在第一部分中,我们考察了数据危机,承认异常是不可避免的,并认识到应用程序的中心重要性。但我们该怎么办呢?在这里,我凝视着迷雾,思考着前进的道路,通过数据库研究社区为我们设置的路标导航。
应用程序数据存储映射
到目前为止,我们已经看到,我们所知道的最有效的方法需要在应用程序级别理解,而程序员需要在应用程序级别控制。这似乎是一个很好的起点。那会是什么状态?如果你想直接影响主流的话,一种新的编程语言是很有前途的。相反,我们将需要与程序员会面,并研究与主流应用程序开发语言(Java、C#、Python、JavaScript、Ruby等)协同工作的解决方案。因此,我们可以使用的工具是嵌入式dsl、注释、库和框架。Bloom的研究表明,你可以走多远。
逻辑起点是应用程序级不变量的表达式,其形式适合于I-合流分析,例如,通过注释。I-Confluence分析着眼于应用程序事务和正确性标准(不变量)的组合,因此我们还需要指定事务划分。如果你想改变行为,你需要做正确的事情去做最容易做的事情,所以必须密切注意让程序员变得简单自然。从I-Confluence分析(可以集成到开发工具链中——可能与注释预处理器等一起进入编译阶段——或者在应用程序初始化时使用内省调用)中,我们可以将结果分为三类:
- 不需要任何协调就可以维护的不变量。
- 在因果一致性和因果交易下可保持的不变量
- 除非使用强于因果一致性模型,否则无法保证的不变量。
第一类当然是最好的情况,并且已经产生了一些令人震惊的结果,工作负载与TPC-C基准一样传统。激进的并发控制论文还显示,除了一些应用程序完整性约束可能会在没有充分协调的情况下被破坏之外,在典型的Rails应用程序中使用的87%的验证注释可以在没有协调的情况下被维护。
对于第二类,那些确实需要一些协调的不变量,我的选择是采用因果一致性,因为它是云应用程序可用的最强的一致性。一个真正智能的框架可以优化这一点,只需使用足够的会话协调,从无到因果,根据手头的情况(基于I-Confluence分析结果)。有关会话保证的详细讨论,请参见高可用事务。程序员的模型应该是因果一致的。我们知道程序员很难处理较弱的一致性模型,因果一致性与人类的直觉和期望很好地吻合。如前所述,对于可伸缩性,这意味着我们的应用程序将需要提供明确的因果关系信息。简单的答案是让程序员在写操作中显式地指定因果依赖关系,但是也许还有一些声明性的方法可以让框架在不需要它的情况下推断出显式因果依赖关系。
