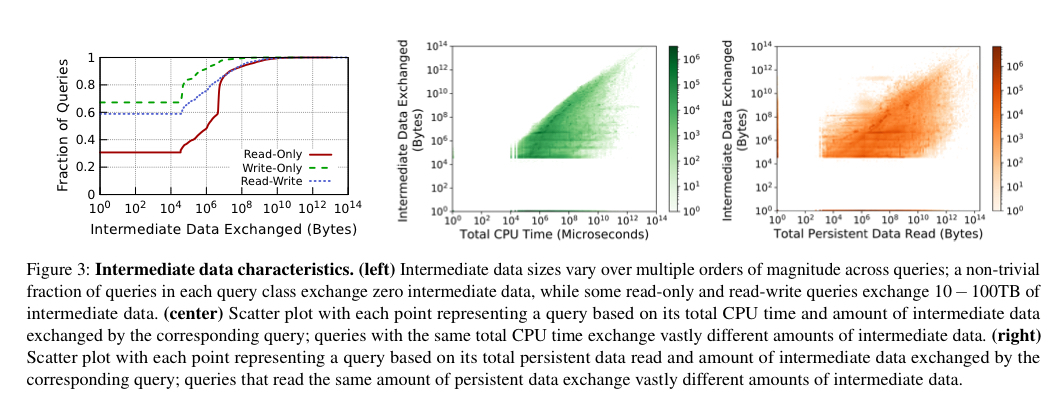
- 查询还需要在执行期间处理不同数量的中间数据。有些查询可以交换数百GB甚至TB的中间数据。对于大多数查询来说,预测查询生成的中间数据量是“困难的,甚至是不可能的”。中间数据大小在查询中的变化超过多个数量级,并且与持久数据读取量或查询的预期执行时间几乎没有或根本没有关系。
分解(或非分解)存储
到目前为止,我们已经看到持久性存储和计算层被分解成snowflake框架模型:能够独立地扩展,并且所有持久性存储都可以从任何节点访问。但是中间数据的临时存储服务不是基于S3的。这是一个三层结构,当需要时,节点上的内存数据会溢出到本地ssd,如果它们耗尽了,则会反过来溢出到S3。因此,此存储系统的两个主要层没有被分解,而是绑定到计算节点。当中间数据不需要时,相同的临时存储用作经常访问的持久数据的直写缓存。一致的哈希方案将数据映射到节点。
理想情况下,中间数据可以完全放在内存中,或者至少放在ssd中,而不会溢出到S3。考虑到计算、内存和ssd的耦合,这证明很难提供。正如我们前面所看到的,中间数据的数量可以在数量级之间变化,预测将产生多少是困难的。
第一个挑战可以通过分离计算和临时存储(未来的工作)来解决。由于预测是困难的,因此还需要短期储存层的细粒度弹性。
可用于缓存的临时存储量远小于典型客户的总体持久性数据量—缓存平均只能容纳0.1%的持久性数据。然而,访问模式意味着可以实现接近80%的只读查询命中率和60%的读写查询命中率。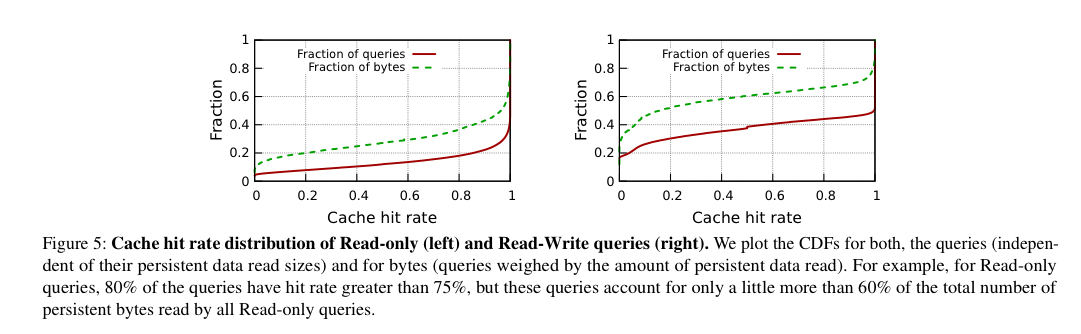
由于端到端查询性能取决于持久数据文件的缓存命中率和中间数据的I/O吞吐量,因此优化临时存储系统如何在两者之间分配容量是很重要的。尽管我们目前使用的简单策略是始终对中间数据进行优先级排序,但对于端到端性能目标而言,它可能不是最佳策略。
弹性
**
持久的存储弹性由底层存储提供(例如AWS上的S3)。虚拟仓库由一组计算节点组成,通过按需添加或移除节点来实现计算弹性。通过使用预先预热的节点池,可以在几十秒的粒度上提供计算弹性。考虑到Snowflake使用一致的散列(与工作窃取)将任务分配给它们需要访问的持久数据所在的节点,添加或删除节点可能需要对大量数据进行重新洗牌。Snowflake使用惰性的方法(延迟处理)做到了这一点:在重新配置之后,一致的散列可能会将任务发送到分区的新主节点,而该分区还没有该数据。此时,数据将从持久存储中读取并缓存。最终旧主节点中的数据也将从缓存中移出。
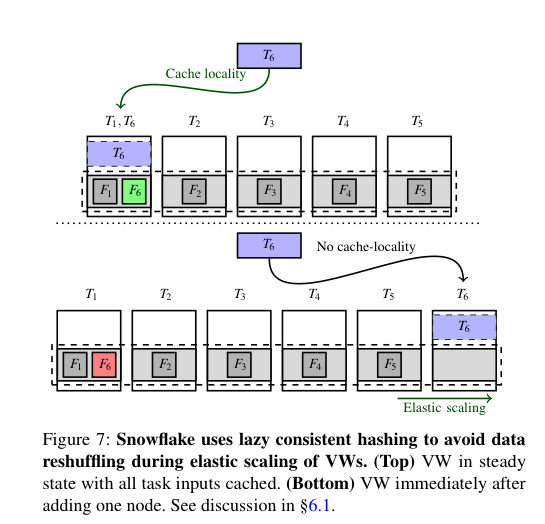