如果我们有一个广泛的选择因果一致的生产准备后端数据存储从所有可能是好的。实际上,我们没有。如果你考虑到“真正智能的框架”优化,它可以选择弱于因果一致性,在适当的情况下,也许我们想要弱(最终)一致性在那一层的灵活性。在这里,关于固定一致性的工作看起来特别有希望,原因有三:(i)它表明可以在最终一致性存储的顶部放置因果一致性,(ii)它可以跨多个后端存储提供一致性,重要的是要满足应用程序程序员不想成为数据库的奴隶和通用解决方案所必需的愿望,并且(iii)它可以作为应用程序的一部分实现为嵌入式库。附加一致性文件考虑了关键值存储,“但我们的结果推广到更丰富的数据模型。”这里的一个挑战是,该机制依赖于客户端和底层数据存储之间的接口层。随着更丰富的数据模型出现更丰富的接口,这将引导我们返回到特定于存储的实现的道路上。一个特别有趣的问题是,连接一致性是否可以推广到一个完整的关系模型(SQL接口)。
我们必须承认,总会有第三类不变量——那些在ALPS系统中无法保持的不变量。我们希望I-合流分析的结果告诉我们这些是哪些,以便我们可以实现适当的事务回退。请注意,明确的因果依赖跟踪信息也可能有助于我们更好地道歉,因为它提供了一个洞察为什么会发生某些事情。
我们现在可以开始看到新一代数据框架的形状。我们需要能够指定应用程序不变量、事务和明确的因果依赖关系,并提供道歉回调。框架(ADM?–Application Datastore Mapper)集成到开发工具链中(或使用运行时内省),以便在不存在道歉回调时提供警告。在运行时,当不需要协调时,它将请求传递到底层的最终一致性存储,当需要协调时,它将锁定因果一致性。对于无法保证的应用程序完整性约束,它监视底层存储是否存在冲突,并在发生冲突时调用适当的回调来修复它们。假设道歉只需要在人类时间尺度上产生,那么希望违规检测开销能够合理。一个相关的打赌是,因果一致性的潜在危险可以通过结合明确的因果关系和只对实际需要它的不变量使用协调来减轻(而不是作为对所有事物的一揽子政策)。
结果可能是这样的: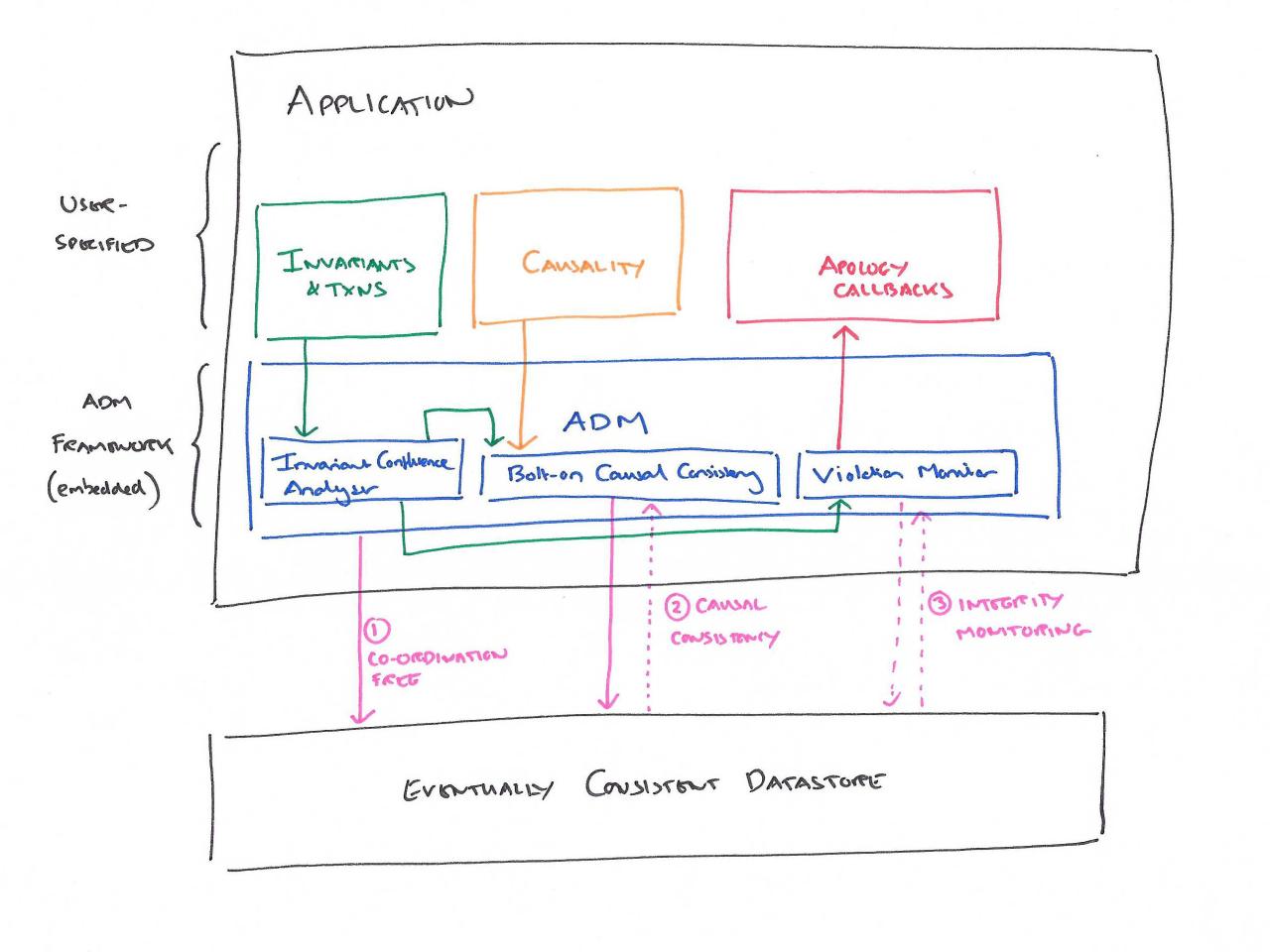
分布式数据类型(如CRDTs)自然地适合这个方案。如果应用程序能够利用它们,ADM应该认识到它们的完整性并不依赖于协调。其他的一切都有问题:我们使用它们的能力越强,所需的整体协调就越少,我们的系统将表现得越好。因此,当我们开发一个更丰富的分布式数据类型库并学习如何组合它们时,应用程序中crdt的自然增量采用是非常适合的。
有一个潜在的有趣的改进值得注意。对于不能用因果+一致性来保证的不变量,我们提供了一个保证,要么支持不变量(我们很幸运),要么调用适当的道歉回调。如果我们还知道应用程序SLO信息(服务级别目标),并且当前的情况使之成为可能(例如,我们当前没有分区,并发级别较低,延迟是可以接受的,…)那么没有什么可以阻止我们使用更高的协调来进一步减少违规行为(从而减少事务回滚的发生)。如果回滚机制给最终用户带来不便,这将是一件特别好的事情。我们可以把协调放在调光开关后面,保证最小的因果关系,但我们可以做得更好。
事务该如何处理?
**
COPS论文为因果一致的只读和只读事务提供了一个激励示例。本着在保留ALPS属性的同时尽可能给应用程序开发人员提供帮助的精神,我们希望支持此类事务。
SwiftCloud进一步描述了一个支持读写事务的“事务因果+一致性”模型:“每个事务读取一个因果一致的快照;事务的更新是原子的(全部或无)和隔离的(没有并发事务观察到中间状态);同时提交的更新不会冲突。”
在固定因果一致性Bailis等人。假设此类事务可以由一个具有高可用性的附加填充程序(因此在ADM框架中)提供。
分布式事务之外的存在状态对NoSQL数据库的设计产生了巨大的影响,并告诉我们,我们不希望事务跨越多个聚合实体,因为我们不能保证多个聚合实体将被放在一起,而分布式事务会扼杀可伸缩性。
近年来,许多“NoSQL”设计完全避免了跨分区事务,有效地提供了读未提交的隔离
(Bailis等人。:具有RAMP事务的可伸缩原子可见性)7年后,Bailis等人。向我们展示了使用名为Read Atomic的隔离模型可以实现可伸缩的多分区事务(RAMP事务)。这些可以帮助跨分区强制执行关联约束,原子地更新辅助索引,并确保物化视图保持一致。Warp还引入了一种建立在HyperDex之上的多密钥事务机制。
这是数据存储必须发挥作用的地方,我们不能把所有的重担都留给ADM。
我的头脑一直在纠结因果+事务和RAMP事务的交叉点。我还看不清楚,不能在这里多说。幸运的是,有比我聪明的人能做到!
如果有多个应用程序与同一个存储交互呢?
在数据存储之上实现的并发控制的问题是,即使您在应用程序中正确地实现了并发控制,只要多个应用程序与相同的底层数据交互,所有的下注都将再次关闭。(这感觉就像是在家里学到的一门课,在《周而复始》(What Goes Around Comes Around)中)。
到目前为止,我们讨论的I-Confluence分析着眼于应用程序的不变量,而只着眼于该应用程序的范围。看来我们有两个基本选择:
(a) 不要允许多个应用程序直接写入同一个数据库,而是创建一个对其完整性负责的服务,并在该服务中指定所有业务完整性约束。这个模型引导我们走向一个微服务风格的架构。(有趣的是,我们看到了一个从数据方向上的争论,而我们通常认为数据是走向微服务的障碍)。
(b) 将I-Confluence分析向下推到一个共享层(很可能是数据存储本身),在这里我们可以看到所有客户端应用程序。这让人想起今天的数据库约束机制,这些机制存在的理由很充分,但许多应用程序程序员都回避了这些机制。这允许“整个系统分析”(参见“整个程序分析”)。在应用程序部署速度不断提高的情况下,维护这种协调可能会变得很困难。
假设我们使用选项(a),即微服务拥有自己的数据(例如,在有界上下文中)。这让我们开始思考微服务之间的数据流…。

若有收获,就点个赞吧
0 人点赞