仓库扩展目前相当粗粒度,需要客户请求调整大小。查询间到达时间的变化比客户调整仓库的大小要频繁得多。超过80%的客户根本不要求调整仓库的大小。理想情况下,Snowflake支持在查询之间(这方面的工作正在进行)以及在执行单个查询期间(在查询的生命周期中,资源消耗可能会有很大的变化)进行自动缩放。
更进一步说,Snowflake希望探索无服务器平台的自动伸缩性、高弹性和细粒度计费。
但Snowflake向现有无服务器基础架构过渡的关键障碍是,它们在安全性和性能方面都缺乏对隔离的支持。
—其实单独沙箱化隔离可以做到这一点
firecracker报告诉我,事实并非如此,但它肯定需要一个分类的短期存储解决方案,这对我来说似乎是更大的挑战。
隔离
Snowdflake中的租户隔离处于虚拟仓库级别(每个客户都有自己的VW)。虚拟仓库实现了“相当好,但不理想,平均CPU利用率,但其他资源通常未充分利用的平均”—非公平分配原则的资源分配算法。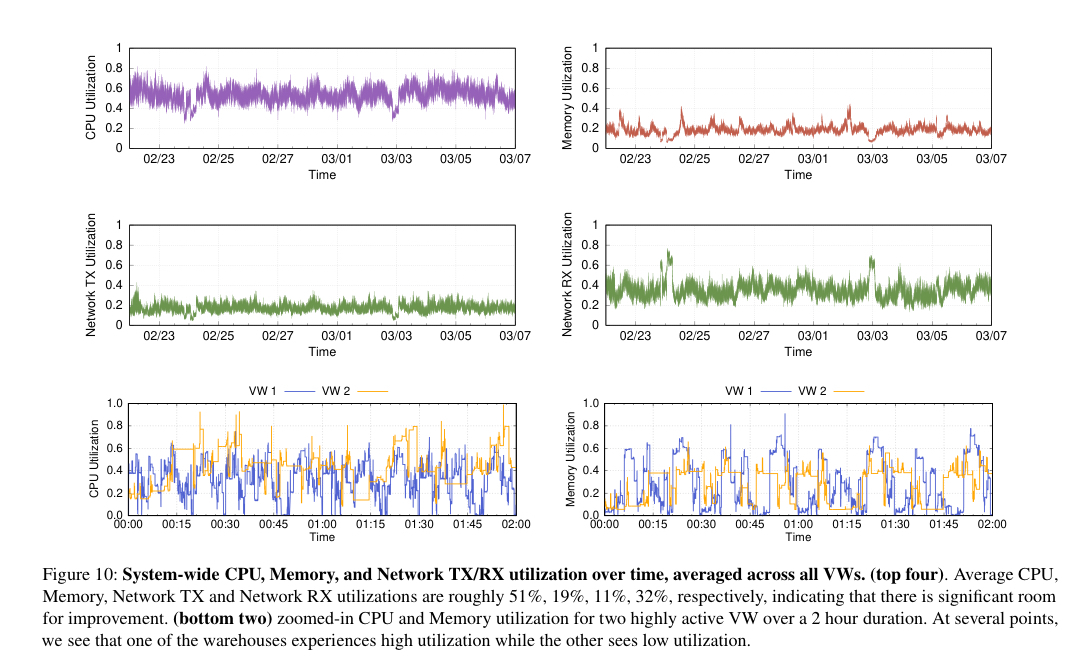
虽然我们在设计Snowflake时意识到这种性能隔离与利用率的权衡,但最近的趋势正促使我们重新审视这种设计选择。具体来说,当基础设施提供商过去按小时粒度收费时,维护一个预热实例池是经济高效的;然而,最近所有主要云基础设施提供商都采取了每秒定价的措施,这带来了有趣的挑战。
Snowflake希望降低运营成本,而客户也希望获得更精细的定价。”对于每秒计费,我们不能向任何特定客户收取预热节点上未使用周期的费用”。要跨越这座桥梁,Snowflake需要重新考虑隔离模型,在一组共享资源中复用客户需求。当然,这必须在保持强隔离性能的同时进行。需要隔离的两个关键资源是计算和临时存储。数据中心环境下的计算隔离已经得到了很好的研究,内存和存储隔离的研究较少。
对于临时存储,挑战在于公平地在租户之间共享缓存,并且能够在不影响其他租户的情况下扩展以满足一个租户的需求(例如,当前采用的延迟一致哈希方案将导致多个租户看到缓存未命中,而不仅仅是触发大小调整的缓存未命中)。FairRide被认为是一项潜在的相关工作。
内存问题既重要(VWs中的内存利用率目前很低,DRAM很昂贵),也很难解决。它既需要一个独立扩展的分类内存解决方案,也需要一个高效的机制在多个租户之间共享该分类内存。
记分卡
…Snowflake在多租户设置中实现了计算和存储弹性以及高性能。随着Snowflake的发展,它已经为成千上万的客户提供服务,每天都要对PB级的数据执行数以百万计的查询,我们认为自己至少取得了部分成功。然而,…我们的研究强调了我们当前设计和实施的一些缺点,并强调了更广泛的系统和网络社区可能感兴趣的新的研究挑战。

若有收获,就点个赞吧
0 人点赞
